
Belajar Time Series Forecasting dengan Deep Learning menggunakan TensorFlow di Google Colab
Pada beberapa tulisan sebelumnya, saya telah memberikan dua tutorial melakukan regresi dan klasifikasi dengan deep learning (alias ANN). Pada tulisan kali ini, saya hendak memberikan tutorial untuk melakukan time series forecasting menggunakan deep learning.
Ternyata setelah saya cek, saya belum pernah menuliskan hal teknis terkait time series di blog saya sama sekali. Satu-satunya tulisan saya terkait time series adalah sharing pengalaman saya membuat metode forecast “baru” yang bisa menghemat inventory cost senilai Rp 8 miliar.
Bagi rekan-rekan yang belum mengetahui apa itu time series, rekan-rekan silakan Googling terkait hal tersebut ya.
Pada tulisan ini, saya akan menggunakan salah satu data omset bulanan
asli yang saya dapatkan dari rekan kuliah saya. Data omset bulanan
tersebut bisa dipandang sebagai data time series. Saya akan mencoba
membuat model forecast dari data tersebut dengan metode
long-short-term memory (lstm) di ANN.
Berikut adalah tutorialnya:
TAHAP I
Saya ambil data yang diperlukan sebagai berikut:
# dimulai dari hati yang bersih
rm(list=ls())
# memanggil semua libraries yang diperlukan
library(dplyr)
library(tidyr)
library(caret)
library(keras)
library(tensorflow)
load("data.rda")
df_print %>% knitr::kable()
| bulan | tahun | omset |
|---|---|---|
| 1 | 2019 | 12.109286 |
| 2 | 2019 | 11.134998 |
| 3 | 2019 | 11.306951 |
| 4 | 2019 | 10.627735 |
| 5 | 2019 | 12.706164 |
| 6 | 2019 | 8.461056 |
| 7 | 2019 | 10.418129 |
| 8 | 2019 | 10.693386 |
| 9 | 2019 | 9.931742 |
| 10 | 2019 | 10.134906 |
| 11 | 2019 | 9.759191 |
| 12 | 2019 | 9.220283 |
| 1 | 2020 | 9.424254 |
| 2 | 2020 | 9.652470 |
| 3 | 2020 | 10.929961 |
| 4 | 2020 | 10.522224 |
| 5 | 2020 | 8.690728 |
| 6 | 2020 | 11.384340 |
| 7 | 2020 | 10.592765 |
| 8 | 2020 | 9.446511 |
| 9 | 2020 | 10.421095 |
| 10 | 2020 | 9.964756 |
| 11 | 2020 | 10.848913 |
| 12 | 2020 | 11.337345 |
| 1 | 2021 | 9.085644 |
| 2 | 2021 | 9.203892 |
| 3 | 2021 | 12.028427 |
| 4 | 2021 | 12.540642 |
| 5 | 2021 | 10.803806 |
| 6 | 2021 | 11.576041 |
| 7 | 2021 | 10.630560 |
| 8 | 2021 | 12.123444 |
| 9 | 2021 | 11.597485 |
| 10 | 2021 | 11.467759 |
| 11 | 2021 | 11.424983 |
| 12 | 2021 | 10.390359 |
| 1 | 2022 | 10.100890 |
| 2 | 2022 | 10.063320 |
| 3 | 2022 | 12.171718 |
| 4 | 2022 | 12.967401 |
| 5 | 2022 | 10.504940 |
| 6 | 2022 | 11.451804 |
| 7 | 2022 | 11.966286 |
| 8 | 2022 | 12.137978 |
| 9 | 2022 | 11.036515 |
| 10 | 2022 | 11.668166 |
| 11 | 2022 | 10.969599 |
| 12 | 2022 | 10.536972 |
| 1 | 2023 | 10.662826 |
| 2 | 2023 | 9.870124 |
| 3 | 2023 | 12.258235 |
| 4 | 2023 | 9.736901 |
| 5 | 2023 | 11.665639 |
Saya memiliki 53 baris data omset bulanan mulai dari Januari 2019
hingga Mei 2023.
