
Menghitung Probabilitas Kesamaan Packaging Dua Produk Minuman Menggunakan Algoritma Deep Learning di R
Prolog: 2013
Pada tahun 2013 lalu, saya dan beberapa rekan kerja berdiskusi seru
mengenai adanya satu produk low calorie sweetener yang memiliki
packaging yang mirip dengan brand yang diproduksi perusahaan saya.
Jika dilihat sekilas, tidak tampak ada perbedaan berarti. Apalagi
pemilihan warna dan layout gambarnya hampir mirip.
Jika kita bisa membuktikan bahwa kejadian ini membuat konsumen bingung, kita bisa membawanya ke ranah hukum.
Begitu celetuk salah seorang rekan saya.
Bagaimana caranya kita bisa membuktikan konsumen bingung? Hal pertama yang terlintas di benak saya adalah dengan melakukan survey kepada konsumen. Tapi tampaknya hal itu bukanlah solusi terbaik karena survey yang dilakukan harus benar-benar robust dan dihitung dengan statistik yang tepat.
Kenapa harus ribet begitu?
Agar hasilnya tidak bisa dipatahkan dengan mudah oleh siapapun.
Akhirnya ini hanya menjadi bahan diskusi seru tanpa ada aksi apapun di tim kami. Saya pribadi yakin kejadian ini akan berulang di masa mendatang.
2020
Sudah menjadi hal lumrah bagi setiap brand untuk mengikuti brand yang menjadi market leader dalam kategorinya. Mereka bisa menjadi follower dalam hal marketing, campaign iklan, profil rasa, sampai tema packaging produk.
Beberapa hari belakangan ini, saya melihat sebuah iklan dari produk
minuman bermerek Herbalice di televisi. Jika saya lihat sekilas
packaging yang ditampilkan di dalam iklan tersebut, rupa
packaging-nya mirip dengan brand minuman terkenal NutriSari.
Berikut gambar yang saya dapatkan di internet:

Bagaimana menurut kalian? Mirip gak sih?
Tapi yang menjadi pertanyaan adalah:
- Seberapa mirip?
- Apakah ada cara mengkuantifikasi kemiripan tersebut?
Kalau mengandalkan jawaban manusia, saya kira hasilnya bisa debatable. Oleh karena itu saya akan mencoba menghitung peluang kesamaannya dengan membuat algoritma deep learning menggunakan TensorFlow dan Keras di R.
Seharusnya dengan algoritma, hasilnya bisa less debatable jika saya melakukannya dengan benar.
Metode
Saya akan membuat algoritma supervised learning dengan metode deep
learning untuk mengklasifikasi gambar NutriSari dan non NutriSari.
Kemudian algoritma akan disuruh membaca gambar Herbalice tersebut.
Masih bingung? Saya jelaskan di bagan di bawah ini:

Saya mengumpulkan
16poto packaging NutriSari dan15poto packaging minuman buah selain NutriSari. Kemudian saya membuat algoritma yangbelajaruntuk mengidentifikasi poto mana yang masuk ke NutriSari, poto mana yang bukan termasuk NutriSari. Setelah performa algoritmanya sudah baik, saya akan masukkan poto Herbalice dan melihat hasil pembacaan dari algoritmanya.
Saya akan melihat berapa angka probabilitas hasil klasifikasinya!
Apakah packaging tersebut lebih diklasifikasikan ke NutriSari? Atau
diklasifikasikan ke non NutriSari?
Berikut ini adalah database poto packaging yang saya gunakan:

Dasar Teori
Deep Learning
Apa sih yang dimaksud deep learning? Apa bedanya dengan machine learning? Lalu apa bedanya dengan artificial intelligence?
## [1] "Sumber gambar: smartcityindo.com"
Secara simpel, saya bisa katakan bahwa:
- Artificial intelligence merupakan umbrella terms dari disiplin ilmu seperti applied science, engineering, dan computer science.
- Machine learning merupakan kumpulan metode atau algoritma untuk melakukan baik analisa supervised learning dan unsupervised learning.
- Deep Learning merupakan algoritma machine learning yang dibuat dengan metode Neural Network.
Neural Network
Neural Network adalah suatu algoritma yang proses komputasinya meniru sistem jaringan syaraf yang ada di tubuh manusia.
