
Tutorial Data Carpentry: Harga Sedan Bekas di Carmudi
Pendahuluan
Salah satu keunggulan R dibandingkan dengan analytics tools lainnya adalah kemampuannya untuk memanipulasi data. Manipulasi dalam artian positif, yakni preprocessing data atau data carpentry atau bebersih data.
Di dunia ini, tanpa kita sadari data tersebar sangat banyak. Namun tidak semuanya berbentuk structured data. Sebagian besar sebenarnya masuk ke dalam unstructured data atau semi structured data.
Seringkali kita enggan berhadapan dengan unstructured data atau semi structured data. Jujur, sayapun dulu males banget kalau nemu data yang bentuknya kayak gini. Nah, kali ini kita akan mencoba untuk mengolah unstructured data menjadi informasi atau insight(s).
Libraries yang Digunakan
Berikut adalah beberapa libraries yang digunakan dalam training kali ini:
rvest: web scraping.dplyr: data carpentry.tidytext: text data carpentry.tidyr: data carpentry (advance).ggplot2: visualisasi data.
library(dplyr)
library(rvest)
library(tidytext)
library(tidyr)
library(ggplot2)
Data yang Digunakan
Kita akan mengambil data dari situs carmudi tentang listing mobil sedan bekas. Mengambil data dari websites disebut dengan web scraping.
Kalau kita lihat situsnya, sampai saat ini ada 71 buah pages. Kita akan scrap semua informasinya.
Web Scrap Situs Carmudi
Oh iya, detail tentang web scraping akan saya bahas di training atau tulisan terpisah yah. Kali ini rekan-rekan terima jadi aja fungsinya seperti ini.
Langkah pertama
Kita akan define semua urls dari carmudi lalu kita buat fungsi web scrap-nya.
#link dari carmudi
url = paste('https://www.carmudi.co.id/cars/saloon/condition:all/?page=',
c(1:71),
sep='')
#Bikin fungsi scrap carmudi
scrap = function(url){
data =
read_html(url) %>% {
tibble(
nama = html_nodes(.,'.title-blue') %>% html_text(),
harga = html_nodes(.,'.price a') %>% html_text(),
lokasi = html_nodes(.,'.catalog-listing-item-location span') %>%
html_text()
)
}
return(data)
}
Langkah kedua
Saya scrap datanya dari url pertama hingga selesai. Saya masih
senang menggunakan looping dibandingkan menggunakan fungsi lapply().
Sepertinya lebih firm saja menurut saya.
#kita mulai scrap datanya
i = 1
sedan.data = scrap(url[i])
for(i in 2:length(url)){
temp = scrap(url[i])
sedan.data = rbind(sedan.data,temp)
}
str(sedan.data)
## Classes 'tbl_df', 'tbl' and 'data.frame': 2081 obs. of 3 variables:
## $ nama : chr "\n2015 Toyota Corolla Altis V 1.8 AT " "\n2000 Toyota Corolla SE.G " "\n2013 Mercedes-Benz E300 AMG " "\n2016 Honda City Ivtec " ...
