
Mencari Strategi Terbaik untuk Mengambil Keputusan dengan The Secretary Problem
Pada lebaran kemarin, saya pergi ke mall di sore harinya untuk mencari tempat makan untuk saya dan keluarga. Saat masuk ke basement parkiran, saya melihat satu slot kosong di dekat pintu masuk. Saya berpikir:
“Mungkin masih ada yang lebih dekat ke pintu masuk.”
Saya terus melaju dan ternyata tidak ada slot kosong. Akhirnya saya kembali ke slot yang pertama kali saya lihat dan alhamdulillah masih ada.
Di bulan lalu, perusahaan saya membuka vacancy untuk posisi management trainee. Kebetulan saya dan beberapa rekan mendapatkan kesempatan untuk mewawancarai beberapa kandidat yang diproyeksikan bisa di-assign ke tim market riset. Kandidat pertama bagus, kandidat kedua juga oke, kandidat berikutnya juga bagus, berikutnya juga bagus banget. Saya dan rekan-rekan belum yakin apakah harus langsung pilih yang sudah ada atau terus mencari.
Bisa jadi terlalu cepat memilih mengakibatkan kami menyesal karena mungkin ada kandidat setelahnya yang lebih baik. TAPI terlalu lama mencari bisa mengakibatkan kami membuang waktu dan bisa kehilangan kandidat bagus yang sudah lewat.
Kedua contoh dilema ini sebenarnya adalah satu problem matematika yang sudah punya jawaban optimal. Dan jawabannya mengandung angka yang mengejutkan:
37% atau lebih tepatnya 1/e ≈ 0.3679.
Ini adalah proporsi optimal untuk fase ‘hanya observasi’ sebelum Anda mulai membuat keputusan. Aturan ini berlaku di banyak situasi kehidupan nyata yang punya struktur serupa. Bagaimana penjelasannya? Simak paparan berikut ini ya.
Apa itu Aturan 37%
Asal usul the Secretary Problem
Aturan 37% berasal dari sebuah problem klasik matematika yang dikenal dengan beberapa nama: Secretary Problem, Marriage Problem, atau Optimal Stopping Problem. Problem ini pertama kali dipublikasikan secara luas pada tahun 1960 oleh Martin Gardner di kolom Mathematical Games-nya di Scientific American.
Ini adalah formulasi awalnya: kita ingin merekrut satu sekretaris terbaik dari N kandidat. Kandidat datang satu per satu dalam urutan acak. Setelah mewawancarai setiap kandidat, Anda harus langsung memutuskan: terima atau tolak. Kandidat yang ditolak tidak bisa dipanggil kembali.
Bagaimana strategi optimal untuk memaksimalkan probabilitas mendapat kandidat terbaik?
Ternyata, jawaban matematisnya adalah strategi dua fase yang sangat elegan:
- Fase Eksplorasi: Amati (dan tolak) 37% kandidat pertama. Catat siapa yang terbaik sejauh ini. List kandidat ini jadi patokan kita.
- Fase Eksploitasi: Mulai dari kandidat ke-38%, terima kandidat PERTAMA yang lebih baik dari patokan tadi.
Dengan strategi ini, probabilitas Anda mendapat kandidat terbaik secara keseluruhan adalah tepat 1/e ≈ 37%. Menariknya, ini adalah probabilitas tertinggi yang bisa dicapai — tidak ada strategi lain yang bisa mengalahkannya.
Mengapa 1/e ?
Angka 1/e muncul dari kalkulus optimasi. Ketika N cukup besar, batas optimal r/N (di mana r adalah jumlah kandidat yang diobservasi dulu) konvergen ke 1/e.
