
Beberapa Analisa Lain yang Bisa Diaplikasikan pada Geo Marketing
Beberapa minggu belakangan, beberapa departemen meminta kepada saya untuk melakukan web scraping beberapa kategori point of interest dari Google Maps dan Google Places. Tujuan mereka sederhana, yakni:
Menentukan area atau POI mana yang harus digarap pada tahun ini. Syukur-syukur penggarapan ini akan meningkatkan omset perusahaan.
Setelah saya scrape dan berikan data kepada mereka, artinya sudah menjadi kewajiban mereka untuk menentukan area dan POI mana yang harus digarap. Lantas bagaimana caranya? Jujurly, saya kurang mengetahui hal tersebut tapi saya yakin mereka sudah punya pakem tersendiri.
Sampai saat ini, saya sudah menuliskan 12 posts di blog saya ini terkait geo marketing. Jika saya hendak membantu rekan-rekan di kantor untuk menentukan area dan POI yang hendak digarap, apakah bisa digunakan cara seperti yang pernah saya tulis dari salah satu dari 12 posts tersebut? Jawabannya TENTU BISA!.
Saya pernah menuliskan beberapa analisa di geo marketing yang bisa jadi basis pengambilan keputusan tersebut.
Nah, pada post kali ini saya akan melakukan beberapa alternatif analisa lain yang belum pernah saya lakukan sebelumnya pada topik geo marketing. Beberapa analisa ini sebenarnya sudah pernah saya lakukan di topik lainnya tapi ternyata works well juga di geo marketing.
Rekan-rekan bisa melihat setiap analisa yang kelak saya tuliskan di bawah sebagai analisa-analisa yang terpisah sehingga tidak ada kewajiban untuk disangkutpautkan sama sekali antar hasilnya.
Sebagai contoh, saya akan melakukan analisa untuk POI berupa tempat makan kategori tertentu di Kota Surabaya, tepatnya di Kecamatan Gubeng dan Genteng.
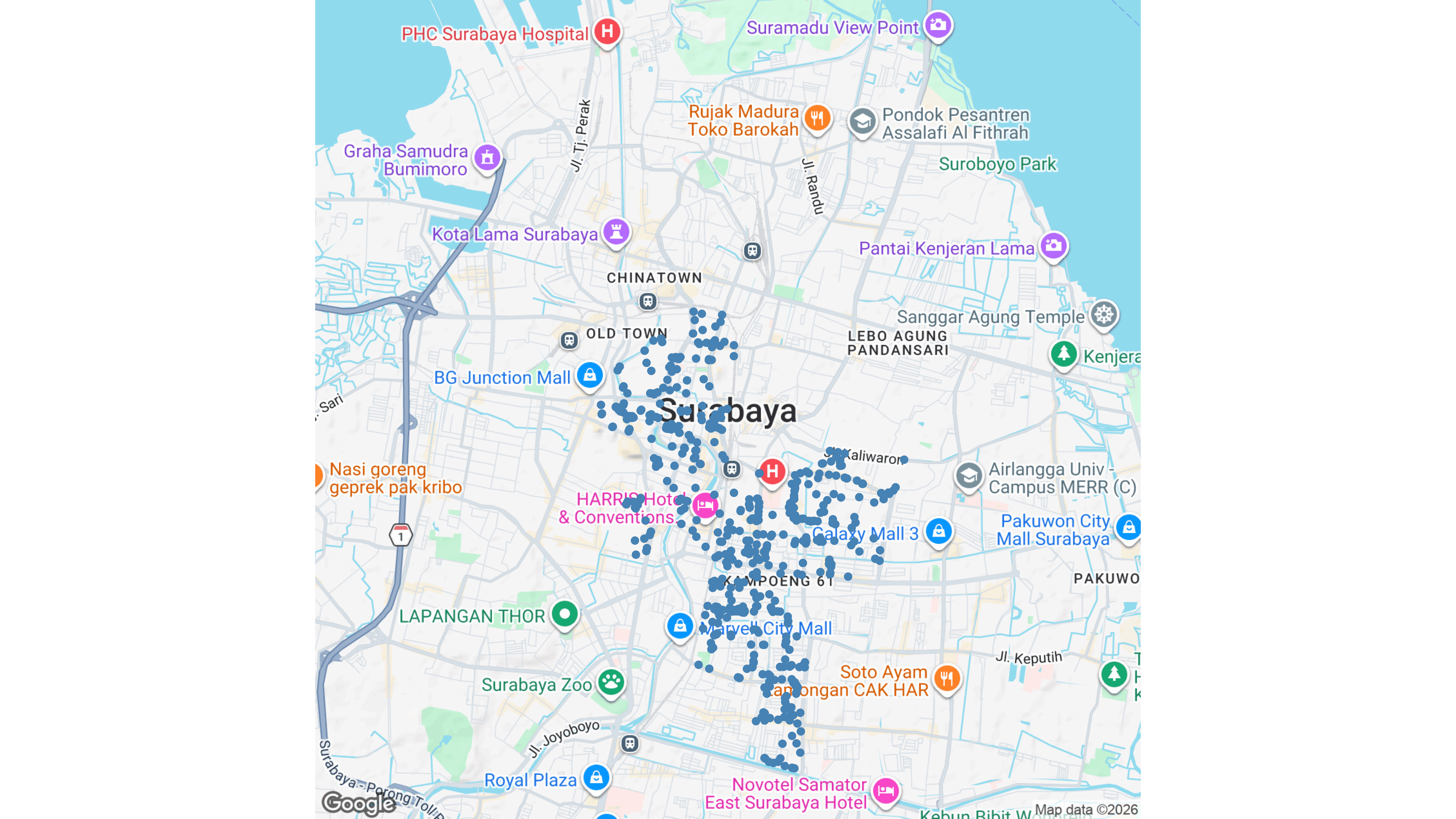
Apa saja analisanya? Cekidot!