TAHAP II
Saya akan gunakan prinsip 6 + 1, yakni data omset 6 bulan berurutan
untuk mem-forecast omset sebulan ke depannya.
Untuk itu, saya perlu membuat training dan target data yang sesuai.
# saya bikin 6 bulan untuk prediksi 1 bulan
n_bulan = 6
n_data = nrow(df)
n_ding = n_data - n_bulan
# membuat data input untuk training
input = data.frame(x1 = 0,
x2 = 0,
x3 = 0,
x4 = 0,
x5 = 0,
x6 = 0)
target = rep(0,n_ding)
# mulai iterasi untuk membuat data training
for(i in 1:n_ding){
save = df$omset[i:(i + n_bulan - 1)] %>% t() %>% list()
input[i,] = save[[1]]
target[i] = df$omset[i + n_bulan]
}
# berikut adalah tampilan hasilnya
head(input,5)
## x1 x2 x3 x4 x5 x6
## 1 12.10929 11.134998 11.306951 10.627735 12.706164 8.461056
## 2 11.13500 11.306951 10.627735 12.706164 8.461056 10.418130
## 3 11.30695 10.627735 12.706164 8.461056 10.418130 10.693386
## 4 10.62774 12.706164 8.461056 10.418130 10.693386 9.931742
## 5 12.70616 8.461056 10.418130 10.693386 9.931742 10.134906
head(target,5)
## [1] 10.418130 10.693386 9.931742 10.134906 9.759191
TAHAP III
Oleh karena data yang digunakan relatif sedikit, saya akan coba melakukan data augmentation dengan prinsip sederhana:
- Upsampling dari data yang ada.
- Buat random noise dari data tersebut.
# function untuk random noise
acak = function(n){
n + runif(1,min = -3,max = 3)
}
# berapa banyak upsampling yang akan dilakuka
n_aug = 700
# ambil id acak untuk upsampling
id_acak = sample(nrow(input),
n_aug,
replace = T) %>% sort()
# augment input
input_2 =
input %>%
mutate_all(acak)
# augment target
target_2 = sapply(target,acak)
# saya ambil yang acak id saja
input_2 = input_2[id_acak,]
target_2 = target_2[id_acak]
# gabung all untuk training
input = rbind(input,input_2)
target = c(target,target_2)
TAHAP IV
Saya ubah training dan target data menjadi bentuk matriks untuk membuat model deep learning di TensorFlow.
x = input %>% as.matrix()
y = target %>% as.matrix()
TAHAP V
Saya buat model keras sequential dengan skrip sebagai berikut:
model =
keras_model_sequential() %>%
layer_lstm(units = 300, activation = "linear", input_shape = c(ncol(x),1)) %>%
layer_dense(units = 1, activation = "linear") %>%
layer_activation("linear")
model %>% compile(
loss = "mae",
optimizer = "rmsprop",
metrics = list("mean_absolute_error")
)
model %>% summary()
## Model: "sequential"
## ________________________________________________________________________________
## Layer (type) Output Shape Param #
## ================================================================================
## lstm (LSTM) (None, 300) 362400
## dense (Dense) (None, 1) 301
## activation (Activation) (None, 1) 0
## ================================================================================
## Total params: 362,701
## Trainable params: 362,701
## Non-trainable params: 0
## ________________________________________________________________________________
Perhatikan bahwa saya menggunakan layer_lstm pada kali ini. Berbeda
dengan kasus regresi dan klasifikasi yang telah saya tulis sebelumnya.
Perhatikan juga bahwa parameter yang saya gunakan untuk mengukur akurasi
dari forecast model adalah mean absolute error (MAE).