Asumsi yang Perlu Dipahami
Sebelum lanjut ke simulasi di R, penting untuk memahami asumsi di balik aturan ini agar kita tidak salah aplikasikan:
| Asumsi | Artinya | Contoh Real |
|---|---|---|
| Urutan acak | Kandidat datang dalam urutan yang tidak bisa diprediksi | CV yang masuk tidak diurutkan dari yang terbaik duluan |
| Keputusan seketika | Setelah menolak, tidak bisa memanggil kembali | Kandidat yang ditolak langsung ambil tawaran lain |
| N diketahui | Jumlah total kandidat sudah diketahui sebelumnya | Anda tahu ada tepat 20 pelamar |
| Bisa membandingkan | Anda bisa meranking kandidat secara relatif | Anda bisa bilang ‘kandidat ini lebih baik dari kandidat yang sebelumnya’ |
| Satu pilihan | Hanya memilih satu dari N | Satu posisi yang tersedia, satu apartemen yang disewa |
Di dunia nyata, asumsi-asumsi ini jarang terpenuhi sempurna. Tapi aturan 37% tetap berguna sebagai panduan heuristik mengambil keputusan yang masuk akal meski tidak optimal secara persis.
Pembuktian dengan Simulasi di R
Agar lebih jelas lagi, maka saya akan buatkan satu simulasi untuk memperlihatkan bahwa aturan 37% adalah strategi pengambilan keputusan terbaik.
Saya akan menggunakan beberapa study cases sebagai bahan simulasi.
KASUS I: Simulasi Wawancara Kandidat
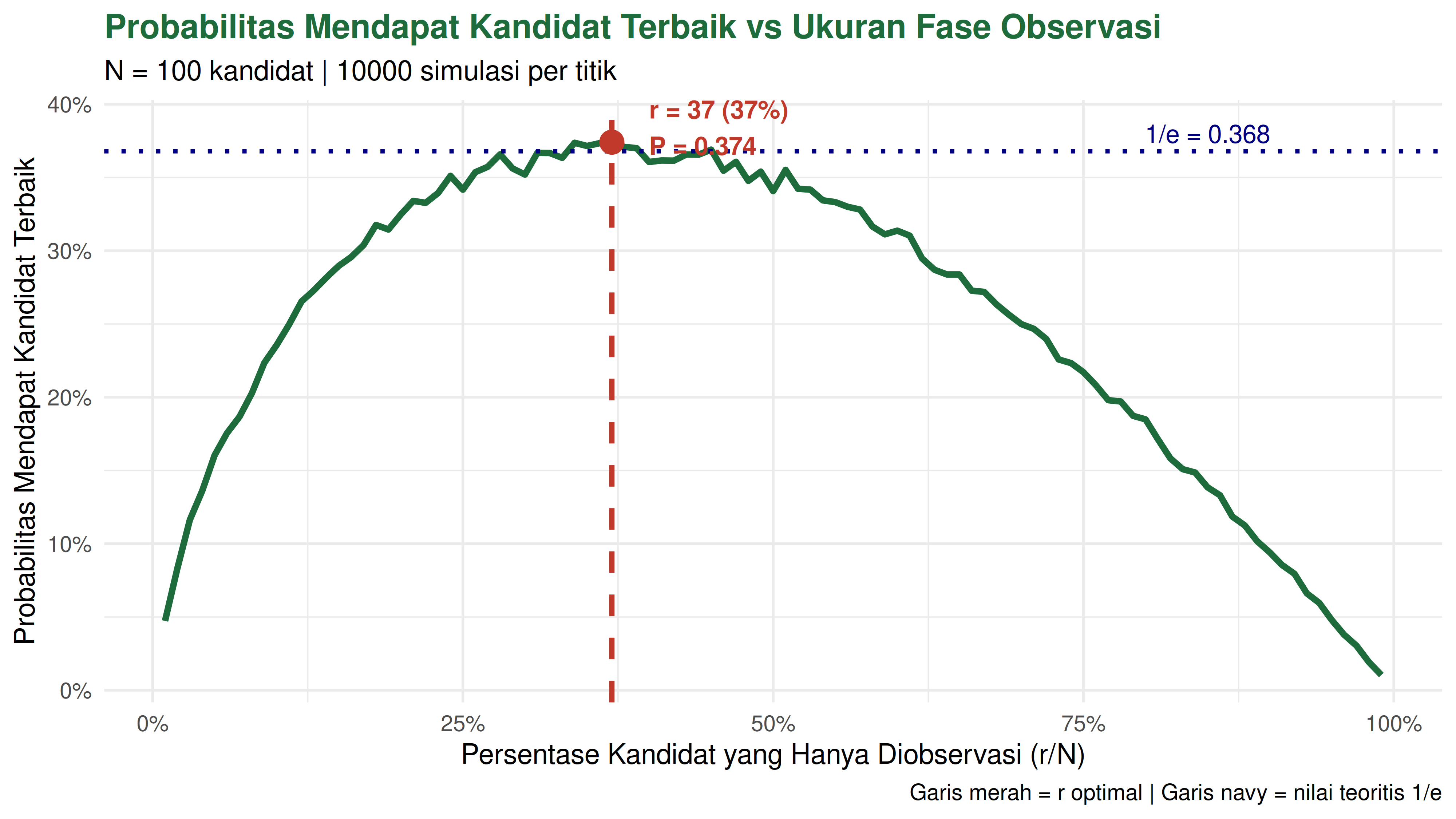
Bayangkan kita harus memilih 1 orang terbaik dari 100 pelamar. Pelamar datang satu per satu. Kita simulasikan 10.000 kali (prinsip Monte Carlo) dengan berbagai nilai r (berapa yang diobservasi dulu) dan lihat berapa probabilitas mendapat kandidat terbaik.