Alternatif Analisa I: Kuadran Rating vs User
Analisa pertama yang hendak saya lakukan sebenarnya sangat sederhana, yakni cukup dengan membuat scatter plot antara rating dan berapa banyak user yang memberikan rating. Tujuannya adalah memetakan tempat makan mana yang termasuk ke dalam kuadran-kuadran sebagai berikut:
| Review sedikit | Review Banyak | |
|---|---|---|
| Rating tinggi | The Hidden gems | The Populars |
| Rating rendah | The Under performers | The Public critics |
Dari peta ini, tentu strategi yang dijalankan per masing-masing kuadran akan berbeda. Mari kita lihat plot pertama sebagai berikut ini:
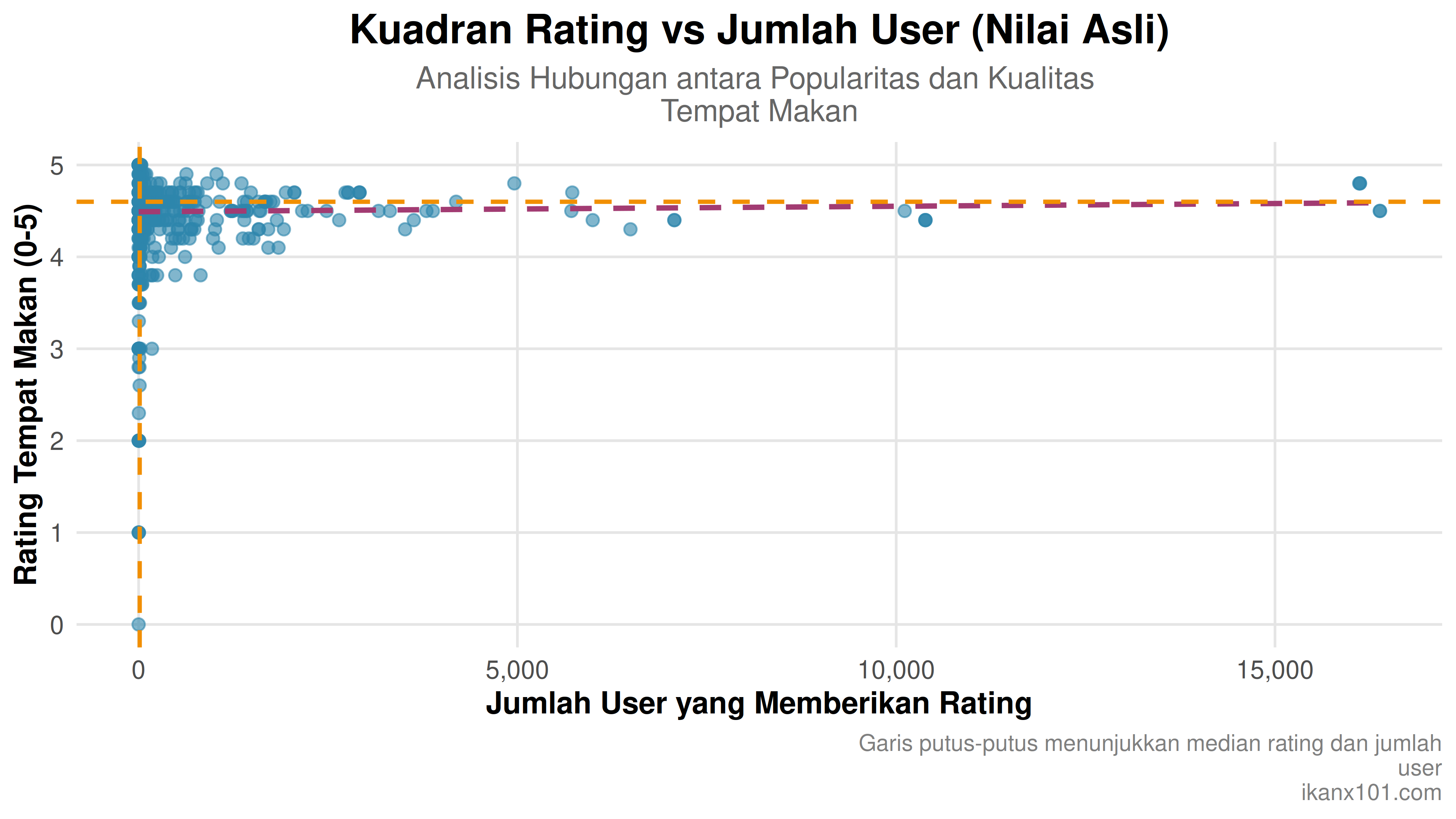
Kita bisa melihat bahwa kuadran yang dihasilkan secara visual sangat mepet dan tidak tersebar secara proporsional. Hal ini terjadi karena range dari data banyaknya user yang memberikan rating sangat jauh besar dan skewed ke salah satu sisi. Oleh karena itu, saya bisa melakukan transformasi dengan menggunakan fungsi logaritmik. Berikut adalah grafik kedua:
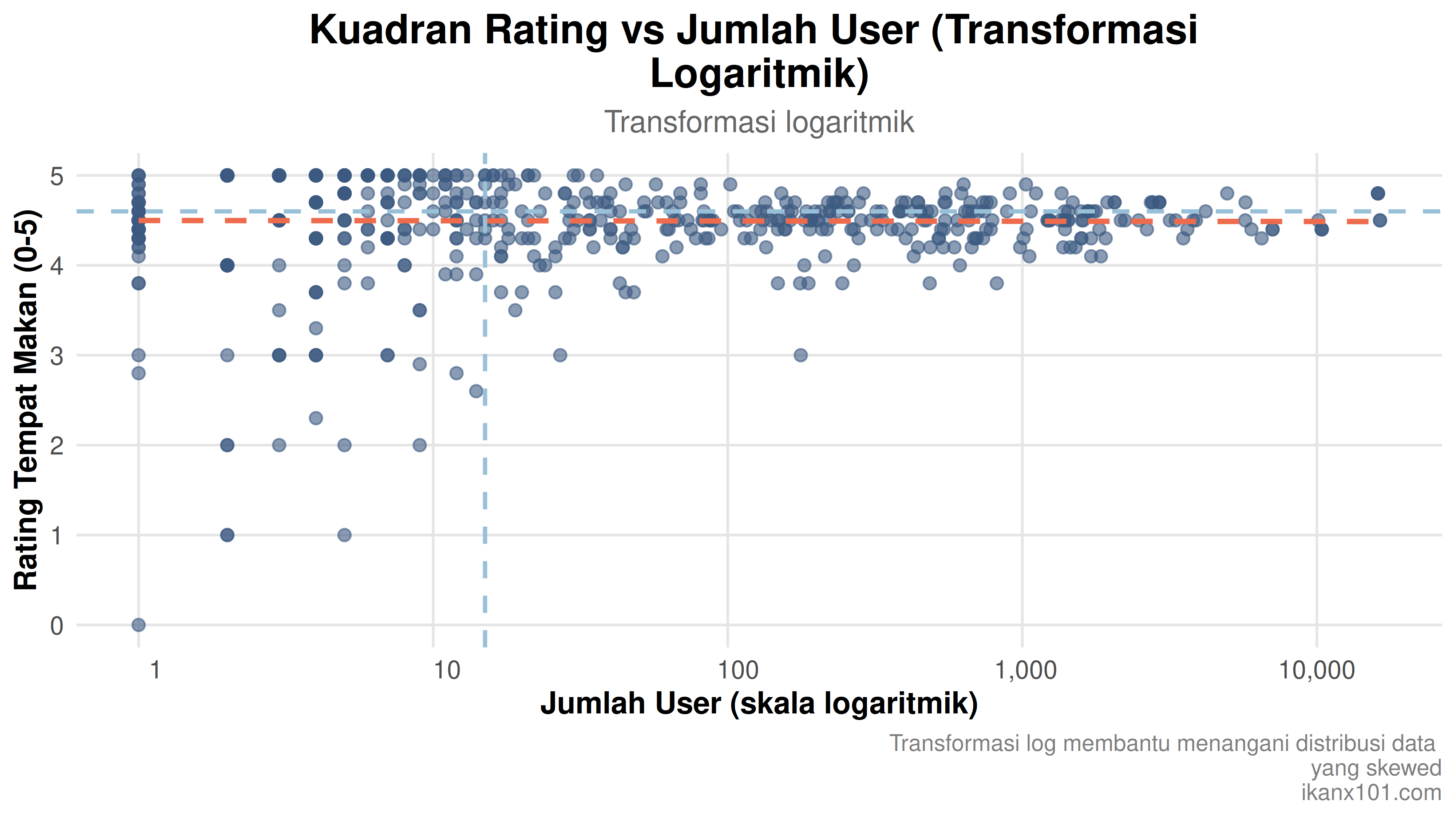
Setelah ditransformasi, sumbu x sudah relatif menyebar rata tapi data pada rating yang masih skewed. Jika dibuat kuadran, maka bentuknya seperti ini:
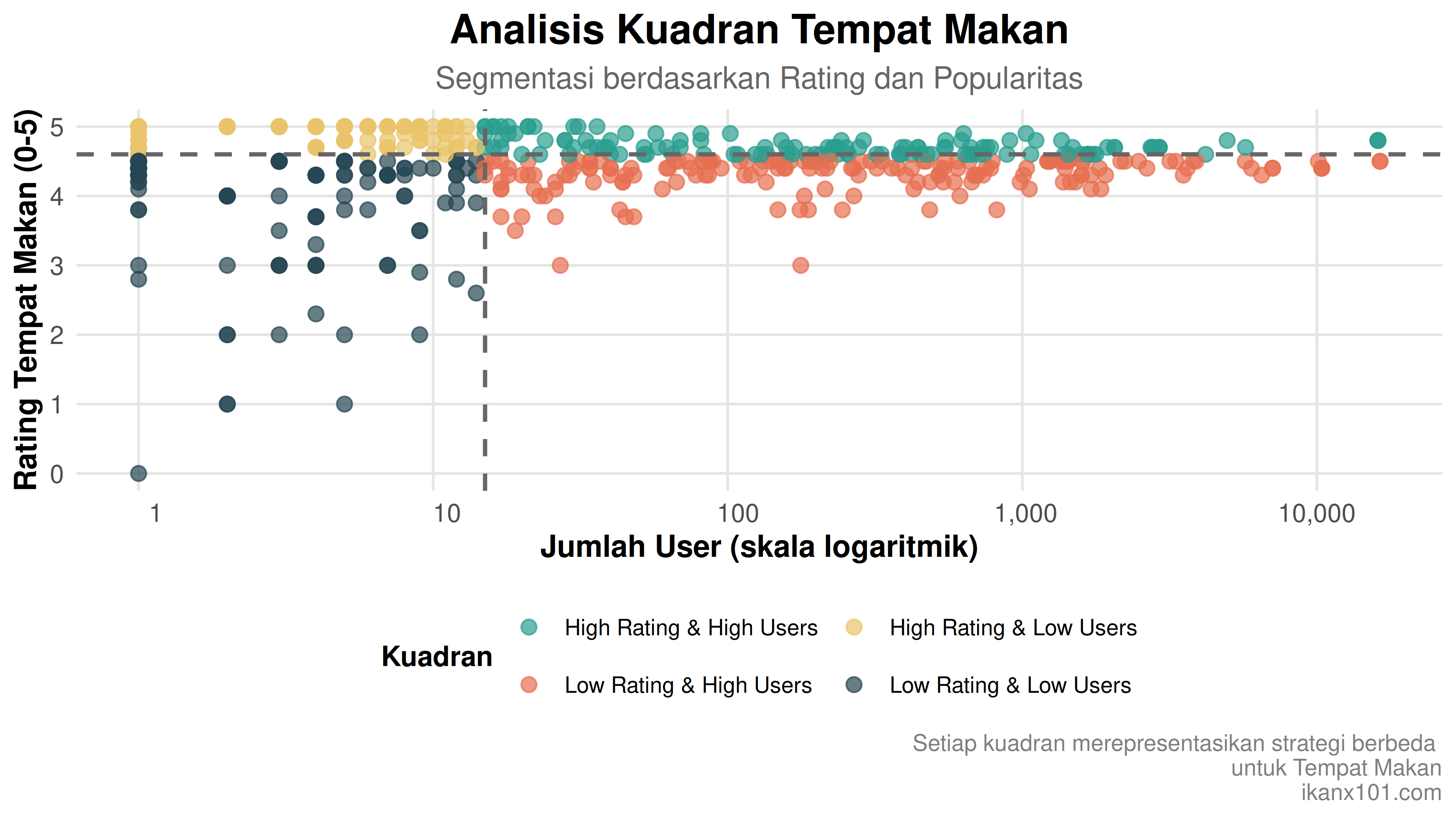
| kuadran | n | percent |
|---|---|---|
| High Rating & High Users | 134 | 21.7% |
| High Rating & Low Users | 185 | 30.0% |
| Low Rating & High Users | 180 | 29.2% |
| Low Rating & Low Users | 118 | 19.1% |
| Total | 617 | - |
Dari analisa ini, tim terkait bisa memilih kuadran tertentu sebagai target POI yang hendak diajak kerja sama.
TAPI menurut keyakinan saya, untuk data dengan rentang yang terlalu mepet atau terlalu lebar dan tergambarkan sebagai skewed distribution, alternatif analisa ini bisa menimbulkan bias dan kurang tepat untuk digunakan.
Alternatif Analisa II: Spatial Clustering >< K-Means Clustering
Pada analisa ini, saya akan melakukan dua teknik clustering yang berbeda, yakni:
- DBscan untuk mengelompokkan tempat-tempat makan yang berdekatan di suatu area berdasarkan data longlat-nya.
- K-Means untuk mengelompokkan tempat-tempat makan berdasarkan rating dan berapa banyak user yang memberikan rating.
Tujuannya adalah menjawab pertanyaan berikut ini:
- Apakah tempat-tempat makan dengan rating tinggi cenderung berkumpul di area elit tertentu?
- Apakah ada pusat kuliner baru yang terbentuk secara organik?