## $ harga : chr "208 Juta" "60 Juta" "430 Juta" "195 Juta" ...
## $ lokasi: chr "\nTangerang " "\nKabupaten Sidoarjo " "\nJakarta Utara " "\nKota Jakarta Selatan " ...
head(sedan.data,15)
## # A tibble: 15 x 3
## nama harga lokasi
## <chr> <chr> <chr>
## 1 "\n2015 Toyota Corolla Altis V 1.8 AT " 208 Juta "\nTangerang "
## 2 "\n2000 Toyota Corolla SE.G " 60 Juta "\nKabupaten Sidoarj…
## 3 "\n2013 Mercedes-Benz E300 AMG " 430 Juta "\nJakarta Utara "
## 4 "\n2016 Honda City Ivtec " 195 Juta "\nKota Jakarta Sela…
## 5 "\n2014 Honda Civic 1.8 Ivtec " 185 Juta "\nKota Jakarta Sela…
## 6 "\n2008 Suzuki Baleno Matic " 100 Juta "\nMalang "
## 7 "\n2008 Toyota Corolla Altis 1.8 VVTI Al… 92.5 Ju… "\nDKI Jakarta "
## 8 "\n2010 Honda Accord 2.4 VTIL " 129 Juta "\nJakarta Barat "
## 9 "\n2014 Toyota Camry 2.5 V AT " 189 Juta "\nJakarta Barat "
## 10 "\n2014 Toyota Vios G Allnew A/T " 129 Juta "\nDKI Jakarta "
## 11 "\n2016 BMW 320i Sport LCi Black On Blac… 565 Juta "\nJakarta Selatan "
## 12 "\n2017 Mercedes-Benz E250 Avantgarde Re… 975 Juta "\nJakarta Selatan "
## 13 "\n2018 Mercedes-Benz E200 Avantgarde Ni… 975 Juta "\nJakarta Selatan "
## 14 "\n2018 BMW 520i Luxury Reg.2019 Black O… 895 Juta "\nJakarta Selatan "
## 15 "\n2007 Honda Civic " 110 Juta "\nJakarta Utara "
Hasil scrap data
Didapatkan ada 2081 baris data mobil sedan bekas yang di- listing di
carmudi.
Kalau kita lihat sekilas, data tersebut seolah-olah structured. Namun
kalau diperhatikan secara seksama, sebenarnya data tersebut
semi-structured. Variabel harga berupa character karena tulisan
juta. Sedangkan variabel nama masih campur aduk adanya tahun produksi
dan varian mobil.
So, kita memiliki tiga masalah, yakni:
- Bagaimana mengubah
hargamenjadi numerik agar bisa dianalisa? - Bagaimana mengekstrak
tahundari variabelnama. - Mungkinkah bagi kita menganalisa per
brand?
Proses Data Carpentry
Membereskan variabel harga
Kita mulai dari membereskan variabel yang paling gampang, yakni
harga.
sedan.data = sedan.data %>% separate(harga,into=c('angka','unit'),sep=' ')
unique(sedan.data$unit)
## [1] "Juta" "Milyar"
sedan.data =
sedan.data %>% mutate(angka = as.numeric(angka),
unit = ifelse(unit == 'Juta',1000000,1000000000),
unit = as.numeric(unit),
harga = angka*unit,
angka = NULL,
unit = NULL)
head(sedan.data,15)
## # A tibble: 15 x 3
## nama lokasi harga
## <chr> <chr> <dbl>
## 1 "\n2015 Toyota Corolla Altis V 1.8 AT " "\nTangerang " 2.08e8
## 2 "\n2000 Toyota Corolla SE.G " "\nKabupaten Sidoarj… 6.00e7
## 3 "\n2013 Mercedes-Benz E300 AMG " "\nJakarta Utara " 4.30e8
## 4 "\n2016 Honda City Ivtec " "\nKota Jakarta Sela… 1.95e8
## 5 "\n2014 Honda Civic 1.8 Ivtec " "\nKota Jakarta Sela… 1.85e8
## 6 "\n2008 Suzuki Baleno Matic " "\nMalang " 1.00e8
## 7 "\n2008 Toyota Corolla Altis 1.8 VVTI Al… "\nDKI Jakarta " 9.25e7
## 8 "\n2010 Honda Accord 2.4 VTIL " "\nJakarta Barat " 1.29e8
## 9 "\n2014 Toyota Camry 2.5 V AT " "\nJakarta Barat " 1.89e8
## 10 "\n2014 Toyota Vios G Allnew A/T " "\nDKI Jakarta " 1.29e8
## 11 "\n2016 BMW 320i Sport LCi Black On Blac… "\nJakarta Selatan " 5.65e8
## 12 "\n2017 Mercedes-Benz E250 Avantgarde Re… "\nJakarta Selatan " 9.75e8
## 13 "\n2018 Mercedes-Benz E200 Avantgarde Ni… "\nJakarta Selatan " 9.75e8
## 14 "\n2018 BMW 520i Luxury Reg.2019 Black O… "\nJakarta Selatan " 8.95e8
## 15 "\n2007 Honda Civic " "\nJakarta Utara " 1.10e8
Done!!! Selesai.
