
Text Clustering dengan R: Case Study Komentar Netizen Terhadap Produk Susu Oat
Ternyata setelah saya lihat kembali blog saya ini, sudah lama saya tidak menuliskan tentang text analysis. Semua tulisan saya terkait text analysis bisa dibaca di link berikut ini.
Nah, kali ini saya akan mencoba satu hal baru yang sebenarnya sudah lama dipendam yakni text clustering dengan metode clustering yang sudah saya bahas di tulisan ini.
Ya betul, saya akan mengaplikasikan metode clustering pada data berupa teks!
Jadi, metode clustering atau pengelompokkan juga bisa diaplikasikan menggunakan teknik unsupervised learning ini. Tujuannya jelas, yakni: mengelompokan data teks menjadi beberapa kelompok yang homogen.
Buat rekan-rekan yang sudah terbiasa melakukan text analysis, biasanya untuk melakukan pengelompokan data teks, analisa yang digunakan adalah LDA (Latent Dirichlet Allocation). Saya pernah menggunakannya untuk mengelompokan komen-komen netizen pada suatu web series di Youtube.
Berbeda dengan LDA, prinsip yang digunakan saat ini adalah clustering yang menurut saya lebih intuitif dan mudah untuk diikuti.
Saya mulai yah.
Data yang saya gunakan adalah data review para konsumen Tropicana Slim Oat Drink yang saya dapatkan dari situs Hometester Club Indonesia. Oh iya, kenapa saya penasaran melakukan analisa untuk produk ini? Karena menurut saya produk ini menawarkan alternatif minuman susu vegan yang sehat dengan rasa yang pas. Kalau tidak percaya, silakan dicoba yah.
Dulu, saya pernah juga menganalisa review produk-produk lain dari situs tersebut.
Saya mendapatkan 45 buah reviews. Berikut adalah sampel
review-nya:
| komen | resp_id |
|---|---|
| Rasanya kurang berasa oatnya,lebih ke hambar bgt sih.. | 1 |
| enakkk bangett, manisnya pas menurut aku. tipikal kaya oatmilk pada umumnya tapi rasa vanilla dan lumayan bikin kenyang. | 2 |
| Produk sangat baik kualitas terjamin dan lembut waktu di buat bikin kue sangat memuaskan produk ini dan selalu di buat buat usaha jualan apa buat di jual di warung2 hargga yerjamin dan murah | 3 |
| Sesuai dengan labelnya less sugar, rasanya tidak terlalu manis jadi tidak bikin eneg, rasa susunya terasa dan bikin kenyang. Semoga ada varian rasa lainnya ya | 4 |
| Bikin kenyang cocok untuk diet | |
| Rasanya enak, g bikin eneg | 5 |
| Manisnya pas ga bikin eneg,cocok buat yang ga sempet sarapan ga bikin sakit perut juga.buat yang lagi diet tapi pengen minum susu bisa dialihkan minum ini. Recommend buat yang mau diet dan ga sempat bikin sarapan | 6 |
Workflow Analisis
Dari data di atas, saya tidak bisa langsung melakukan clustering karena data teks-nya masih sangat kotor. Setidaknya, saya harus melakukan beberapa pre-processing sebagai berikut:
- Mentransformasi semua uppercase menjadi lowercase.
- Membuang semua punctuation.
- Membuang semua stopwords dan kata-kata tak bermakna.
Untuk melakukan ketiga proses di atas, saya menggunakan
library(tidytext) dari tidyverse. Sementara daftar stopwords saya
himpun dari rekapan Github
User
yang saya enrich dari data yang dihimpun. Cara enrich-nya adalah
dengan membuat bigrams, lalu mendeteksi secara manual kata mana saja
yang perlu dibuang.
Kenapa harus bigrams? Kenapa bukan wordcloud?
Bagi saya, bigrams menawarkan konteks dibanding kata semata. Maka harusnya saya bisa memilih kata-kata mana saja yang benar-benar tak bermakna untuk dibuang.