Berikut adalah summary hasilnya:
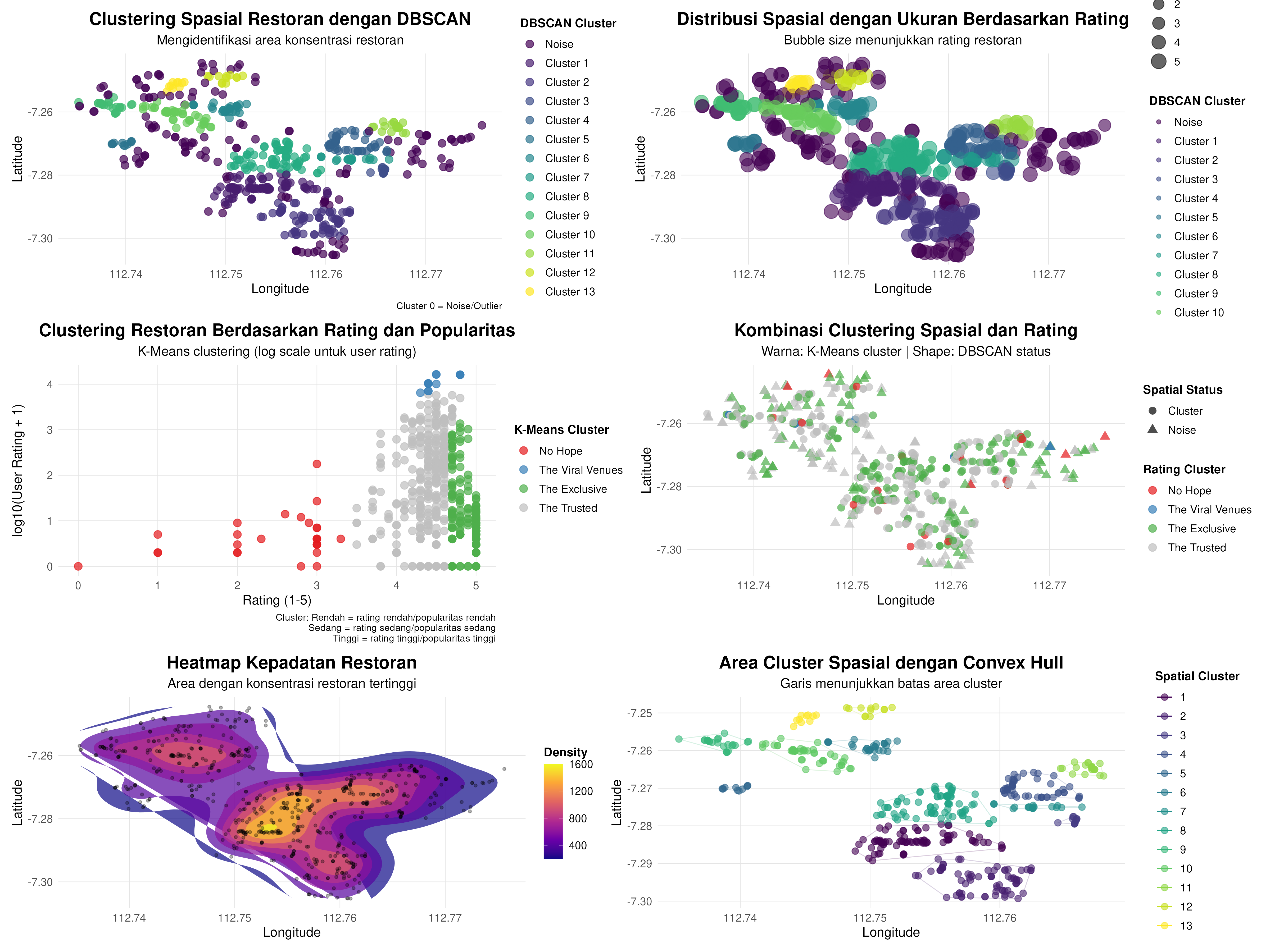
- Ada 13 clusters spasial plus 1 noise cluster spasial.
- Ada empat clusters berdasarkan rating dan berapa banyak user yang memberikan rating. Cluster The Viral Venues dan The Exclusive akan menjadi poin penting untuk menentukan area spasial kelak.
| kmeans_cluster_label | n_restoran | avg_rating | avg_user_rating | median_rating | median_user_rating | prop_high_rating | prop_popular |
|---|---|---|---|---|---|---|---|
| No Hope | 27 | 2.433333 | 10.74074 | 2.90 | 3 | 0.0000000 | 0.0370370 |
| The Viral Venues | 12 | 4.516667 | 11918.91667 | 4.45 | 10386 | 0.5000000 | 1.0000000 |
| The Exclusive | 245 | 4.904490 | 67.17551 | 5.00 | 4 | 1.0000000 | 0.1224490 |
| The Trusted | 333 | 4.358859 | 521.83784 | 4.40 | 83 | 0.4684685 | 0.4804805 |
Sekarang kita akan menjawab kedua pertanyaan yang ada dari grafik dan perhitungan yang sudah saya lakukan.
Apakah restoran dengan rating tinggi cenderung berkumpul di area elit tertentu?
Perhatikan grafik berikut ini:
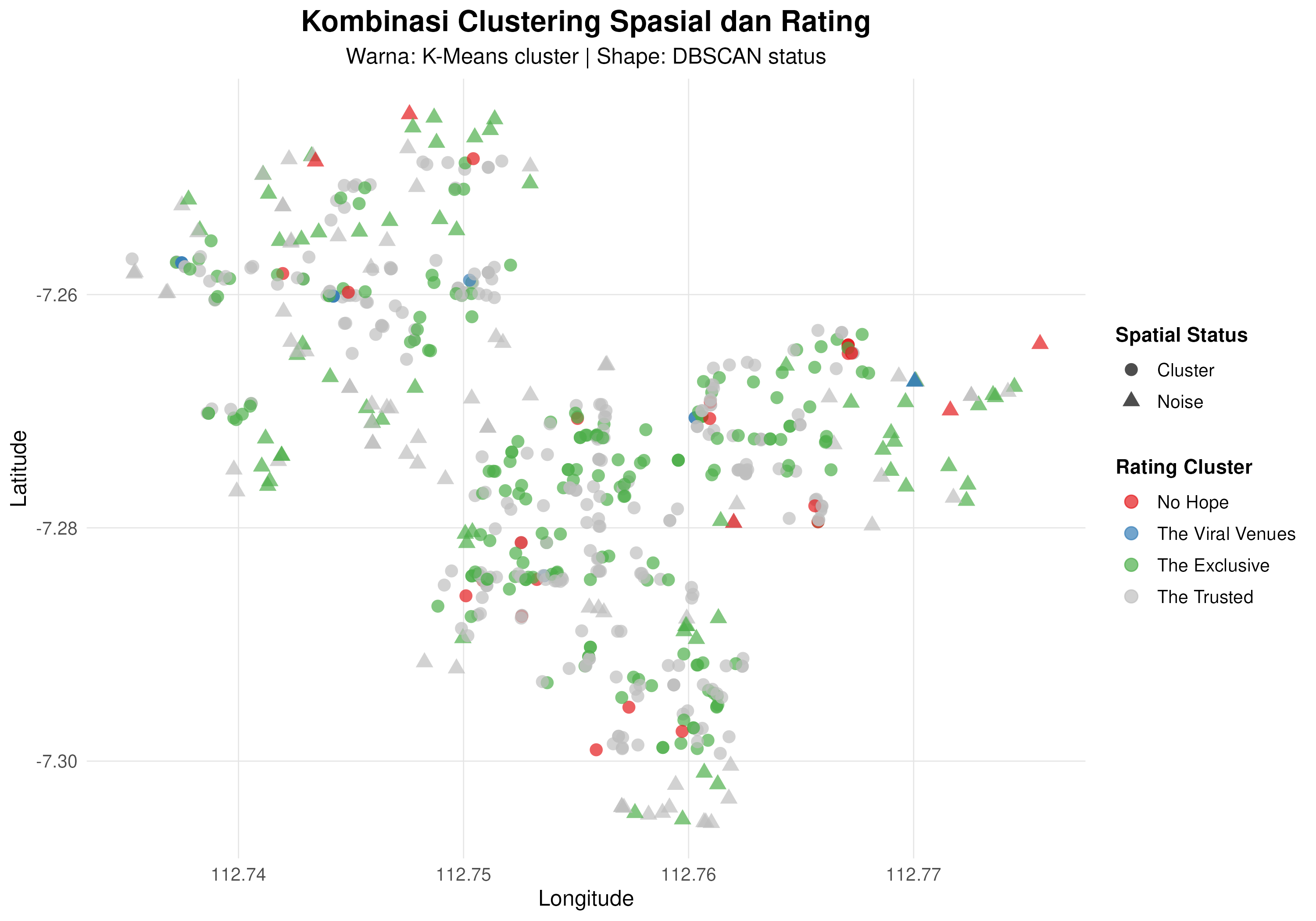
Plot ini adalah gabungan dari analisa clustering spatial dengan clustering berdasarkan rating dan user. Jika tempat-tempat makan yang termasuk ke dalam the Viral Venues dan the Exclusive terkonsentrasi di area spasial tertentu, itu mengindikasikan suatu area termasuk ke dalam elit. Untuk menentukannya, saya akan membuat skor dengan membobotkan proporsi jenis tempat makan yang ada.