Pertama-tama, saya akan membuat beberapa function berikut ini:
Sekarang saya akan mulai simulasinya dengan flow sebagai berikut:
- Saya akan buat 100 orang kandidat.
- Saya akan definisikan r tertentu, mulai dari 1 hingga 99.
- Misalkan r = 10, artinya saya akan mewawancarai 10 orang kandidat pertama. Lalu kandidat terbaik dari 10 orang tersebut akan saya jadikan basis.
- Kemudian saya akan mewawancarai kandidat ke 11, jika kandidat tersebut lebih baik dari basis, maka saya akan hire kandidat tersebut.
- Jika kandidat ke 11 tidak lebih baik dari basis, saya akan wawancarai kandidat selanjutnya. Kandidat dengan kualitas lebih baik dari basis akan langsung saya hire.
Proses ini akan diulang-ulang dengan berbagai nilai r sebanyak 10 ribu kali.
# ── Simulasi untuk berbagai nilai r ──────────────────────────────
N <- 100 # Jumlah kandidat
n_sim <- 10000 # Jumlah simulasi per nilai r
r_values <- 1:(N-1) # Coba semua kemungkinan r
# Untuk setiap nilai r, hitung probabilitas dapat kandidat terbaik
hasil_sim <- sapply(r_values, function(r) {
sukses <- replicate(n_sim, {
# Buat urutan acak: nilai kandidat dari distribusi uniform
kandidat <- runif(N)
# Jalankan strategi
pilihan <- optimal_stopping(kandidat, r)
# Apakah yang dipilih adalah yang terbaik?
dapat_terbaik(kandidat, pilihan)
})
mean(sukses) # Proporsi sukses = probabilitas estimasi
})
df_hasil <- data.frame(
r = r_values,
pct_r = r_values / N * 100,
prob_sukses = hasil_sim
)
# Temukan r optimal dari simulasi
r_optimal_sim <- df_hasil$r[which.max(df_hasil$prob_sukses)]
prob_optimal <- max(df_hasil$prob_sukses)
Berikut hasilnya:
r optimal (simulasi) : 37 dari 100 kandidat
Persentase : 37 %
Probabilitas sukses : 0.3741
Nilai teoritis 1/e : 0.3679
Hasil simulasi memberikan informasi bahwa pada r = 37, kita mendapatkan peluang tertinggi (sebesar 37%) bahwa kandidat selanjutnya adalah kandidat terbaik compared to kandidat terbaik dari 37 yang dijadikan basis.
KASUS II: Simulasi Pencarian Apartemen
Misalkan Anda pindah kerja ke Dubai dan harus menyewa apartemen. Ada 20 unit yang sudah masuk shortlist dan bisa dilihat satu per satu. Begitu Anda menolak satu unit, Anda tidak bisa kembali (unit tersebut sudah diambil orang lain). Kapan Anda harus mulai memutuskan? Berdasarkan aturan 37%, maka:
Banyaknya apartemen yang harus dilihat dulu tanpa dipilih sama sekali adalah: (20 × 0.37) ~ 8 unit. Maka setelah melihat 8 unit pertama, catat unit apartemen terbaik sejauh ini. Mulai dari unit ke-9, pilih unit PERTAMA yang lebih baik dari 8 unit tadi.