Tahap Pengerjaan I
Sekarang saya akan buat langkah 1-3 serta bigrams sebagai berikut:
# kita ambil stopwords
stop = readLines("https://raw.githubusercontent.com/ikanx101/ID-Stopwords/master/id.stopwords.02.01.2016.txt")
# kita lakukan langkah 1-2
df =
df |>
# lowercase
mutate(komen = tolower(komen),
komen = stringr::str_trim(komen)) |>
# remove punctuation
mutate(komen = gsub("[[:punct:]]|\\n|\\r|\\t"," ",komen),
komen = stringr::str_trim(komen)) |>
unnest_tokens("words",komen) |>
# remove stopwords
filter(!words %in% stop)
# mengembalikan ke bentuk awal
raw =
df |>
group_by(resp_id) |>
summarise(komen = paste(words,collapse = " ")) |>
ungroup()
# kita buat grafik bigram dulu
bigram_plot =
raw |>
unnest_tokens("bigrams",komen,token = "ngrams",n = 2) |>
group_by(bigrams)|>
tally(sort = T) |>
ungroup() |>
head(50) |>
separate(bigrams,into = c("from","to"),sep = " ") %>%
graph_from_data_frame() %>%
ggraph(layout = 'fr') +
geom_edge_bend(aes(edge_alpha=n),
show.legend = F,
color='darkred') +
geom_node_point(size=1,color='steelblue') +
geom_node_text(aes(label=name),alpha=0.4,size=3,repel = T) +
theme_void()
bigram_plot
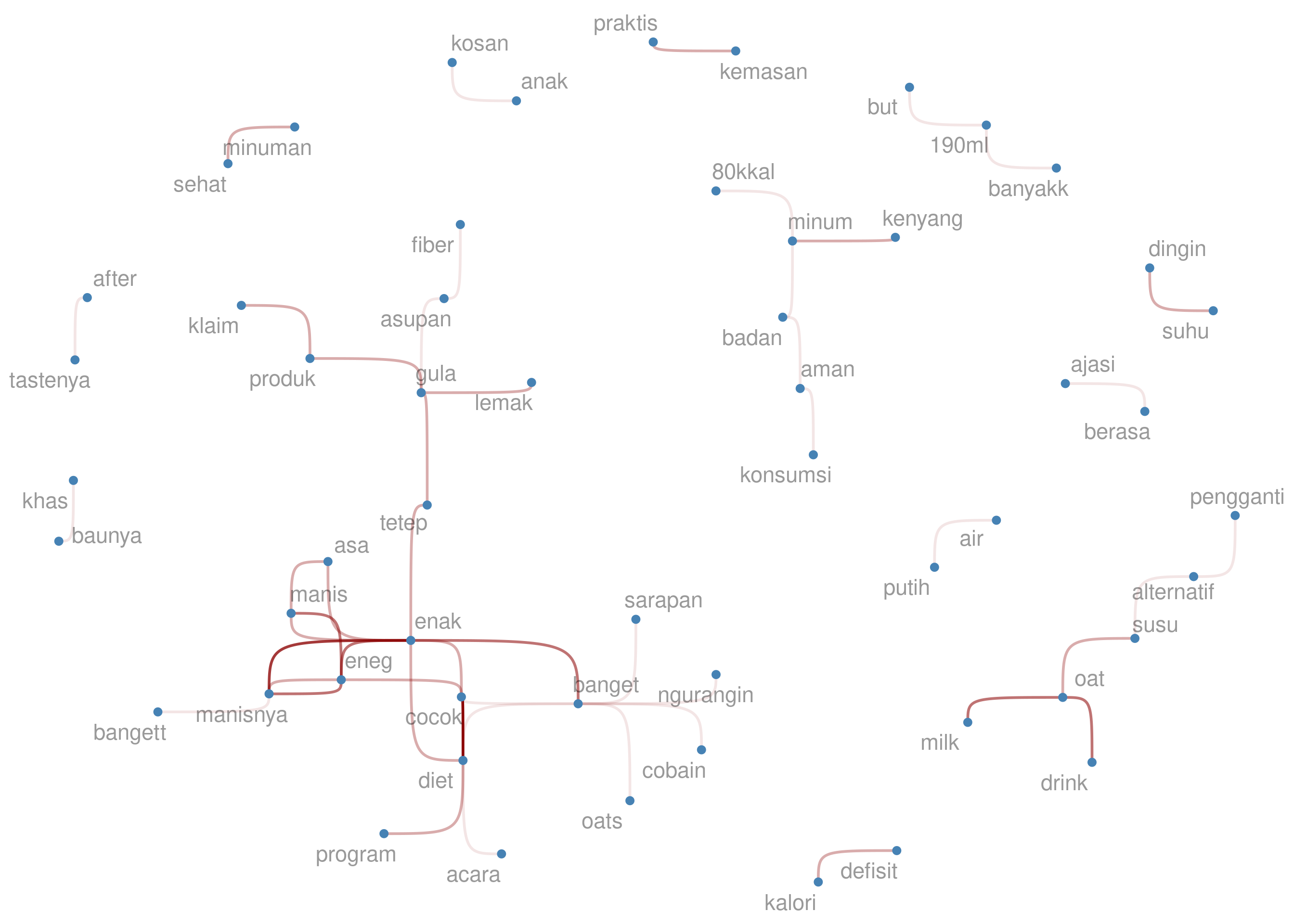
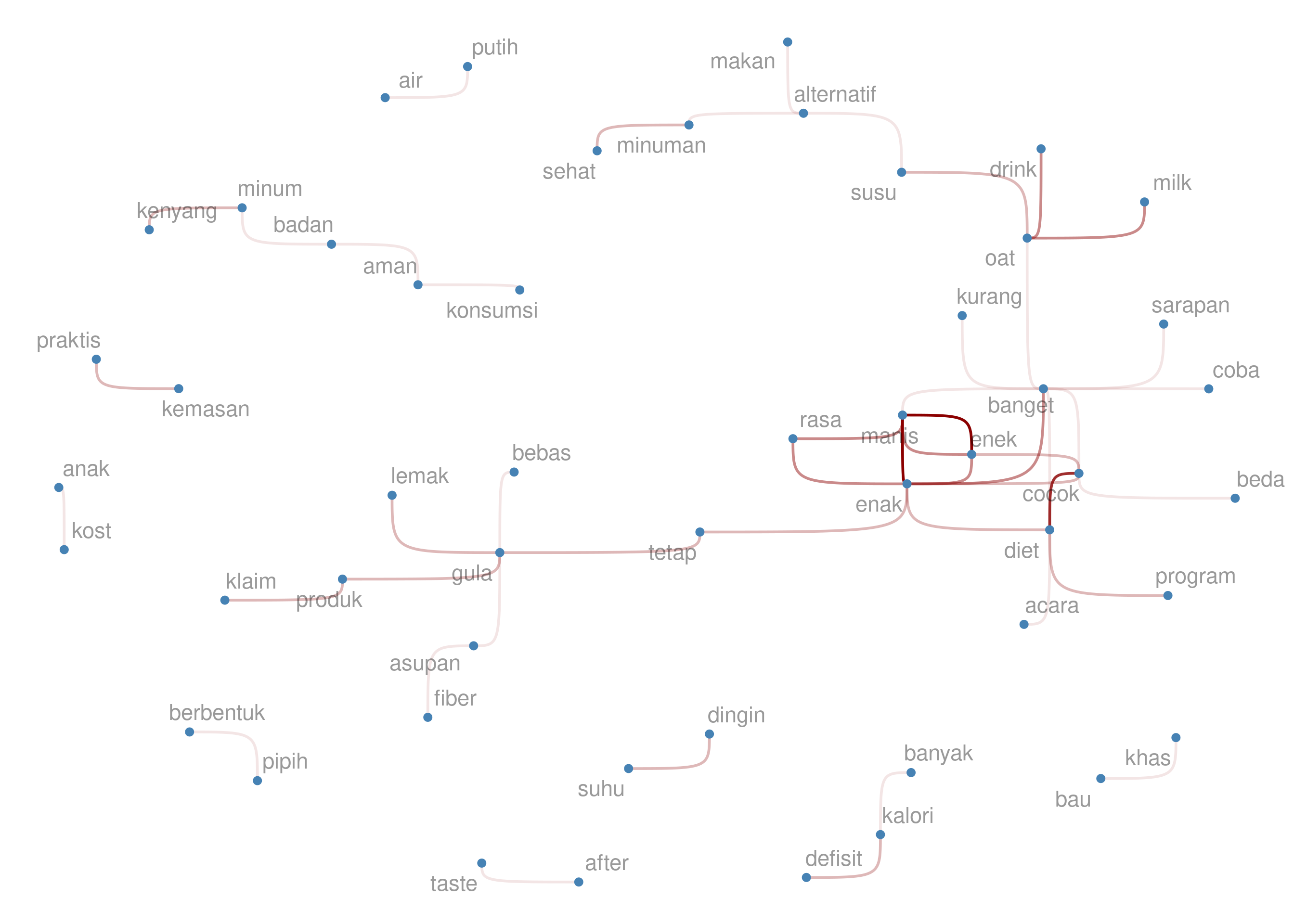
Dari bigrams di atas, saya akan eliminasi beberapa kata yang tak
bermakna menurut saya, seperti but dan 190ml. Proses ini saya
lakukan secara iteratif hingga semua kata tak bermakna hilang. Berikut
adalah hasil akhir bigrams-nya:
Karena reviews yang ada berbahasa Indonesia, saya sengaja tidak melakukan stemming kata menjadi kata dasar. Kenapa?