Bobot tertinggi untuk tempat makan the Viral Venues, kemudian the Exclusive, lalu the Trusted. Sebagai contoh, bobot yang saya gunakan tergantung dari keyakinan saya ya.
| dbscan_cluster | No Hope | The Viral Venues | The Exclusive | The Trusted | Total | skor |
|---|---|---|---|---|---|---|
| 9 | 0.0% | 12.5% | 33.3% | 54.2% | 100.0% | 85.42 |
| 5 | 0.0% | 0.0% | 63.6% | 36.4% | 100.0% | 81.82 |
| 4 | 4.0% | 4.0% | 44.0% | 48.0% | 100.0% | 76.00 |
| 8 | 1.2% | 0.0% | 51.2% | 47.5% | 100.0% | 75.00 |
| 0 | 3.4% | 1.4% | 42.8% | 52.4% | 100.0% | 71.72 |
| 10 | 4.5% | 6.8% | 27.3% | 61.4% | 100.0% | 71.59 |
| 7 | 0.0% | 0.0% | 42.1% | 57.9% | 100.0% | 71.05 |
| 6 | 0.0% | 3.4% | 27.6% | 69.0% | 100.0% | 68.97 |
| 2 | 4.2% | 0.0% | 40.3% | 55.6% | 100.0% | 68.06 |
| 1 | 5.7% | 1.1% | 36.8% | 56.3% | 100.0% | 67.24 |
| 13 | 0.0% | 0.0% | 30.0% | 70.0% | 100.0% | 65.00 |
| 12 | 8.3% | 0.0% | 25.0% | 66.7% | 100.0% | 58.33 |
| 11 | 27.3% | 0.0% | 40.9% | 31.8% | 100.0% | 56.82 |
| 3 | 16.7% | 0.0% | 8.3% | 75.0% | 100.0% | 45.83 |
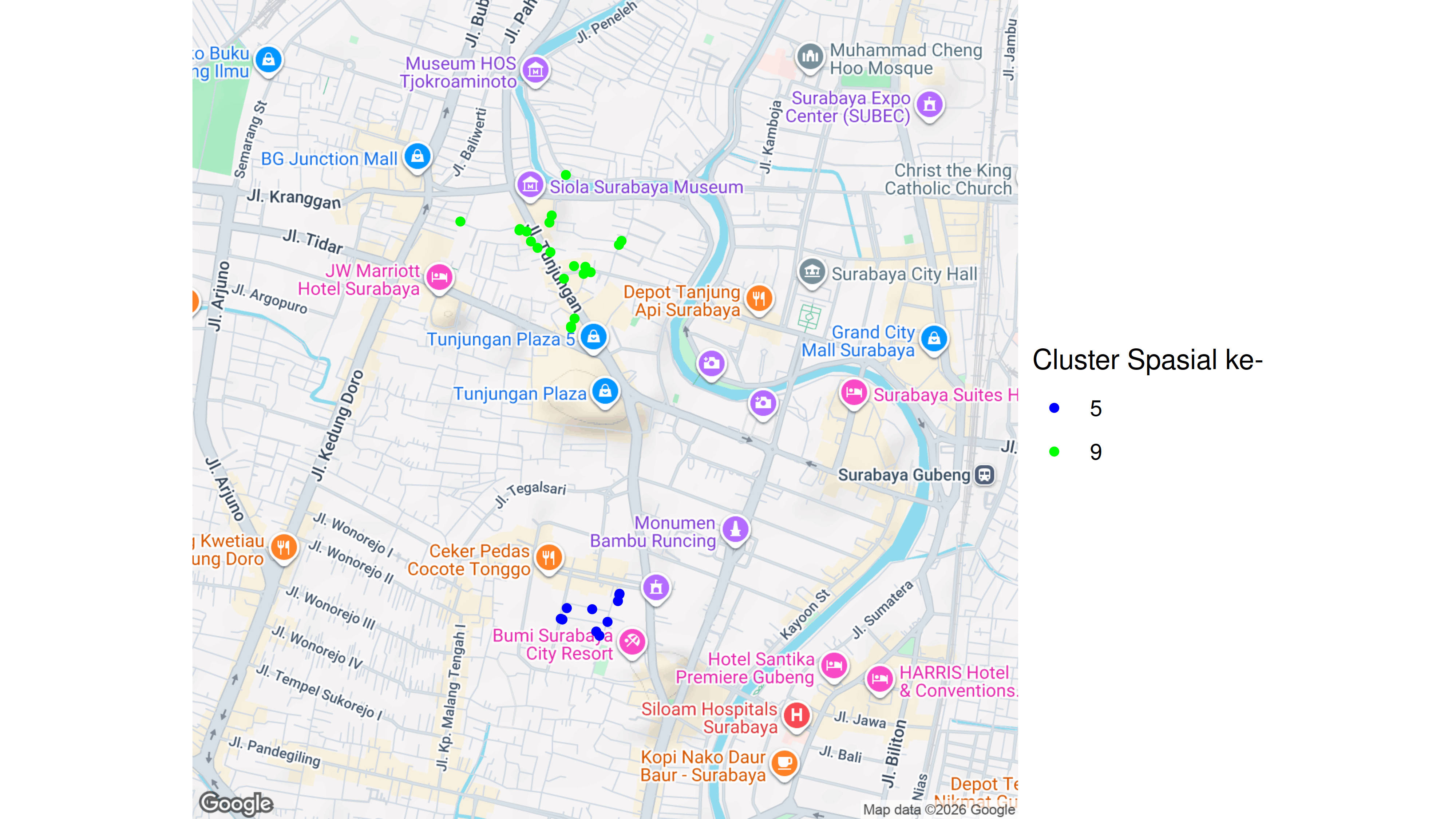
Saya dapatkan cluster spasial ke 5 dan 9 memiliki skor tertinggi, yakni mereka yang berada pada:
Apakah ada pusat kuliner baru yang terbentuk secara organik?