## [1] "Sumber gambar: wikipedia"
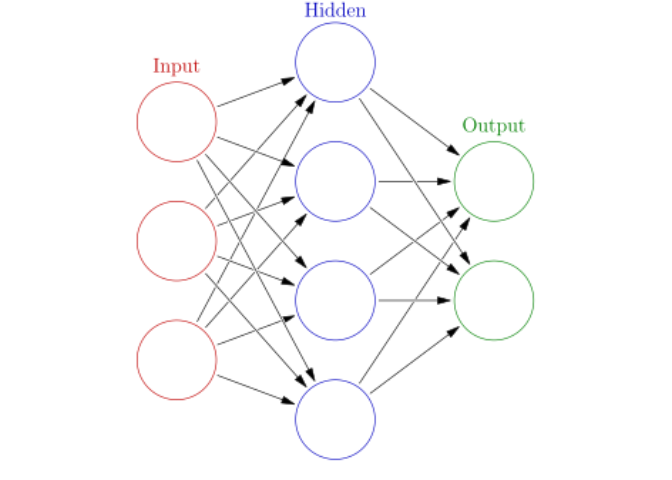
Walau bentuknya mirip dengan graf Social Network Analysis tapi ini adalah dua hal yang berbeda yah!
Pada algoritma machine learning, kita masih bisa melihat proses perhitungan dan menginterpretasikan modelnya secara langsung. Sedangkan pada deep learning, prosesnya bisa dibilang ghaib. Kita hanya mengatur ada berapa banyak layer, berapa banyak nodes per layer, dan activation function apa saja yang dipakai.
Mungkin karena itu dinamakan
deepyah. Saking “dalam”nya sampai-sampai tidak bisa dilihat.
Hal ini menjadi salah satu keunggulan neural network dibandingkan algoritma tipe lain untuk mengolah data berupa gambar.
Data Gambar
Jika kita memiliki suatu file gambar. Sejatinya gambar tersebut bisa dibaca sebagai matriks data RGB (Red, Green, dan Blue) dengan pixel size sebagai ukuran matriksnya.
Sebagai contoh, poto kemasan Herbalice jika diekstrak datanya, kita
dapatkan bentuk seperti ini:
## Image
## colorMode : Color
## storage.mode : double
## dim : 263 261 3
## frames.total : 3
## frames.render: 1
##
## imageData(object)[1:5,1:6,1]
## [,1] [,2] [,3] [,4] [,5] [,6]
## [1,] 0.5803922 0.6823529 0.7490196 0.8000000 0.7372549 0.6039216
## [2,] 0.5882353 0.6392157 0.6941176 0.7647059 0.7568627 0.6509804
## [3,] 0.5921569 0.6039216 0.6666667 0.7333333 0.7372549 0.6470588
## [4,] 0.5803922 0.6000000 0.6823529 0.7215686 0.6862745 0.5647059
## [5,] 0.5803922 0.6000000 0.6784314 0.7019608 0.6627451 0.5254902
Matriks dari data image bisa dibilang relatif “besar”. Oleh karena itu kita membutuhkan suatu algoritma komputasi yang efektif untuk mereduksi parameter tanpa mengurangi kualitas. Oleh karena itu neural network menjadi andalan saat berhubungan dengan image classifying.
TensorFlow dan KERAS
Apa itu TensorFlow?
TensorFlow is a free and open-source software library for machine learning. It can be used across a range of tasks but has a particular focus on training and inference of deep neural networks. Tensorflow is a symbolic math library based on dataflow and differentiable programming.
## [1] "Contoh cara kerja Neural Network di TensorFlow"
TensorFlow di-develop oleh Google Brain Team.
Apa itu KERAS?
Keras is an open-source library that provides a Python interface for artificial neural networks. Keras acts as an interface for the TensorFlow library.
Walaupun keduanya ditulis dalam Python, tapi kini kita bisa menggunakannya di R.
Cara Kerja
Sekarang saya akan mencoba menjelaskan cara kerja saya dalam membuat algoritma supervised learning ini.
Train Dataset dan Test Dataset
Dari 31 buah poto yang saya kumpulkan tersebut, saya akan gunakan 25
poto sebagai train dataset dan 6 sisanya menjadi test dataset.