Saya belum menemukan library yang tepat dan baik untuk melakukan stemming Bahasa Indonesia.
Jika rekan-rekan memiliki saran terkait ini, let me know yah.
Tahap Pengerjaan II
Sekarang kita masuk ke tahap berikutnya, yakni kita akan mencari
tf-idf. Untuk melakukannya saya akan gunakan library di R yang
terkait dengan NLP, yakni library(tm). Kelak tf-idf akan
dijadikan basis pembuatan cluster.
Oke, mungkin ada yang bertanya-tanya:
Apa itu
tf-idf?
tf-idf adalah singkatan dari term frequency - inverse document
frequency.
- Term-frequency adalah perhitungan frekuensi dari kata-kata per dokumen. Analoginya adalah kita mencari kata-kata yang populer dari suatu dokumen.
- Inverse document frequency adalah perhitungan frekuensi dari kata-kata dari semua himpunan dokumen. Analoginya adalah kita mencari kata-kata yang unique dari suatu dokumen. Diharapkan kata-kata ini menjadi pembeda antara satu dokumen dengan dokumen lainnya.
tf-idf sendiri adalah perhitungan skor yang melibatkan kedua
perhitungan di atas. Di R, perhitungan ini sudah otomatis
menggunakan library(tm).
library(tm)
# membuat corpus terlebih dahulu
corpus_clean = Corpus(VectorSource(raw$komen))
# membuat document term matrix
tdm = DocumentTermMatrix(corpus_clean)
# membuat tf-idf
tdm_tfidf = weightTfIdf(tdm)
# kita filter hanya fitur-fitur yang penting saja
tdm_tfidf = removeSparseTerms(tdm_tfidf,.9999)
# sedangkan ini kita buat dalam bentuk matriks
# output dari skrip ini adalah data frame sebagai input untuk
# algoritma k-means cluster
tfidf_matrix = as.matrix(tdm_tfidf)
# output dari skrip ini sebagai input untuk algoritma
# hierarchical cluster perhitungan jarak dengan metode cosine
dist_matrix = proxy::dist(tfidf_matrix,method = "cosine")
Tahap Pengerjaan III: Clustering Analysis
Pengerjaan clustering untuk data teks yang sudah kita ubah sama halnya dengan data numerik pada umumnya. Tutorialnya bisa rekan-rekan lihat di tulisan saya sebelumnya.
k-means clustering
Pertama-tama, kita akan lakukan teknik k-means clustering. Langkah
awal yang harus dilakukan adalah menentukan nilai k dengan beberapa
metode, seperti elbow dan silhouette.

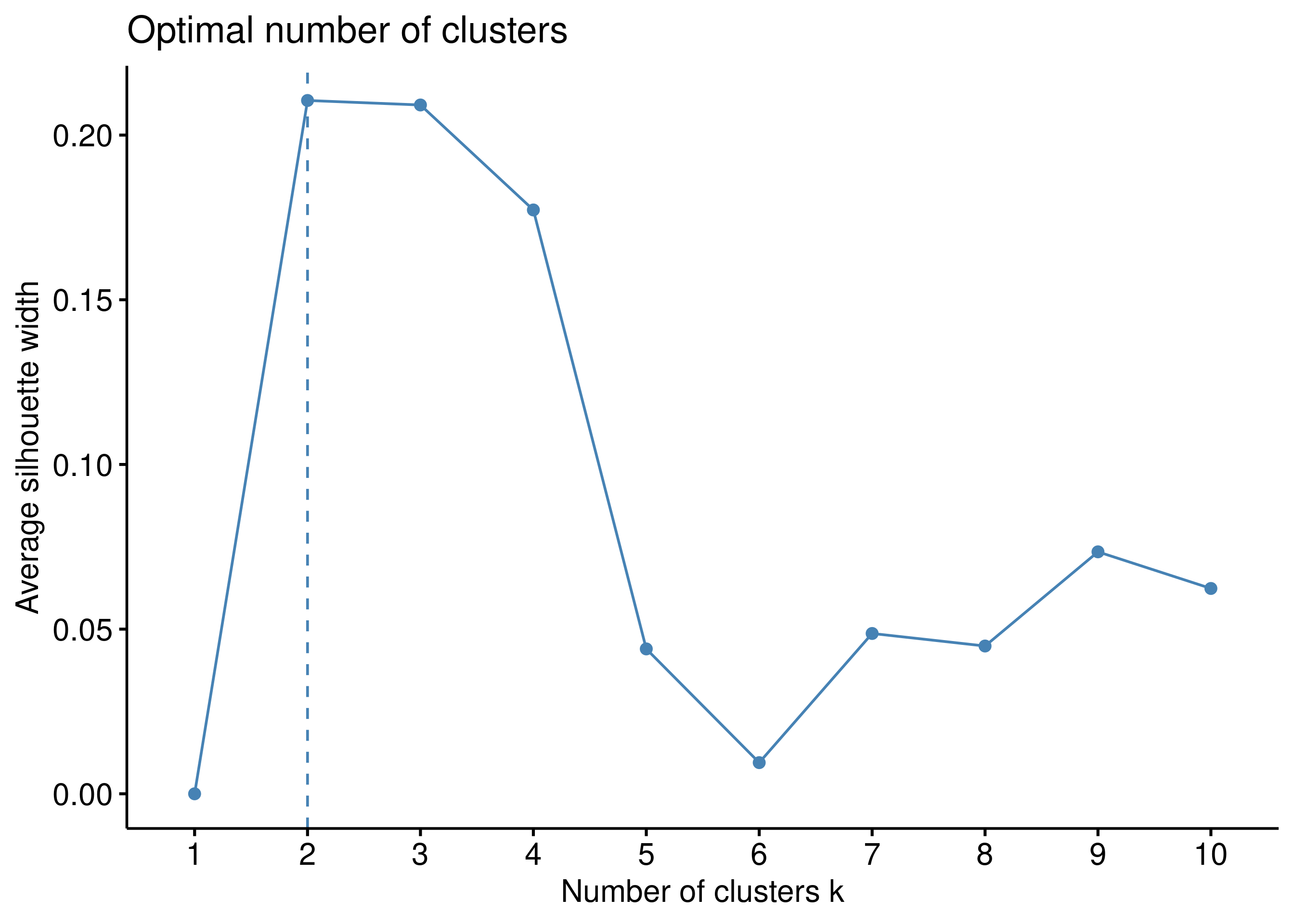
Terlihat dari metode di atas, kita akan ambil nilai k = 2. Maka dari
itu, kita akan run algoritmanya sebagai berikut:
# run algoritma
final = kmeans(tfidf_matrix,2,nstart = 25)