Saya akan membuat definisi tempat makan baru berdasarkan banyak user yang memberikan rating. Jika “sedikit”, maka saya asumsikan tempat makan tersebut merupakan tempat makan baru. Berikut ini adalah cluster spasial yang memiliki tempat-tempat makan baru terbanyak di antara clusters yang lain:
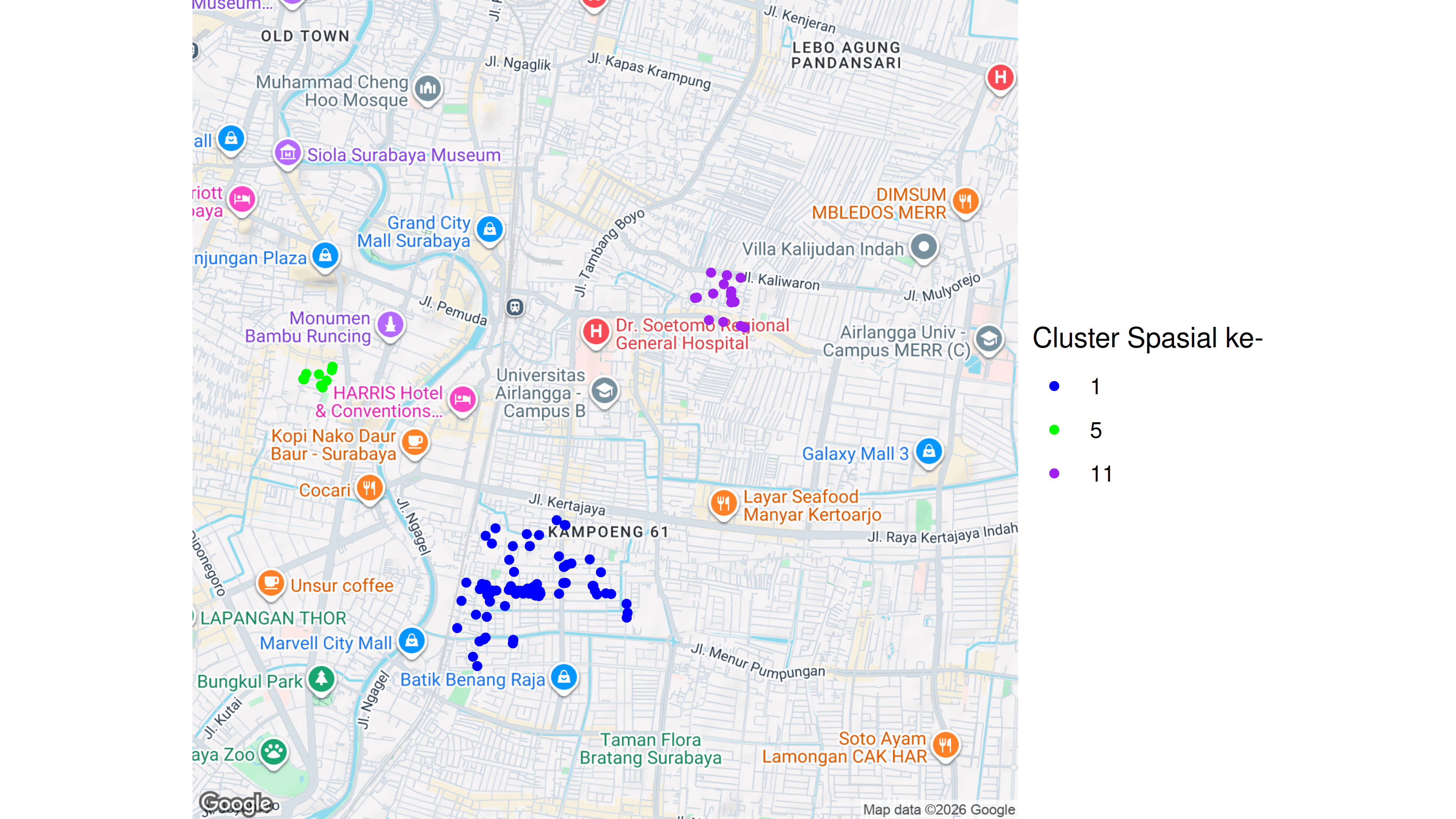
Dari analisa alternatif ini, saya bisa mendapatkan beberapa area yang bisa digarap dengan definisi yang sudah saya tentukan. Tentunya definisi ini bisa disesuaikan dengan kebutuhan yang diperlukan (jika mau).
Alternatif Analisa III: Koreksi Bayesian Rating
Menurut keyakinan saya, jika ada dua tempat makan yang:
- Punya rating 5 dari penilaian 50 orang user.
- Punya rating 5 dari penilaian 1.000 orang user.
punya derajat (atau rating) yang berbeda. Lebih banyak user yang memberikan rating membuat derajat kepercayaan atas penilaian lebih tinggi. Lantas agar rating yang digunakan fair enough, apa yang harus saya lakukan? Saya akan melakukan perhitungan Bayesian Rating Correction untuk mendapatkan estimasi rating yang lebih fair memanfaatkan informasi prior berupa rata-rata rating tempat makan populasi data saya.
Konsep Bayesian Rating adalah menggabungkan informasi dari rating individu dengan prior untuk mendapatkan rating yang lebih akurat. Saya pernah menuliskan beberapa topik terkait analisa Bayesian di blog saya.
Untuk melakukan koreksi ini, saya hanya akan memilih tempat makan yang memiliki rating dengan banyaknya user lebih dari 30 orang. Kenapa? Karena jika terlalu kecil, koreksi yang dihasilkan punya error lebih tinggi.
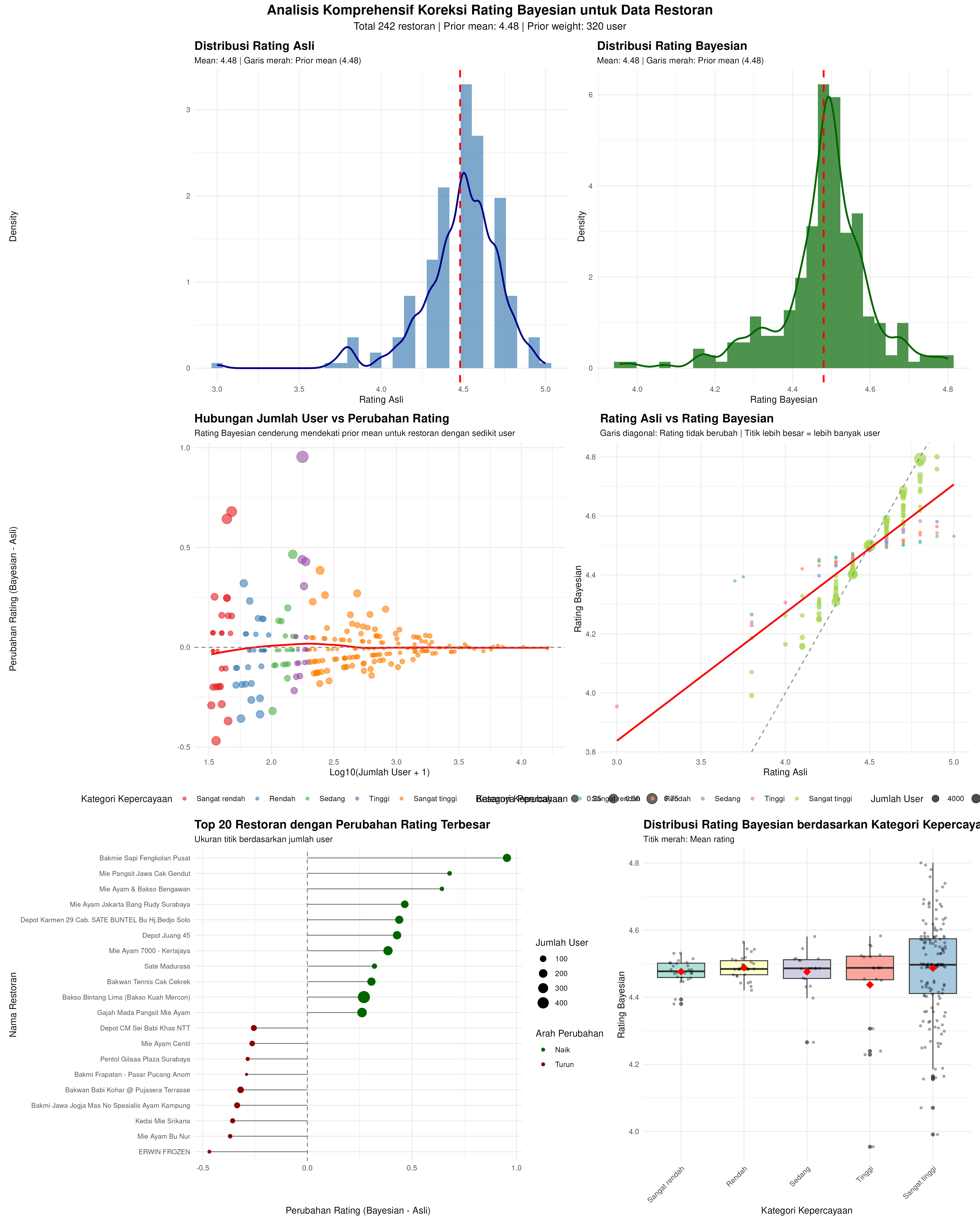
Dari 242 tempat makan yang saya proses, saya mendapatkan mean rating original sebesar 4.479959. Setelah dikoreksi, mean rating Bayesian-nya menjadi 4.480827. Terlihat tidak ada perubahan yang signifikan dari nilai mean-nya namun sebaran data hasil koreksi menjadi lebih compact di mana standar deviasinya berubah dari original 0.2469339 menjadi Bayesian 0.12283.