Membereskan variabel nama dan mengekstrak tahun
Oke, sekarang kita akan membereskan variabel nama. Sebelum
melakukannya, saya akan menghapuskan tanda \n dan menambahkan variabel
id untuk memudahkan proses ekstrak tahun nantinya.
sedan.data =
sedan.data %>%
mutate(nama = gsub('\\\n','',nama),
id = c(1:length(nama)))
head(sedan.data,15)
## # A tibble: 15 x 4
## nama lokasi harga id
## <chr> <chr> <dbl> <int>
## 1 "2015 Toyota Corolla Altis V 1.8 AT… "\nTangerang " 2.08e8 1
## 2 "2000 Toyota Corolla SE.G " "\nKabupaten Sidoar… 6.00e7 2
## 3 "2013 Mercedes-Benz E300 AMG " "\nJakarta Utara " 4.30e8 3
## 4 "2016 Honda City Ivtec " "\nKota Jakarta Sel… 1.95e8 4
## 5 "2014 Honda Civic 1.8 Ivtec " "\nKota Jakarta Sel… 1.85e8 5
## 6 "2008 Suzuki Baleno Matic " "\nMalang " 1.00e8 6
## 7 "2008 Toyota Corolla Altis 1.8 VVTI… "\nDKI Jakarta " 9.25e7 7
## 8 "2010 Honda Accord 2.4 VTIL " "\nJakarta Barat " 1.29e8 8
## 9 "2014 Toyota Camry 2.5 V AT " "\nJakarta Barat " 1.89e8 9
## 10 "2014 Toyota Vios G Allnew A/T " "\nDKI Jakarta " 1.29e8 10
## 11 "2016 BMW 320i Sport LCi Black On B… "\nJakarta Selatan " 5.65e8 11
## 12 "2017 Mercedes-Benz E250 Avantgarde… "\nJakarta Selatan " 9.75e8 12
## 13 "2018 Mercedes-Benz E200 Avantgarde… "\nJakarta Selatan " 9.75e8 13
## 14 "2018 BMW 520i Luxury Reg.2019 Blac… "\nJakarta Selatan " 8.95e8 14
## 15 "2007 Honda Civic " "\nJakarta Utara " 1.10e8 15
Nah, sekarang untuk mengekstrak tahun saya akan gunakan metode yang
sama untuk membuat word cloud atau word counting. Pandang variabel
nama sebagai satu kalimat utuh yang kemudian akan dipisah-pisah per
kata. Setiap angka yang muncul akan kita jadikan variabel tahun.
new =
sedan.data %>% select(id,nama) %>%
unnest_tokens('words',nama) %>%
mutate(words = as.numeric(words)) %>%
filter(!is.na(words),words>1900,words<2021)
## Warning: NAs introduced by coercion
head(new,15)
## # A tibble: 15 x 2
## id words
## <int> <dbl>
## 1 1 2015
## 2 2 2000
## 3 3 2013
## 4 4 2016
## 5 5 2014
## 6 6 2008
## 7 7 2008
## 8 8 2010
## 9 9 2014
## 10 10 2014
## 11 11 2016
## 12 12 2017
## 13 13 2018
## 14 14 2018
## 15 14 2019
Sekarang kita akan cek terlebih dahulu, apakah benar satu id
menghasilkan satu tahun.
# kita akan cek apakah ada dua `tahun` per id
masalah = new %>% group_by(id) %>% summarise(freq=n()) %>% filter(freq>1)
masalah
## # A tibble: 13 x 2
## id freq
## <int> <int>
## 1 14 2
## 2 58 2
## 3 62 2
## 4 66 2
## 5 67 2
## 6 91 2
## 7 97 2
## 8 103 2
## 9 108 2
## 10 111 2
## 11 112 2
## 12 113 2
## 13 1795 2
Ternyata didapatkan ada 13 baris data yang menghasilkan dua tahun.