Saya juga akan bandingkan saat:
- Anda terburu-buru mengambil keputusan dengan r = 2. Lihat 2 unit apartemen, lalu langsung memilih.
- Anda terlalu lama mengambil keputusan dengan r = 15. Lihat 15 unit apartemen, lalu langsung memilih.
Oke, sekarang saya buat skrip simulasinya:
# ── Kasus 2: Mencari Apartemen ────────────────────────────────────
# Simulasi: 20 apartemen, nilai kualitas dari 1-100
simulasi_apartemen <- function(n_apartemen = 20, n_sim = 50000) {
r_optimal <- ceiling(n_apartemen / exp(1))
# Bandingkan tiga strategi:
# 1. Aturan 37% (r = ceiling(N/e))
# 2. Terlalu cepat (r = 2, hanya lihat 2 dulu)
# 3. Terlalu lama (r = 15, lihat 15 dulu baru pilih)
hasil <- replicate(n_sim, {
apt <- sample(1:n_apartemen, n_apartemen) # Urutan acak
pilih_37 <- optimal_stopping(apt, r_optimal)
pilih_awal <- optimal_stopping(apt, 2)
pilih_lama <- optimal_stopping(apt, 15)
c(
terbaik_37 = apt[pilih_37] == max(apt),
terbaik_awal = apt[pilih_awal] == max(apt),
terbaik_lama = apt[pilih_lama] == max(apt),
rank_37 = rank(-apt)[pilih_37], # Rank 1 = terbaik
rank_awal = rank(-apt)[pilih_awal],
rank_lama = rank(-apt)[pilih_lama]
)
})
data.frame(
strategi = c('Aturan 37% (r=7)',
'Terlalu Cepat (r=2)',