Ada satu hal yang perlu saya sampaikan juga: tempat makan dengan user yang lebih banyak memberikan hasil confidence pengoreksian yang lebih tinggi juga. Maka dari itu, saya coba kategorikan tiap tempat makan menjadi kelompok:
- Confidence koreksi sangat rendah, tempat makan dengan user 30 - 50 orang.
- Confidence koreksi rendah, tempat makan dengan user 50 - 100 orang.
- Confidence koreksi sedang, tempat makan dengan user 100 - 150 orang.
- Confidence koreksi tinggi, tempat makan dengan user 150 - 200 orang.
- Confidence koreksi sangat tinggi, tempat makan dengan user di atas 200 orang.
Grafik di atas menampilkan perubahan rating signifikan (baik meningkat atau turun) yang dialami oleh beberapa tempat makan. Sedangkan tabel berikut ini adalah top 10 tempat-tempat makan yang memiliki rating tertinggi hasil koreksi:
| nama | original_rating | bayesian_rating | user_count | confidence_category |
|---|---|---|---|---|
| Mie Bakar dan Sego Ndogimbal Berjaya | 4.9 | 4.800406 | 1028 | Sangat tinggi |
| Wizzmie - Tunjungan | 4.8 | 4.793779 | 16118 | Sangat tinggi |
| Ikon All You Can Eat | 4.8 | 4.780628 | 4959 | Sangat tinggi |
| ABADI Bakmi & Kopi - Embong Tanjung | 4.9 | 4.758808 | 631 | Sangat tinggi |
| Mie Mapan Plaza Surabaya | 4.8 | 4.739044 | 1358 | Sangat tinggi |
| RUI Noodle Bar - Dharmahusada | 4.8 | 4.728569 | 1112 | Sangat tinggi |
| Bakmi Bintang Palu | 4.8 | 4.716562 | 906 | Sangat tinggi |
| Kopitiam Shantui | 4.8 | 4.691162 | 620 | Sangat tinggi |
| Soto Ayam “Cak To” Undaan Wetan | 4.7 | 4.688367 | 5724 | Sangat tinggi |
| Warung NOW | 4.8 | 4.682129 | 548 | Sangat tinggi |
Alternatif Analisa IV: Analisis Hubungan Jarak dan Kualitas (Spatial Correlation)
Tujuan dari analisa ini adalah:
- Apakah tempat-tempat makan yang letaknya berdekatan cenderung memiliki rating yang mirip?
- Apakah kualitas tempat makan menular ke sebelahnya?
Untuk analisa ini, saya menggunakan perhitungan jarak real dari Openstreetmaps pada mode berjalan kaki. Kemudian dua tempat makan disebut berdekatan jika jaraknya maksimum 50 meter berjalan kaki. Perlu saya akui bahwa proses membentuk matriks jarak antar tempat makan menggunakan Openstreetmaps membutuhkan waktu yang sangat amat lama.
Dari hampir enam ratus data tempat makan yang ada, saya mendapatkan xx pasang tempat makan yang masuk ke dalam definisi berdekatan. Jika saya hitung korelasi rating antar kedua tempat makan yang berdekatan, saya dapatkan:
Restoran yang Berdekatan (<50 m):
- Jumlah pasangan: 274
- Korelasi rating = -0.003
- Rata-rata selisih rating: 0.491
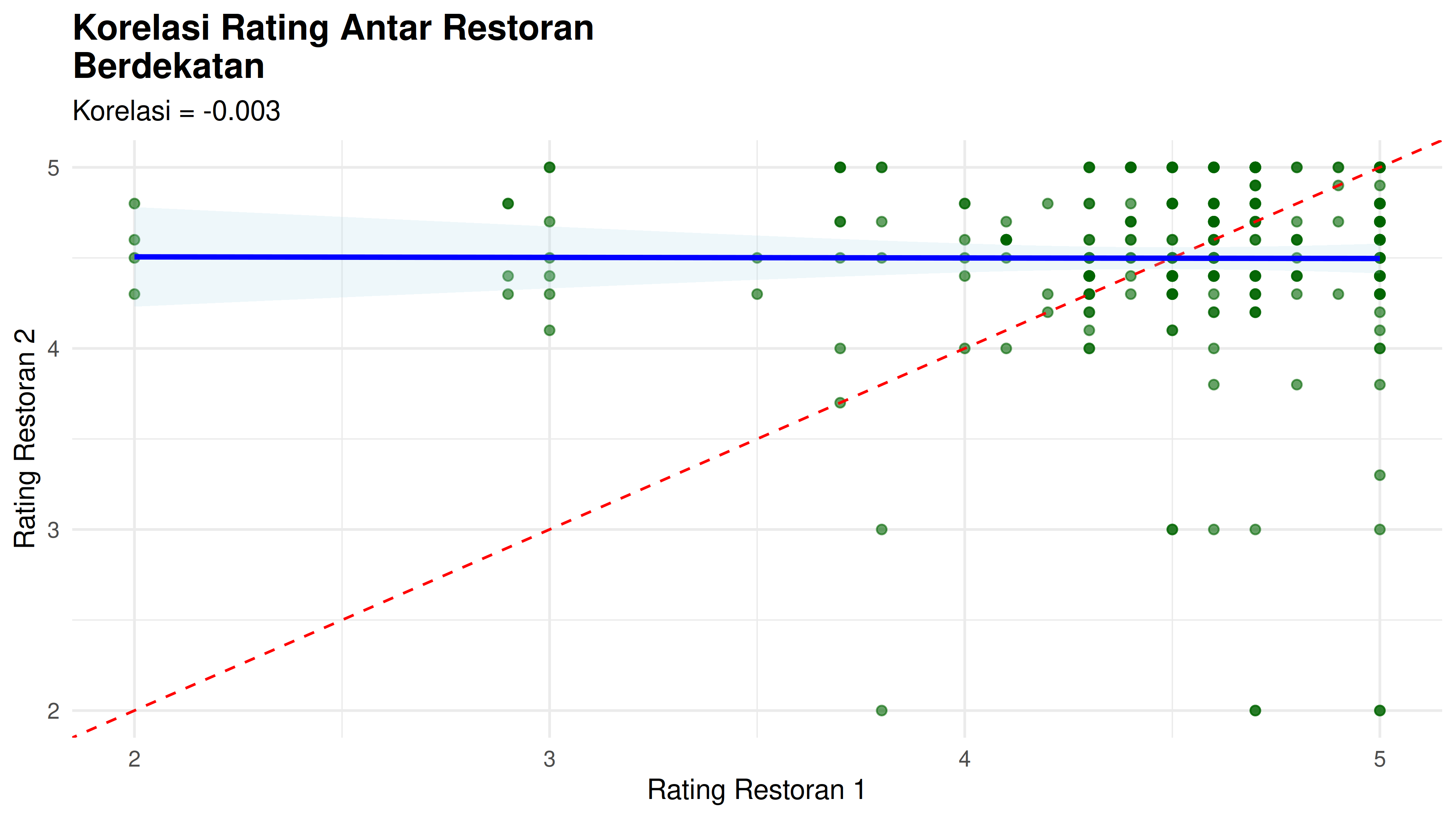
Ternyata tidak ada korelasi antara rating dari dua tempat makan berdekatan yang berjarak maksimum 50 meter.