Coba kita lihat datanya:
sedan.data %>% filter(id %in% masalah$id)
## # A tibble: 13 x 4
## nama lokasi harga id
## <chr> <chr> <dbl> <int>
## 1 "2018 BMW 520i Luxury Reg.2019 Black O… "\nJakarta Selat… 8.95e8 14
## 2 "2015 BMW 328i M-Sport Reg.2016 KM 20R… "\nJakarta Selat… 5.95e8 58
## 3 "2017 Mercedes-Benz C200 AMG Reg.2018 … "\nJakarta Selat… 7.50e8 62
## 4 "2017 BMW 520d Luxury Reg.2018 Black O… "\nJakarta Selat… 8.95e8 66
## 5 "2012 BMW 730Li Luxury Reg.2013 KM 40R… "\nJakarta Selat… 7.25e8 67
## 6 "2014 BMW 320i Sport F30 Reg.2015 Whit… "\nJakarta Selat… 4.85e8 91
## 7 "2016 BMW 320i Sport LCi Reg.2017 Whit… "\nJakarta Selat… 5.85e8 97
## 8 "2016 BMW 528i Luxury Reg.2017 White K… "\nJakarta Selat… 7.95e8 103
## 9 "2016 BMW 520i Luxury Reg.2017 Black K… "\nJakarta Selat… 7.45e8 108
## 10 "2016 BMW 330i M-Sport Reg.2017 Miami … "\nJakarta Selat… 7.45e8 111
## 11 "2016 BMW 330i M-Sport Reg.2017 White … "\nJakarta Selat… 7.45e8 112
## 12 "2015 Mercedes-Benz C250 AMG Reg. 2016… "\nJakarta Selat… 7.25e8 113
## 13 "2017 BMW 320i Sport LCi Reg.2018 Digi… "\nJakarta Utara… 5.35e8 1795
Untuk kasus seperti ini, kita akan buat simpel yah. Kita akan ambil
tahunterlama dari datasetnew.
Gimana caranya?
new = new %>% group_by(id) %>% filter(words == min(words)) %>% ungroup()
Sekarang kita akan merge dataset new ke dataset sedan.data.
sedan.data = merge(sedan.data,new)
colnames(sedan.data)[5] = 'tahun'
head(sedan.data,15)
## id nama lokasi
## 1 1 2015 Toyota Corolla Altis V 1.8 AT \nTangerang
## 2 2 2000 Toyota Corolla SE.G \nKabupaten Sidoarjo
## 3 3 2013 Mercedes-Benz E300 AMG \nJakarta Utara
## 4 4 2016 Honda City Ivtec \nKota Jakarta Selatan
## 5 5 2014 Honda Civic 1.8 Ivtec \nKota Jakarta Selatan
## 6 6 2008 Suzuki Baleno Matic \nMalang
## 7 7 2008 Toyota Corolla Altis 1.8 VVTI Alln... \nDKI Jakarta
## 8 8 2010 Honda Accord 2.4 VTIL \nJakarta Barat
## 9 9 2014 Toyota Camry 2.5 V AT \nJakarta Barat
## 10 10 2014 Toyota Vios G Allnew A/T \nDKI Jakarta
## 11 11 2016 BMW 320i Sport LCi Black On Black A... \nJakarta Selatan
## 12 12 2017 Mercedes-Benz E250 Avantgarde Reg.2... \nJakarta Selatan
## 13 13 2018 Mercedes-Benz E200 Avantgarde Nik20... \nJakarta Selatan
## 14 14 2018 BMW 520i Luxury Reg.2019 Black On B... \nJakarta Selatan
## 15 15 2007 Honda Civic \nJakarta Utara
## harga tahun
## 1 2.08e+08 2015
## 2 6.00e+07 2000
## 3 4.30e+08 2013
## 4 1.95e+08 2016
## 5 1.85e+08 2014
## 6 1.00e+08 2008
## 7 9.25e+07 2008
## 8 1.29e+08 2010
## 9 1.89e+08 2014
## 10 1.29e+08 2014
## 11 5.65e+08 2016
## 12 9.75e+08 2017
## 13 9.75e+08 2018
## 14 8.95e+08 2018
## 15 1.10e+08 2007
Mungkin ada yang sadar, bahwa sekarang banyaknya baris data tinggal
2080. Kenapa? Ada yang bisa jawab? Heeeee.
Mengekstrak Brand Mobil
Nah, pekerjaan yang paling menantang adalah mengambil dan mengekstrak
brand dari variabel nama.
Ada yang punya ide bagaimana caranya?