# ==================================================
# mengambil keywords dari masing-masing cluster
# mengubah ke data frame
result =
final$centers |>
as.data.frame()
# memisalkan per cluster
result =
result |>
mutate(id = 1:nrow(result)) |>
reshape2::melt(id.var = "id") %>%
group_split(id)
# function ambil keywords
ambil_keywords = function(list){
list |>
arrange(desc(value)) |>
head(5)
}
# mengambil keywords dengan parallel processing
library(parallel)
num_cores = detectCores()
key_final = mclapply(result,ambil_keywords,
mc.cores = num_cores)
do.call(rbind,key_final) |>
ggplot(aes(x = reorder(variable,id),y = value,
fill = as.factor(id))) +
geom_col(color = "black") +
coord_flip() +
labs(title = "Cluster Centers",
subtitle = "Keywords masing-masing cluster dengan metode k-means",
caption = "dibuat dengan R\nikanx101.com",
y = "Nilai pusat cluster",
x = "Keywords",
fill = "Cluster") +
scale_fill_manual(values = c("darkgreen","steelblue")) +
theme_minimal() +
theme(axis.text.x = element_blank())

Dari kedua clusters yang terbentuk terlihat ada 5 keywords per cluster yang membedakan satu sama lain.
- Cluster 1: susu, enak, diet, enek, dan manis.
- Cluster 2: kekentalan, vanilla, rasa, oat, dan hambar.
Dari 45 reviews, ternyata ada 44 reviews masuk ke dalam cluster
1 dan hanya 1 review masuk ke dalam cluster 2.
Terlihat bahwa k-means bisa jadi tidak terlalu konklusif dalam mengelompokan data reviews ini.
Hipotesis saya, hal ini terjadi karena review yang ada terlalu pendek
(1-3 kalimat saja). Sedangkan metode k-means akan lebih ngefek jika
data teks per id banyak (berupa paragraf atau tulisan panjang).
Saya akan buat grafik untuk validasi sebagai berikut:
# membuat data frame dengan menambahkan hasil cluster
validasi_k_means =
tfidf_matrix |>
as.data.frame() |>
mutate(cluster = final$cluster) |>
arrange(cluster) |>
select(-cluster)
# membuat matriks jarak
validasi_matrix = proxy::dist(validasi_k_means,
method = "cosine",
diag = T,
upper = T)
# membuat grafik dari matriks jarak
df = reshape2::melt(as.matrix(validasi_matrix),
varnames = c("row", "col"))
df |>
ggplot(aes(x = row,y = col)) +
geom_tile(aes(fill = value)) +
theme_void()

Secara grafik, (personally) tidak terlihat hasil clustering yang baik.
hierarchical clustering
Sekarang kita akan gunakan teknik hierarchical clustering dengan
pendekatan perhitungan jarak antar cluster dengan metode ward.D2.