Setelah itu, saya train modelnya dengan 500 epochs.
fitmodel =
model %>% keras::fit(x, y,
epochs = 400,
verbose = 0,
validation_split = 0.15)
plot(fitmodel)
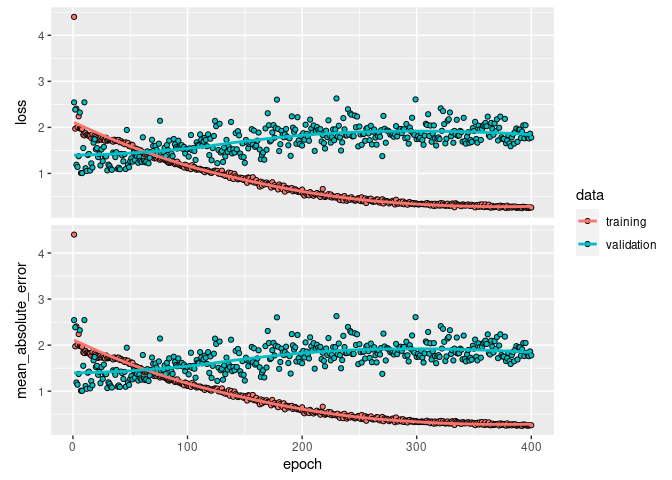
Saya lihat seberapa akurat model saya dengan melihat nilai MAE-nya:
scores = model %>% evaluate(x, y, verbose = 0)
scores
## loss mean_absolute_error
## 0.5658646 0.5658646
TAHAP VI
Model sudah selesai dibuat. Sekarang saya akan coba lakukan plot nilai omset asli dengan nilai omset hasil forecast untuk keseluruhan training data:
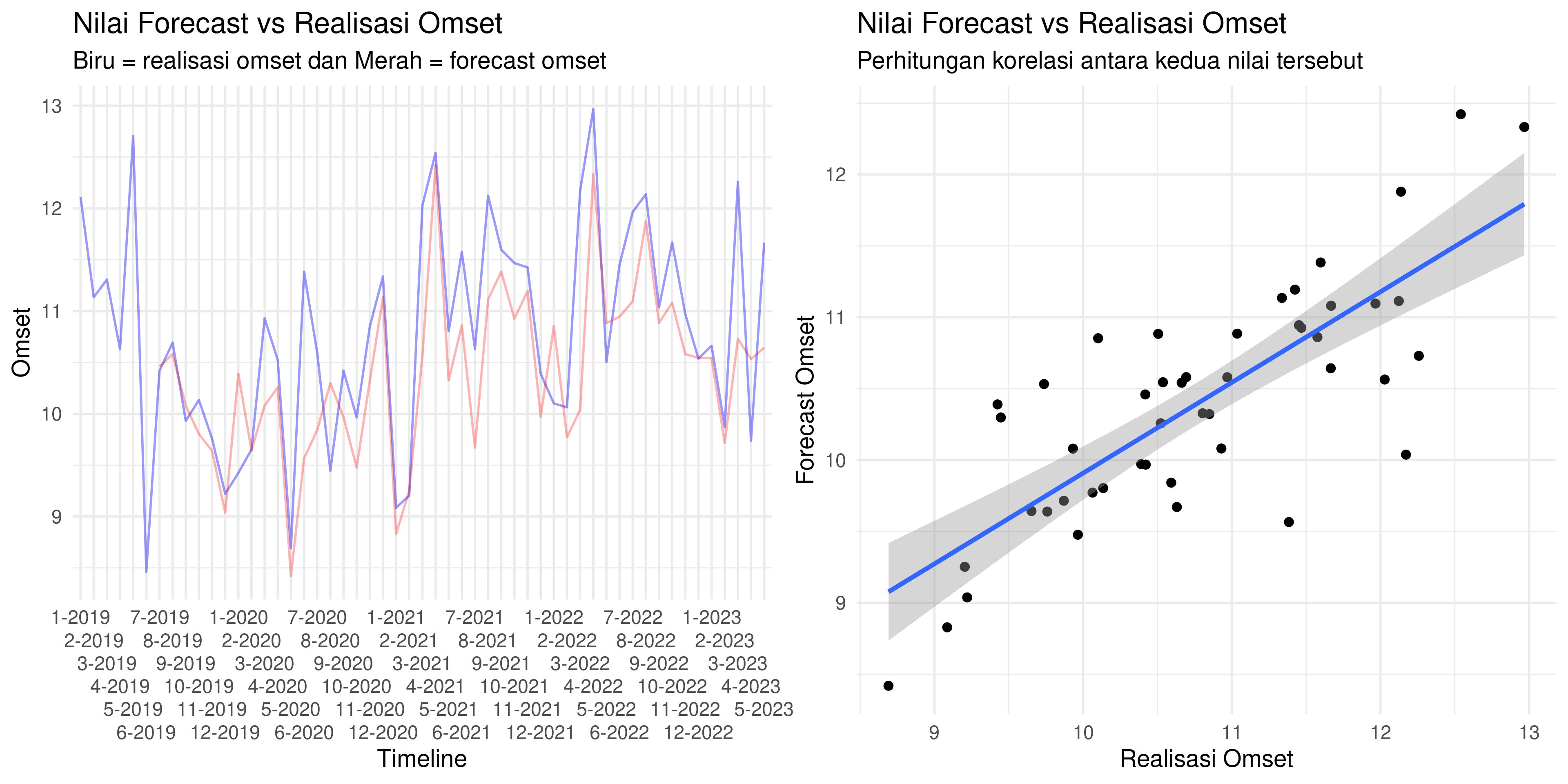
Berikut adalah nilai korelasinya:
## [1] 0.7895185
Ternyata kita bisa mendapatkan hasil akurasi yang lumayan.
BONUS PART
Sekarang saya akan buat forecast dengan cara yang berbeda. Saya akan mencoba melakukan forecast untuk omset tahun 2023, namun caranya adalah dengan:
- Forecast bulan Januari 2023 berasal dari data input bulan 7-12 2022.
