
Text Analysis: Membandingkan Dua Topik Artikel dari Harvard Business Review
Pernah rekan saya bertanya seperti ini:
Setidaknya ada tiga tulisan terkait text analysis yang pernah saya buat, yakni:
- Komentar netizen pada webseries Sunyi.
- Keywords di tahun baru.
- Membaca artikel diabetes di detik.com.
Sekarang saya akan membuat sesuatu yang berbeda. Apa itu? Ada 2
analisa yang mau saya coba kali ini, yakni:
- Crosswords analysis dan
- Log odds ratio.
Tujuan dari 2 analisa itu adalah membandingkan dan menemukan kata-kata
yang menjadi pembeda antara 2 topik atau kategori data teks.
Sebagai contoh, saya akan menggunakan data
teks
berupa 14 artikel terbaru dari situs HBR yang saya
scrape pagi ini (30 September 2020 pukul 10.30 WIB). 14 artikel
tersebut terdiri dari 7 artikel dari kategori leadership dan 7
artikel dari kategori technology.
Pre Processing Data
Sebelum jauh melakukan analisa, ada beberapa langkah pre processing yang saya lakukan:
- Stemming: Yakni mengubah kata menjadi bentuk dasarnya di Bahasa
Inggris. Saya membuat function dari
library(hunspell). - Remove stopwords bahasa Inggris. Database stopwords saya ambil dari sini.
- Hapus tanda baca dan trim white space. Saya menggunakan
library(janitor).
Crosswords Analysis
Cara kerja analisa ini cenderung sangat mudah. Begini caranya:
- Buat tabulasi frekuensi dari kata-kata yang muncul dari
2kategori tersebut. - Pilih semua kata yang beririsan dari kategori A dan B.
- Buat scatterplot dari data tersebut
.
Jika ternyata kedua kategori ini sama, maka akan terlihat bahwa mayoritas kata-kata yang digunakan berkumpul di membentuk garis lurus.
Masih bingung? Ini saya berikan contohnya ya.
Saya mulai dengan menghitung frekuensi dari kata-kata yang muncul pada
kategori leadership, lalu saya buat wordcloud sebagai berikut:

Berikutnya adalah frekuensi dari kata-kata yang muncul pada kategori
technology :

Jika saya gabung kedua wordclouds tersebut, maka hasilnya seperti ini:
| Words | % Leadership | % Technology |
|---|---|---|
| employee | 3.85 | 1.21 |
| lead | 2.82 | 0.91 |
| people | 2.63 | 1.93 |
| time | 2.37 | 1.15 |
| manage | 2.31 | 1.27 |
| company | 2.12 | 2.60 |
| covid | 2.12 | 0.66 |
| team | 2.12 | 0.66 |
| support | 1.86 | 0.30 |
| pandemic | 1.73 | 0.84 |
| response | 1.73 | 0.18 |
| remote | 1.67 | 0.42 |
| 19 | 1.54 | 0.60 |
| meet | 1.48 | 0.24 |
| heal | 1.41 | 0.12 |
| organization | 1.41 | 0.60 |
| value | 1.41 | 0.18 |
| feel | 1.35 | 0.06 |
| office | 1.35 | 0.12 |
| busy | 1.28 | 1.69 |
Dari tabel di atas saya buat plot sebagai berikut:

Dari scatterplot di atas, kita bisa menghitung korelasi antara 2
kategori tersebut:
##
## Pearson's product-moment correlation
##
## data: data$leader and data$tech
## t = 9.5837, df = 662, p-value < 2.2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.2804146 0.4141413
## sample estimates:
## cor
## 0.3490537
Ternyata didapatkan korelasinya signifikan (tidak bisa diabaikan)
walaupun nilainya relatif lemah . Artinya kecenderungan kata yang sama dipakai di kedua
kategori artikel relatif kecil.
Kedua artikel ini menggunakan kata-kata yang berbeda. Akibatnya topik bahasan juga benar-benar berbeda.
Log Odds Ratio
Log Odds
Ratio
adalah kelanjutan dari crosswords analysis. Frekuensi kata dari 2
kelompok akan dihitung nilai logratio-nya dengan rumus:
Angka tersebut akan menunjukkan kata mana yang less or most likely come from each group. Berikut adalah bentuk plot yang dijadikan standar perhitungan pada log odds ratio:
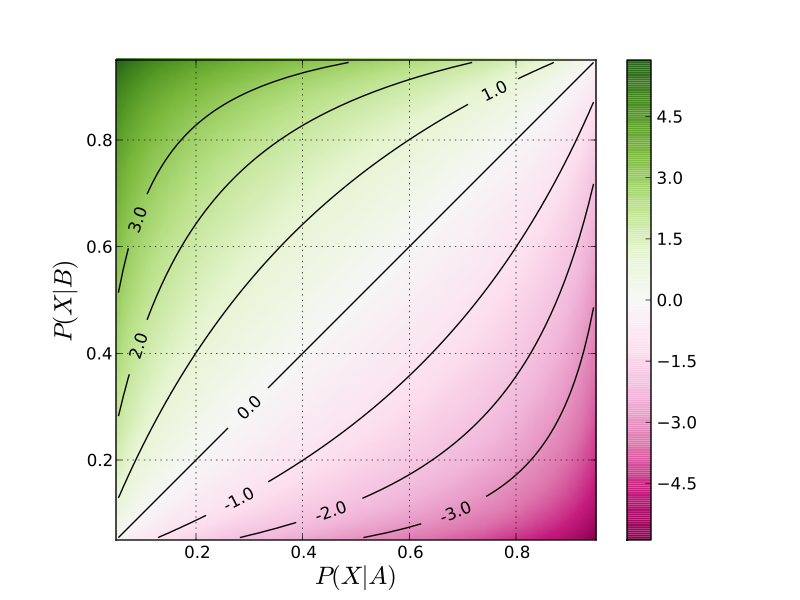
Dari plot di atas terlihat bahwa jika ada kata yang memiliki nilai
artinya kata tersebut dipakai oleh kedua kategori artikel
dengan frekuensi yang sama. Selain itu, maka kata-kata lebih sering
dipakai di salah satu kategori artikel saja.
Berikut adalah bentuk finalnya:
Sekarang kelihatan deh kata-kata mana saja yang sering keluar di
leadership dan technology.