Berikut adalah dendogram hasil run algoritma-nya:
set.seed(240) # Setting seed
# perhitungan cluster
clus_hie = hclust(dist_matrix,method = "ward.D2")
plot(clus_hie)
rect.hclust(clus_hie, k = 2, border = "red")
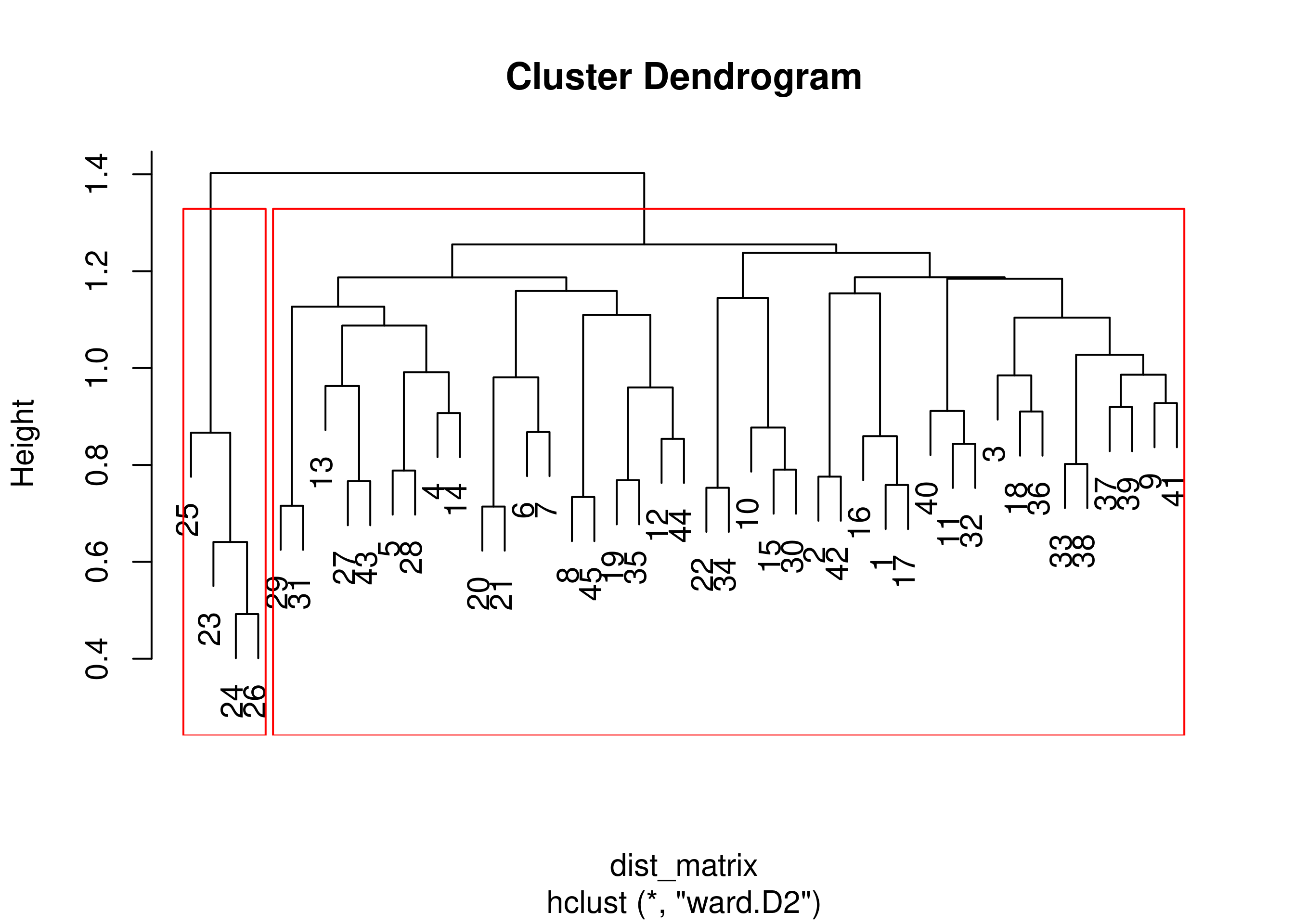
# kita simpan clusternya
fit = cutree(clus_hie, k = 2)
Terlihat ada 2 clusters besar yang terbentuk. Kita akan ambil
keywords dari kedua clusters tersebut:
# membuat data frame dengan menambahkan hasil cluster
result_hie =
tfidf_matrix |>
as.data.frame() |>
mutate(cluster = fit)
# memisalkan per cluster
result_hie_per_cluster =
result_hie |>
reshape2::melt(id.var = "cluster") |>
group_split(cluster)
# mengambil keywords dengan parallel processing
key_final = mclapply(result_hie_per_cluster,ambil_keywords,
mc.cores = num_cores)
do.call(rbind,key_final) |>
group_by(cluster,variable) |>
summarise(value = mean(value)) |>
ungroup() |>
ggplot(aes(x = reorder(variable,cluster),y = value,
fill = as.factor(cluster))) +
geom_col(color = "black") +
coord_flip() +
labs(title = "Cluster Centers",
subtitle = "Keywords masing-masing cluster dengan metode hierarki",
caption = "dibuat dengan R\nikanx101.com",
y = "Nilai pusat cluster",
x = "Keywords",
fill = "Cluster") +
#scale_fill_manual(values = c("darkgreen","steelblue")) +
theme_minimal() +
theme(axis.text.x = element_blank())

Terlihat bahwa masing-masing cluster memiliki keywords yang berbeda-beda.
- Cluster 1: ingin, dairy, favorit, dan susu.
- Cluster 2: kekentalan, khawatir, vanilla, rasa, dan hambar.