'Terlalu Lama (r=15)'),
prob_terbaik = c(mean(hasil['terbaik_37',]),
mean(hasil['terbaik_awal',]),
mean(hasil['terbaik_lama',])),
rata_rank = c(mean(hasil['rank_37',]),
mean(hasil['rank_awal',]),
mean(hasil['rank_lama',]))
)
}
set.seed(101)
hasil_apt <- simulasi_apartemen()
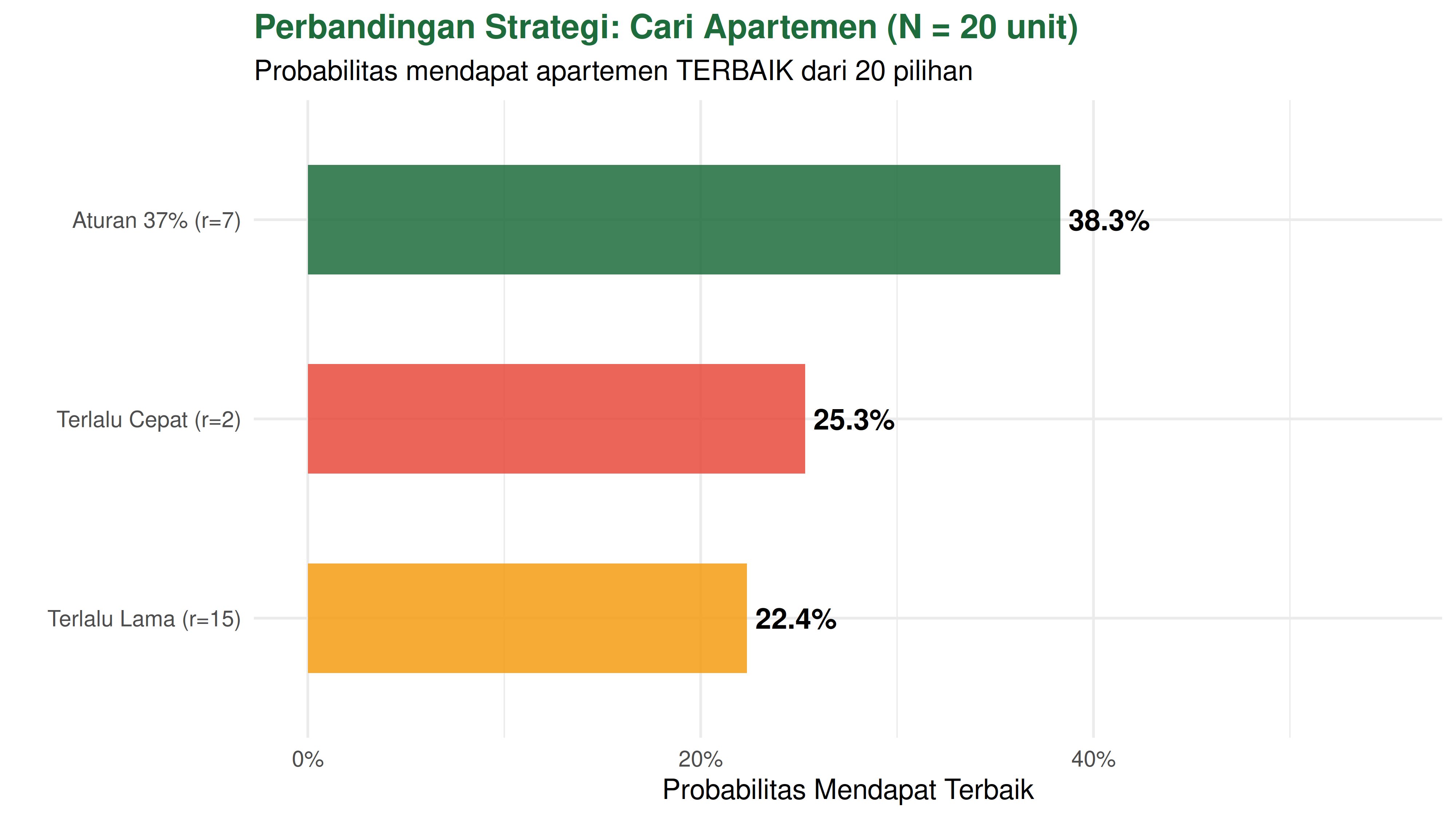
=== SIMULASI CARI APARTEMEN (N=20) ===
strategi prob_terbaik rata_rank
1 Aturan 37% (r=7) 38.3% 5.36
2 Terlalu Cepat (r=2) 25.3% 4.54
3 Terlalu Lama (r=15) 22.4% 8.53
Aturan 37% memberikan peluang terbaik kita akan mendapatkan unit terbaik dari 20 unit yang ada di shortlist.
KASUS III: Simulasi Pencarian Vendor
Tim procurement sedang memilih vendor untuk proyek IT senilai Rp 2 miliar. Ada 15 vendor yang sudah diundang untuk mengajukan penawaran. Penawaran datang satu per satu. Mereka ingin memilih vendor dengan harga dan kualitas terbaik, tapi vendor yang sudah ditolak tidak bisa diajak kembali ke meja negosiasi. Bagaimana cara terbaik memilihnya? Dengan aturan 37%:
r sebesar (15 × 0.37) = 6 vendor. Evaluasi 6 penawaran pertama, tolak semua (tapi catat yang terbaik sebagai benchmark / basis). Mulai dari penawaran ke-7, pilih penawaran pertama yang lebih baik dari basis tersebut.