- Forecast bulan Februari 2023 berasal dari data input bulan 8-12 2022 dan Januari 2023.
- Forecast bulan Maret 2023 berasal dari data input bulan 9-12 2022, Januari, dan Februari 2023.
- Forecast bulan April 2023 berasal dari data input bulan 10-12 2022, Januari, Februari, dan Maret 2023.
- Forecast bulan Mei 2023 berasal dari data input bulan 11-12 2022, Januari, Februari, Maret, dan April 2023.
Berikut adalah skrip algoritmanya:
# kita ambil 6 bulan akhir taun 2022
uji_coba =
df %>%
filter(tahun == 2022) %>%
tail(n_bulan)
# ini adalah omset 2023
omset_2023 =
df %>%
filter(tahun == 2023)
# kita buat dulu
input_new = uji_coba$omset %>% t() %>% as.matrix()
# buat rumah dulu
hasil_new = rep(0,nrow(omset_2023))
# bulan januari
y_pred = model %>% predict(input_new)
hasil_new[1] = y_pred
# bulan februari
input_new = c(uji_coba$omset[2:6],hasil_new[1]) %>% t() %>% as.matrix()
y_pred = model %>% predict(input_new)
hasil_new[2] = y_pred
# bulan maret
input_new = c(uji_coba$omset[3:6],hasil_new[1:2]) %>% t() %>% as.matrix()
y_pred = model %>% predict(input_new)
hasil_new[3] = y_pred
# bulan april
input_new = c(uji_coba$omset[4:6],hasil_new[1:3]) %>% t() %>% as.matrix()
y_pred = model %>% predict(input_new)
hasil_new[4] = y_pred
# bulan may
input_new = c(uji_coba$omset[5:6],hasil_new[1:4]) %>% t() %>% as.matrix()
y_pred = model %>% predict(input_new)
hasil_new[5] = y_pred
# kita gabung kembali
omset_2023 =
omset_2023 %>%
mutate(y_pred = hasil_new)
Berikut adalah grafik hasil forecast versus realisasi omset di tahun 2023:
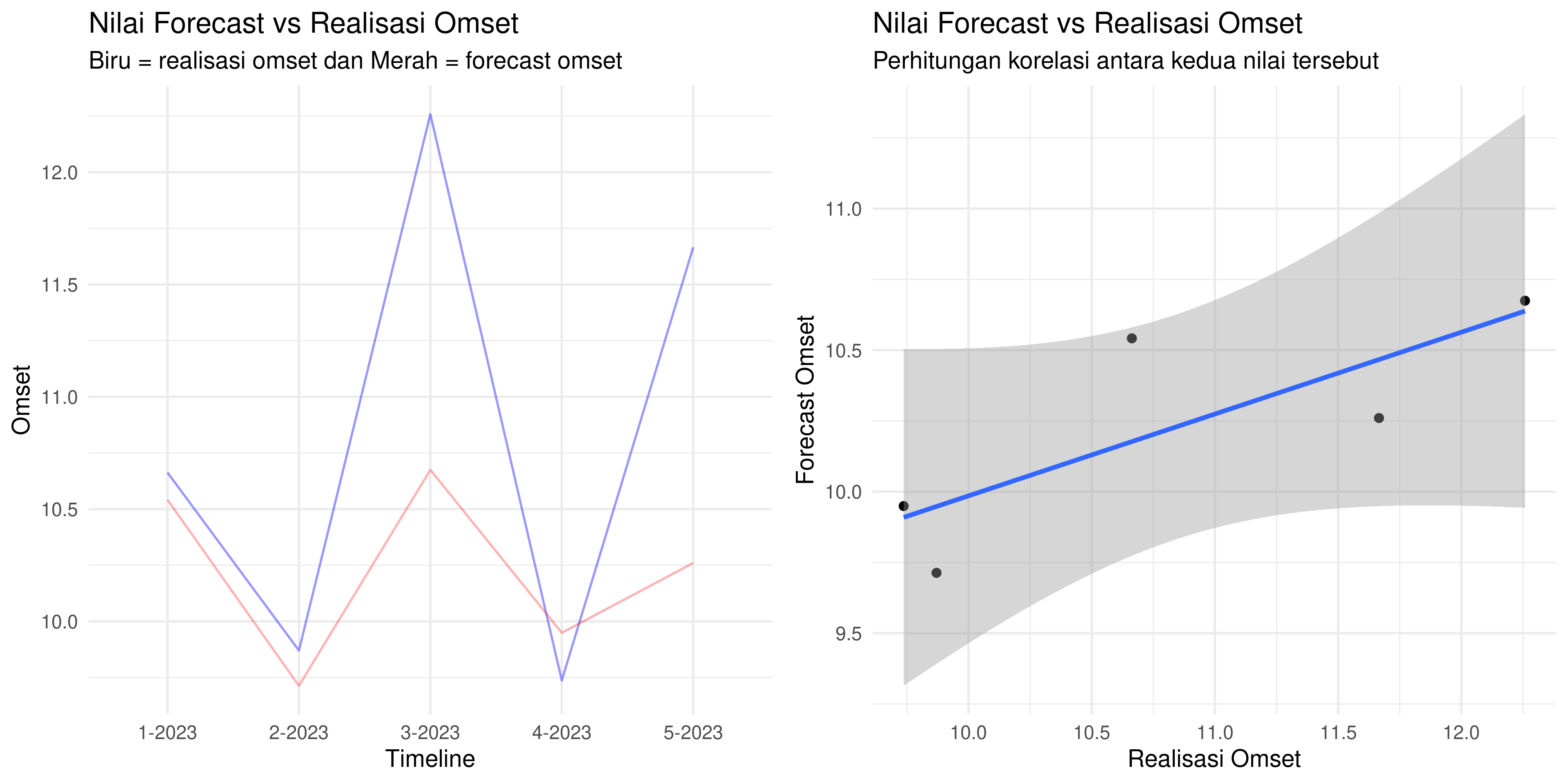
## [1] 0.7973603
Remarks
Untuk meningkatkan akurasi, kita bisa melakukan beberapa hyperparameter tuning dan atau data augmentation yang lebih baik.