Prinsip yang sama dengan pengerjaan tahun.
new =
sedan.data %>% select(id,nama) %>%
unnest_tokens('words',nama) %>%
count(words,sort=T)
brand = c('toyota','honda','mercedes','bmw','suzuki',
'mitsubishi','hyundai','mazda','nissan',
'audi','chevrolet','hyundai','peugeot',
'lexus','ford','jaguar','proton',
'daihatsu','volkswagen','bentley',
'chrysler','timor','maserati','subaru','kia',
'opel','volvo','porsche','geely','fiat')
marker =
sedan.data %>% select(id,nama) %>%
unnest_tokens('words',nama) %>%
filter(words %in% brand)
sedan.data = merge(sedan.data,marker,all=T)
sedan.data = distinct(sedan.data)
# cek yang belum ada brand nya
sedan.data %>% filter(is.na(words))
## [1] id nama lokasi harga tahun words
## <0 rows> (or 0-length row.names)
openxlsx::write.xlsx(sedan.data,'Hasil Data Carpentry Sedan Bekas.xlsx')
Hasil yang didapatkan:
## id nama lokasi
## 1 1 2015 Toyota Corolla Altis V 1.8 AT \nTangerang
## 2 2 2000 Toyota Corolla SE.G \nKabupaten Sidoarjo
## 3 3 2013 Mercedes-Benz E300 AMG \nJakarta Utara
## 4 4 2016 Honda City Ivtec \nKota Jakarta Selatan
## 5 5 2014 Honda Civic 1.8 Ivtec \nKota Jakarta Selatan
## 6 6 2008 Suzuki Baleno Matic \nMalang
## 7 7 2008 Toyota Corolla Altis 1.8 VVTI Alln... \nDKI Jakarta
## 8 8 2010 Honda Accord 2.4 VTIL \nJakarta Barat
## 9 9 2014 Toyota Camry 2.5 V AT \nJakarta Barat
## 10 10 2014 Toyota Vios G Allnew A/T \nDKI Jakarta
## 11 11 2016 BMW 320i Sport LCi Black On Black A... \nJakarta Selatan
## 12 12 2017 Mercedes-Benz E250 Avantgarde Reg.2... \nJakarta Selatan
## 13 13 2018 Mercedes-Benz E200 Avantgarde Nik20... \nJakarta Selatan
## 14 14 2018 BMW 520i Luxury Reg.2019 Black On B... \nJakarta Selatan
## 15 15 2007 Honda Civic \nJakarta Utara
## harga tahun words
## 1 2.08e+08 2015 toyota
## 2 6.00e+07 2000 toyota
## 3 4.30e+08 2013 mercedes
## 4 1.95e+08 2016 honda
## 5 1.85e+08 2014 honda
## 6 1.00e+08 2008 suzuki
## 7 9.25e+07 2008 toyota
## 8 1.29e+08 2010 honda
## 9 1.89e+08 2014 toyota
## 10 1.29e+08 2014 toyota
## 11 5.65e+08 2016 bmw
## 12 9.75e+08 2017 mercedes
## 13 9.75e+08 2018 mercedes
## 14 8.95e+08 2018 bmw
## 15 1.10e+08 2007 honda
Error Bar Plot untuk harga mobil
Nah, saya sudah mendapatkan data yang saya butuhkan. Sekarang saya akan membuat analisa harga per brand menggunakan error bar.
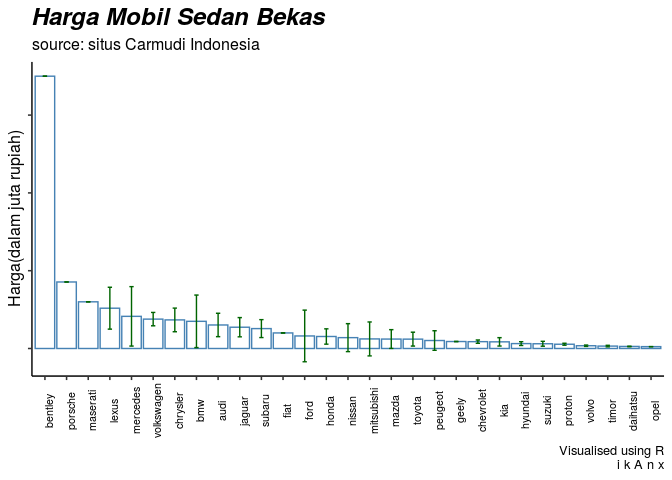
Catatan Penting
Algoritma adalah formalisasi dari alur proses berpikir. So apa yang saya tulis di sini bukanlah satu-satunya solusi untuk membersihkan data yah!