Penentuan poto mana saja yang masuk ke dalam train dan test dipilih
secara acak dengan menggunakan prinsip random number generator di
R. Oleh karena proporsi poto NutriSari dan bukan NutriSari
hampir 50-50, maka saya rasa pengacakan adalah hal yang bisa dilakukan.
Berbeda hal jika data yang kita miliki tidak balance (hal ini bisa
jadi pembahasan di kemudian hari yah).
Train dataset yang saya gunakan adalah poto-poto berikut ini:

Diharapkan algoritma neural network yang saya buat bisa mengenali poto
mana yang NutriSari dan poto mana yang bukan NutriSari.
Sedangkan test dataset akan saya jadikan sebagai alat validasi dari performa algoritma yang saya buat.
Berikut poto-poto yang termasuk ke dalam test dataset:

Pre Processing: Data Preparation
Sama halnya seperti data lainnya, data berbentuk gambar atau poto juga harus disiapkan dulu (data preparation).
Jadi perlakuan data gambar dengan data lain seperti numerik atau teks sama saja yah!
Apa saja yang harus disiapkan? Hal paling umum dilakukan adalah dengan
resizing poto ke ukuran yang sama. Jadi jika kalian menyadari, poto
yang saya jadikan dataset ini memiliki ukuran pixel size yang
berbeda-beda. Oleh karena itu, saya akan mengubah semua poto tersebut ke
ukuran yang sama, yakni: 28 x 28 pixels.
Proses resizing saya lakukan tetap di R dengan memanfaatkan
function resize() di library(EBImage). Praktis kan? Gak perlu
software lain lagi. hehe
Selanjutnya poto tersebut dibaca ke dalam bentuk matriks seperti yang
telah saya tunjukkan sebelumnya. Matriks tersebut diperkaya dengan label
0 untuk bukan NutriSari dan 1 untuk NutriSari.
Pembuatan Algoritma
Pada algoritma ini, saya akan membuat 3 buah layers. Layer pertama
berisi 256 nodes, layer kedua berisi 128 nodes, dan layer
terakhir berisi 2 nodes. Activation functions yang saya gunakan
adalah ReLU pada 2 layers pertama dan softmax pada layer
terakhir.
# model = keras_model_sequential()
# model %>%
# layer_dense(units = 256, activation = 'relu', input_shape = c(2352)) %>%
# layer_dense(units = 128, activation = 'relu') %>%
# layer_dense(units = 2, activation = 'softmax')
Optimizer-nya jadi rahasia dapur yah. hehe
Bagaimana menentukan banyaknya nodes dan jenis activation function yang sebaiknya digunakan?
Sepengetahuan saya memang harus dicoba-coba terlebih dahulu. Mana yang memberikan performa terbaik. cmiiw
Performa Algoritma
Sekarang kita lihat performa algoritma yang saya buat menggunakan train dataset di atas:
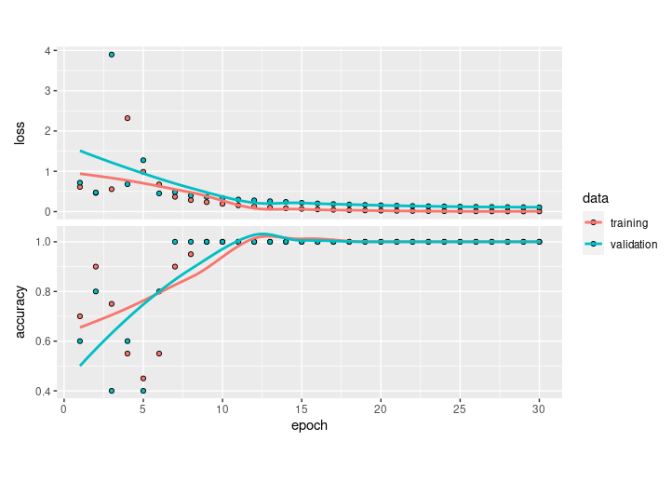
Jika dilihat akurasinya nyaris sempurna. Loss yang dihasilkan juga sangat kecil.
Saat saya cross dengan test dataset, performa algoritmanya juga
konsisten. Ia berhasil menebak mana yang NutriSari mana yang bukan
NutriSari.
Momen Of Truth
Dari model di atas, sekarang gilirannya moment of truth. Saya akan
mengetes packaging Herbalice ke dalam model tersebut. Bagaimana
hasilnya?