Pada simulasi ini, saya berikan juga nilai random masing-masing vendor untuk kemudian saya bandingkan juga strategi pemilihan jika terburu-buru atau terlalu lama:
# ── Kasus 3: Seleksi Vendor ───────────────────────────────────────
# Dalam seleksi vendor, 'nilai' adalah kombinasi harga dan kualitas
# Kita simulasikan nilai gabungan (semakin tinggi semakin baik)
simulasi_vendor <- function(n_vendor = 15, n_sim = 50000) {
r_37 <- ceiling(n_vendor / exp(1))
hasil <- replicate(n_sim, {
# Setiap vendor punya nilai gabungan harga-kualitas
nilai_vendor <- runif(n_vendor, 50, 100)
pilihan_37 <- optimal_stopping(nilai_vendor, r_37)
pilihan_awal <- optimal_stopping(nilai_vendor, 1)
pilihan_lama <- optimal_stopping(nilai_vendor, 12)
# Hitung nilai (skor) vendor yang dipilih
c(
nilai_37 = nilai_vendor[pilihan_37],
nilai_awal = nilai_vendor[pilihan_awal],
nilai_lama = nilai_vendor[pilihan_lama],
terbaik_37 = nilai_vendor[pilihan_37] == max(nilai_vendor)
)
})
data.frame(
strategi = c('Aturan 37% (r=6)', 'Terlalu Cepat (r=1)', 'Terlalu Lama (r=12)'),
rata_nilai = c(mean(hasil['nilai_37',]),
mean(hasil['nilai_awal',]),
mean(hasil['nilai_lama',])),
prob_terbaik = c(mean(hasil['terbaik_37',]), "-", "-")
)
}
set.seed(101)
hasil_vendor <- simulasi_vendor()
=== SIMULASI SELEKSI VENDOR (N=15) ===
strategi rata_nilai prob_terbaik
1 Aturan 37% (r=6) 86.43 0.38898
2 Terlalu Cepat (r=1) 85.82 -
3 Terlalu Lama (r=12) 78.12 -
Ternyata didapatkan bahwa aturan 37% memberikan peluang terbaik bagi tim procurement untuk menemukan vendor dengan expected nilai kualitas dan harga tertinggi.
Berapa Nilai r untuk N yang Berbeda-beda?