Saya akan buat grafik validasinya seperti pada bagian sebelumnya:
validasi_hie =
result_hie |>
arrange(cluster) |>
select(-cluster)
# membuat matriks jarak
validasi_matrix = proxy::dist(validasi_hie,
method = "cosine",
diag = T,
upper = T)
# membuat grafik dari matriks jarak
df = reshape2::melt(as.matrix(validasi_matrix),
varnames = c("row", "col"))
df |>
ggplot(aes(x = row,y = col)) +
geom_tile(aes(fill = value)) +
theme_void()

DBScan clustering
Metode clustering terakhir yang hendak saya coba adalah DBScan alias density-based. Penjelasannya, bisa dilihat di tulisan saya sebelumnya.
library(fpc)
library(dbscan)
# membuat data frame
df =
tfidf_matrix |>
as.data.frame()
# menentukan nilai cut-off h
dbscan::kNNdistplot(df, k = 30)
abline(h = 1.98, lty = 2, col = "red")

Setelah menemukan nilai h, kita run algoritmanya:
# melakukan clustering
Dbscan_cl = dbscan(df, eps = 1.98, minPts = 5)
df$cluster = Dbscan_cl$cluster
Sekarang saya cari keywords untuk masing-masing cluster.
# membuat data frame hasil
result_dbs = df
# memisalkan per cluster
result_dbs_per_cluster =
result_dbs |>
reshape2::melt(id.var = "cluster") |>
group_split(cluster)
# mengambil keywords dengan parallel processing
key_final = mclapply(result_dbs_per_cluster,ambil_keywords,
mc.cores = num_cores)
do.call(rbind,key_final) |>
group_by(cluster,variable) |>
summarise(value = mean(value)) |>
ungroup() |>
ggplot(aes(x = reorder(variable,cluster),y = value,
fill = as.factor(cluster))) +
geom_col(color = "black") +
coord_flip() +