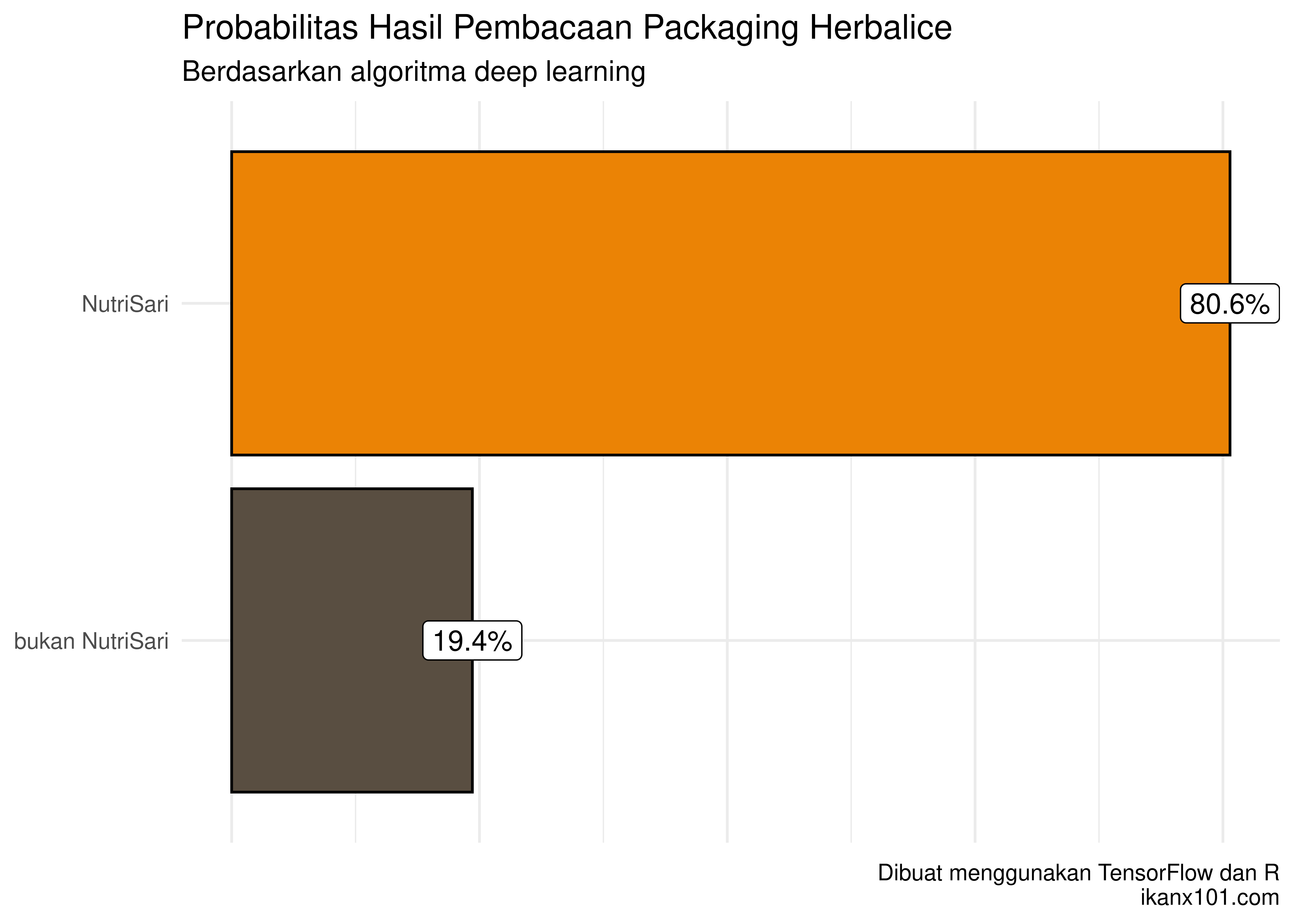
Ternyata algoritma saya membaca packaging Herbalice sebagai
NutriSari dengan peluang sebesar 80.6%.
Dugaan awal saya terbukti.
Notes
Tulisan ini dibuat untuk educational purposes only.
Dukung selalu blog ini agar bisa terus bertumbuh dengan cara klik iklan selepas Kamu membaca setiap tulisan yang ada yah.