Salah satu pertanyaan yang selalu muncul adalah jika N saya bukan 100 tapi hanya 10 atau 20, apakah masih pakai 37%?
Jawaban singkatnya: ya karena prinsipnya sama.
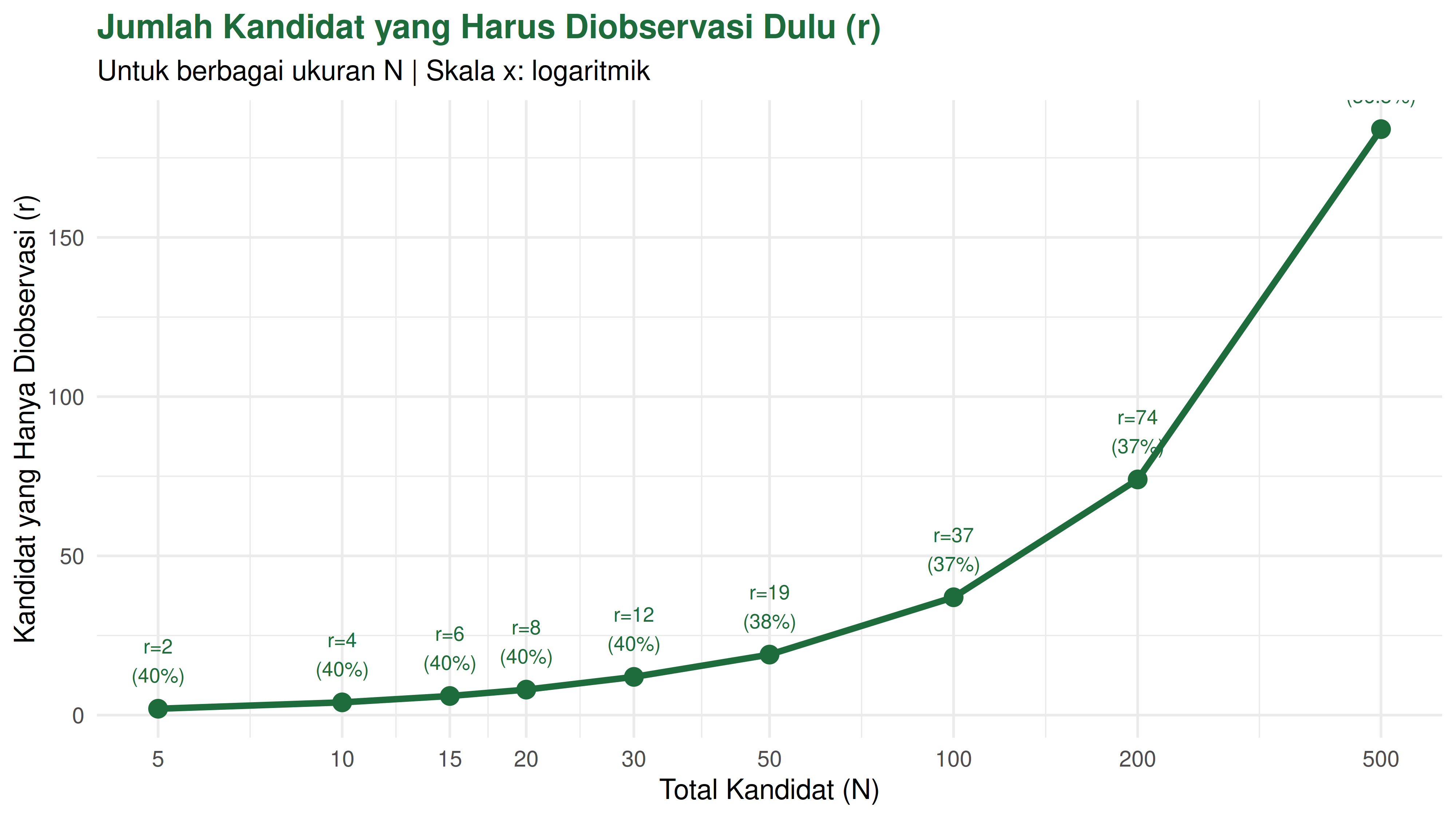
TAPI untuk N kecil, tentu ada penyesuaian karena bilangan bulat tidak bisa mewakili 37% secara persis. Berikut tabel referensi yang bisa digunakan:
N r_teoritis r_praktis pct_r sisa_pilih
1 5 1.839397 2 40.0 3
2 10 3.678794 4 40.0 6
3 15 5.518192 6 40.0 9
4 20 7.357589 8 40.0 12
5 30 11.036383 12 40.0 18
6 50 18.393972 19 38.0 31
7 100 36.787944 37 37.0 63
8 200 73.575888 74 37.0 126
9 500 183.939721 184 36.8 316
Bagaimana Jika Nilai N Tidak Diketahui?
Asumsi terberat dari aturan 37% adalah kita harus tahu N di awal. Tapi di kehidupan nyata, seringkali kita tidak tahu berapa banyak total pilihan yang tersedia. Misalnya: berapa lama Anda harus mencari pasangan hidup sebelum memutuskan untuk berkomitmen? Anda tidak tahu akan bertemu berapa orang sepanjang hidup Anda.
Untuk kasus ini, ada ekstensi aturan 37% yang menggunakan waktu sebagai pengganti jumlah N. Bagaimana caranya? Prinsipnya seperti ini:
Kalau Anda berencana mencari selama T tahun (atau bulan, atau hari), habiskan 37% waktu pertama hanya untuk mengobservasi dan membandingkan. Setelah itu, pilih opsi pertama yang lebih baik dari semua yang sudah Anda lihat.
Misalkan jika kita berencana mencari karyawan selama 3 bulan, gunakan 5-6 minggu pertama hanya untuk wawancara tanpa menerima siapapun.
Berikut adalah skrip untuk men-simulasikan hal tersebut:
Misalkan kita memiliki waktu pencarian kandidat karyawan selama 12 bulan.