Hasil Moran Test juga menunjukkan tidak ada pola spasial yang signifikan dalam distribusi rating.
Jadi kedua pertanyaan bisnis di atas bisa kita jawab dengan tegas bahwa kualitas restoran tidak dipengaruhi oleh lokasi tetangga.
Alternatif Analisa V: Analisis Anomali
Tujuan dari analisa ini adalah mencari tempat makan yang melawan arus di wilayahnya.
Saya mendefinisikan radius pencarian “tetangga” dari suatu tempat makan sebesar 400 meter dan satu neighborhood harus berisi minimal 20 tempat makan. Kemudian saya definisikan juga tempat makan disebut dengan anomali saat rating-nya memiliki perbedaan rating minimal 0.8 dari rating rata-rata di neighborhood tersebut.
Berdasarkan definisi tersebut, saya mendapatkan ada tujuh tempat makan yang melawan arus. Berikut adalah grafik yang menandakan perbedaan rating ketujuh tempat makan tersebut dengan rating rata-rata di neighborhood-nya:

Berikut adalah heatmap berdasarkan longlat dan rata-rata rating wilayah:
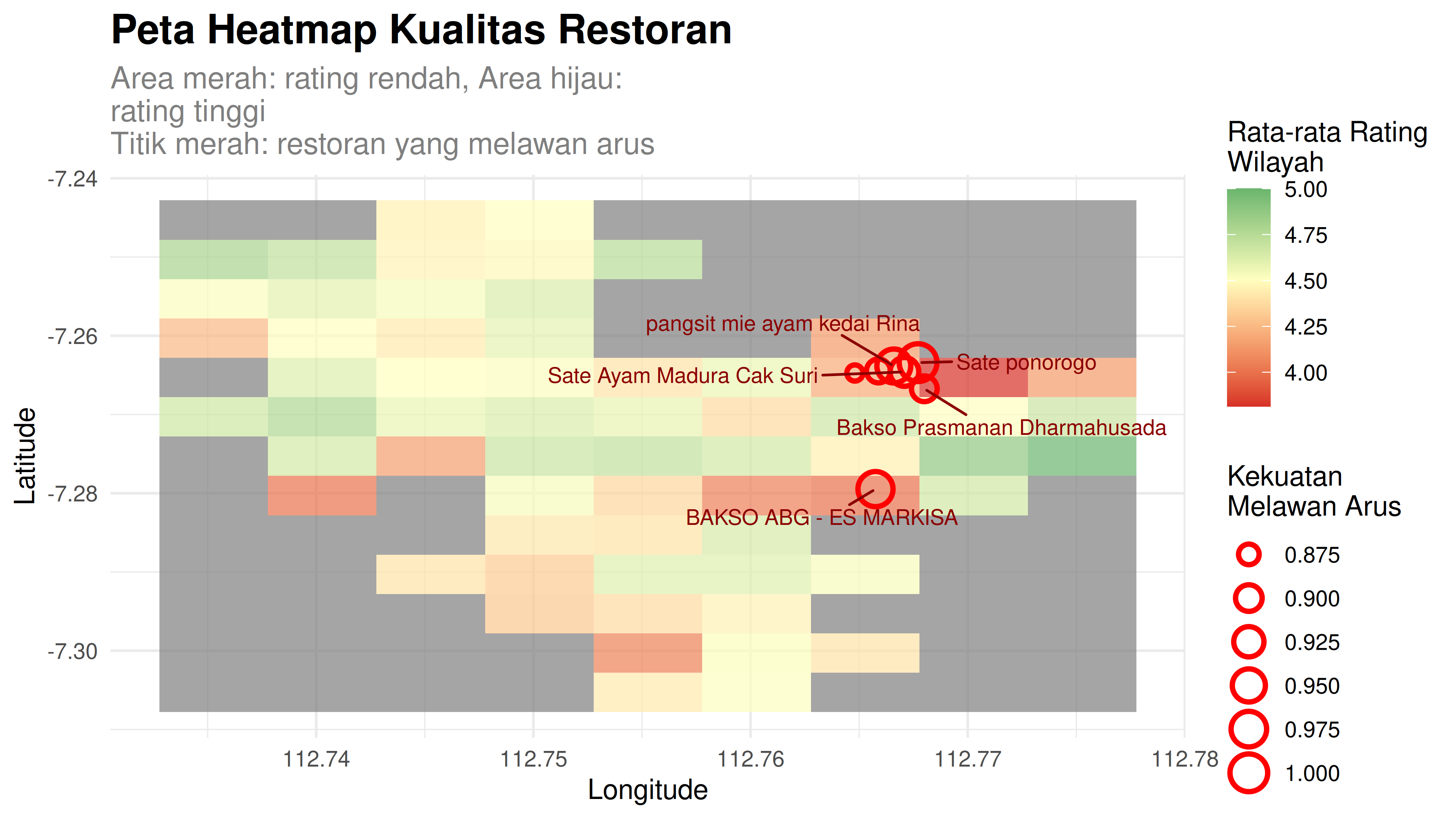
Dari analisa ini, kita bisa mengubah asumsi-asumsi yang saya gunakan tadi untuk mendapatkan tempat makan yang melawan arus.
EPILOG
Dari lima alternatif analisa yang saya tuliskan di atas, kita bisa memilih satu atau lebih analisa dengan tujuan yang tentunya berbeda-beda tergantung kebutuhan. Perlu saya ingatkan kembali bahwa analisa ini murni berdasarkan data terbatas seperti longlat, rating, dan banyaknya user yang memberikan rating. Sedangkan pada kondisi real, ada banyak data yang tak tergambarkan dari analisa ini.