labs(title = "Cluster Centers",
subtitle = "Keywords masing-masing cluster dengan metode density-based",
caption = "dibuat dengan R\nikanx101.com",
y = "Nilai pusat cluster",
x = "Keywords",
fill = "Cluster") +
#scale_fill_manual(values = c("darkgreen","steelblue")) +
theme_minimal() +
theme(axis.text.x = element_blank())
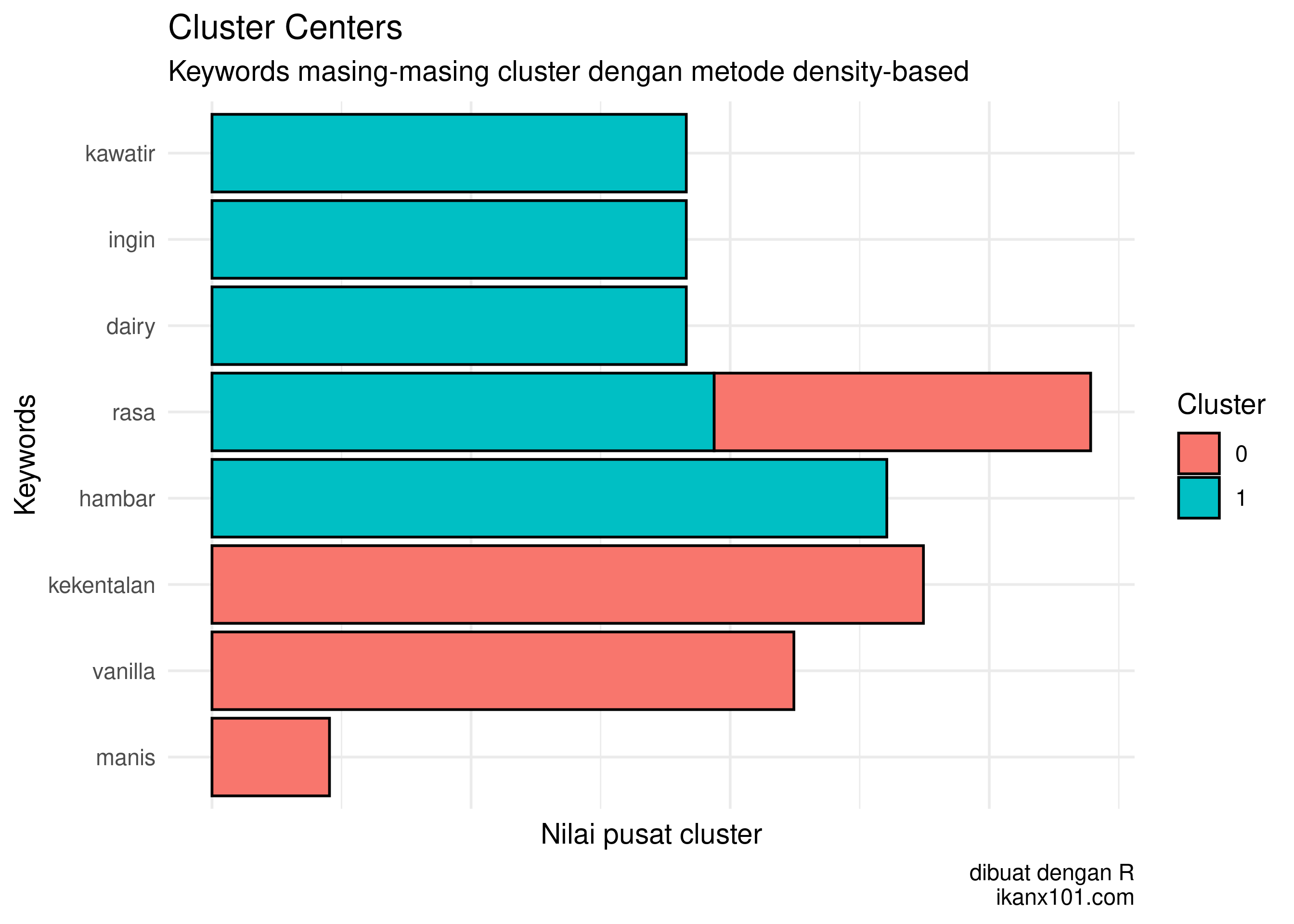
Dari kedua clusters yang terbentuk terlihat ada 5 keywords per cluster yang membedakan satu sama lain.
- Cluster 1: khawatir, ingin, dairy, rasa, dan hambar.
- Cluster 2: rasa, kekentalan, vanilla, dan manis.
Sebagai validasi, saya buat grafik yang serupa dengan bagian sebelumnya.
# menyiapkan data untuk visualisasi
validasi_dbs =
df |>
arrange(cluster) |>
select(-cluster)
# membuat matriks jarak
validasi_matrix = proxy::dist(validasi_dbs,
method = "cosine",
diag = T,
upper = T)
# membuat grafik dari matriks jarak
df = reshape2::melt(as.matrix(validasi_matrix),
varnames = c("row", "col"))
df |>
ggplot(aes(x = row,y = col)) +
geom_tile(aes(fill = value)) +
theme_void()

Terlihat juga tidak ada pola yang jelas.
Kesimpulan
- Dari beberapa metode di atas, clusters yang terbentuk sepertinya memiliki kesamaan keywords.
- Hipotesis:
- Review yang ada kurang panjang sehingga
tf-idfyang dihasilkan kurang memberikan hasil yang konklusif. - Review yang ada memang hanya berisi topik-topik yang sejenis sehingga hasil clustering di atas sudah benar adanya.
- Review yang ada kurang panjang sehingga
if you find this article helpful, support this blog by clicking the ads.