# ── Simulasi: ketika N tidak diketahui (pakai batas waktu) ───────
# Asumsi: kandidat datang dengan laju Poisson,
# kita punya waktu T satuan, dan kandidat datang rata-rata lambda per satuan
simulasi_waktu <- function(T_total = 12, # 12 bulan
lambda = 4, # rata-rata 4 kandidat/bulan
n_sim = 30000) {
t_37 <- T_total / exp(1) # 37% dari total waktu
hasil <- replicate(n_sim, {
# Simulasi waktu kedatangan kandidat (Poisson process)
n_total <- rpois(1, lambda * T_total)
if (n_total < 2) return(c(sukses_37=FALSE, sukses_50=FALSE))
waktu_datang <- sort(runif(n_total, 0, T_total))
nilai <- runif(n_total) # Kualitas kandidat
# Strategi 37% waktu
observasi_37 <- waktu_datang <= t_37
if (sum(observasi_37) == 0) return(c(sukses_37=FALSE, sukses_50=FALSE))
patokan_37 <- max(nilai[observasi_37])
kandidat_eksploitasi <- which(!observasi_37)
pilih_37 <- n_total # default: kandidat terakhir
for (i in kandidat_eksploitasi) {
if (nilai[i] > patokan_37) { pilih_37 <- i; break }
}
# Strategi 50% waktu (untuk perbandingan)
observasi_50 <- waktu_datang <= T_total * 0.5
if (sum(observasi_50) == 0) return(c(sukses_37=FALSE, sukses_50=FALSE))
patokan_50 <- max(nilai[observasi_50])
kandidat_eks50 <- which(!observasi_50)
pilih_50 <- n_total
for (i in kandidat_eks50) {
if (nilai[i] > patokan_50) { pilih_50 <- i; break }
}
c(
sukses_37 = nilai[pilih_37] == max(nilai),
sukses_50 = nilai[pilih_50] == max(nilai)
)
})
data.frame(
strategi = c('37% waktu (t = 4.4 bln)', '50% waktu (t = 6 bln)'),
prob_sukses = c(mean(hasil['sukses_37',]),
mean(hasil['sukses_50',]))
)
}
set.seed(101)
hasil_waktu <- simulasi_waktu()
=== SIMULASI BERBASIS WAKTU (T=12 bln, lambda=4/bln) ===
strategi prob_sukses
1 37% waktu (t = 4.4 bln) 36.5%
2 50% waktu (t = 6 bln) 34.7%
Dengan memanfaatkan aturan 37%, kita cukup menunggu selama 4.4 bulan untuk mendapatkan kandidat terbaik dengan expected probabilitas tertinggi dibandingkan dengan strategi lainnya.
Epilog: Kapan Aturan Ini Tidak Cocok Dipakai?
Dari banyak penjelasan di atas, aturan 37% bukan resep ajaib. Tapi ia mengajarkan sesuatu yang sangat berharga, yakni ada trade-off mendasar antara mengumpulkan informasi dan mengambil tindakan.
- Terlalu sedikit informasi — keputusan jadi serampangan.
- Terlalu banyak menunggu — kesempatan berlalu.
Hal yang menarik adalah matematika menunjukkan bahwa trade-off ini punya titik optimal yang secara mengejutkan konsisten di berbagai ukuran N. Yakni selalu sekitar 37% pertama hanya untuk mengamati, lalu bertindak.
Namun, perlu diingat kembali bahwa aturan 37% ini punya asumsi dan limitasi sehingga tidak cocok digunakan saat kondisinya:
- Ketika Anda bisa kembali ke pilihan sebelumnya. Kalau Anda masih bisa menelepon kembali kandidat yang sudah ‘ditolak’, aturan ini tidak diperlukan. Masalah optimal stopping hanya relevan ketika keputusan benar-benar irreversible.
- Ketika N sangat kecil (N < 5). Dengan 3-4 pilihan saja, 37% dari N hanya 1 kandidat. Fase observasi dari 1 orang terlalu sedikit untuk jadi patokan yang berarti. Lebih baik evaluasi semua, lalu pilih.
- Ketika kualitas kandidat tidak independen. Kalau kandidat yang datang belakangan cenderung lebih baik (misalnya CV yang masuk setelah deadline perpanjangan), asumsi urutan acak dilanggar dan aturan 37% bisa menyesatkan.
- Ketika ada informasi prior yang kuat. Kalau Anda sudah tahu distribusi kualitas kandidat (misalnya: ‘dari 50 pelamar, biasanya ada 3-5 yang sangat bagus’), pendekatan Bayesian bisa menghasilkan strategi yang lebih baik dari aturan 37% murni.
- Ketika biaya observasi tinggi. Kalau setiap wawancara butuh 3 jam persiapan, ‘buang’ 37% kandidat hanya untuk observasi bisa sangat mahal. Dalam kasus ini, r optimal mungkin lebih kecil dari 37%.
if you find this article helpful, support this blog by clicking the ads.