
Menyelesaikan Phonebook Problem Menggunakan R
Suatu waktu saya sedang bebersih phonebook ponsel saya.
Barangkali ada beberapa kontak yang double input atau update nomornya.
Begitu pikir saya.
Bagi para pengguna Android, hal seperti ini sangat dimudahkan dengan
layanan Google Contacts. Dengan algoritmanya, Google bisa memberikan
saran contacts mana saja yang kemungkinan merupakan contact yang
sama.
Algoritma tersebut akan menyarankan agar contacts tersebut di-merge.
Percaya atau tidak, permasalahan sederhana tersebut adalah
permasalahan besar di level perusahaan. Banyak perusahaan memiliki
database konsumen, toko, atau reseller yang tidak bersih.
Banyak duplikasi terjadi.
Sebagai contoh:
Satu toko yang sama bisa jadi dicatat berbeda oleh dua orang salesman dari perusahaan yang sama.
Misal Toko Aman Jaya bisa saja ditulis sebagai:
Toko Aman JayaTk. Aman JayaToko AmanjayaTk. A Jaya- dan lain sebagainya
Lantas bagaimana caranya kita bisa mengetahui dan melakukan merge terhadap beberapa contacts yang diduga adalah sama?
Algoritma Similarity
Sebenarnya saya menuliskan algoritma ini secara tidak sengaja ketika sata membuat algoritma extraction based summarization. Prosesnya mirip saat saya menyusun kemiripan beberapa kalimat yang akan dipilih sebagai summary dari suatu tulisan.
Bagaimana framework algoritmanya?
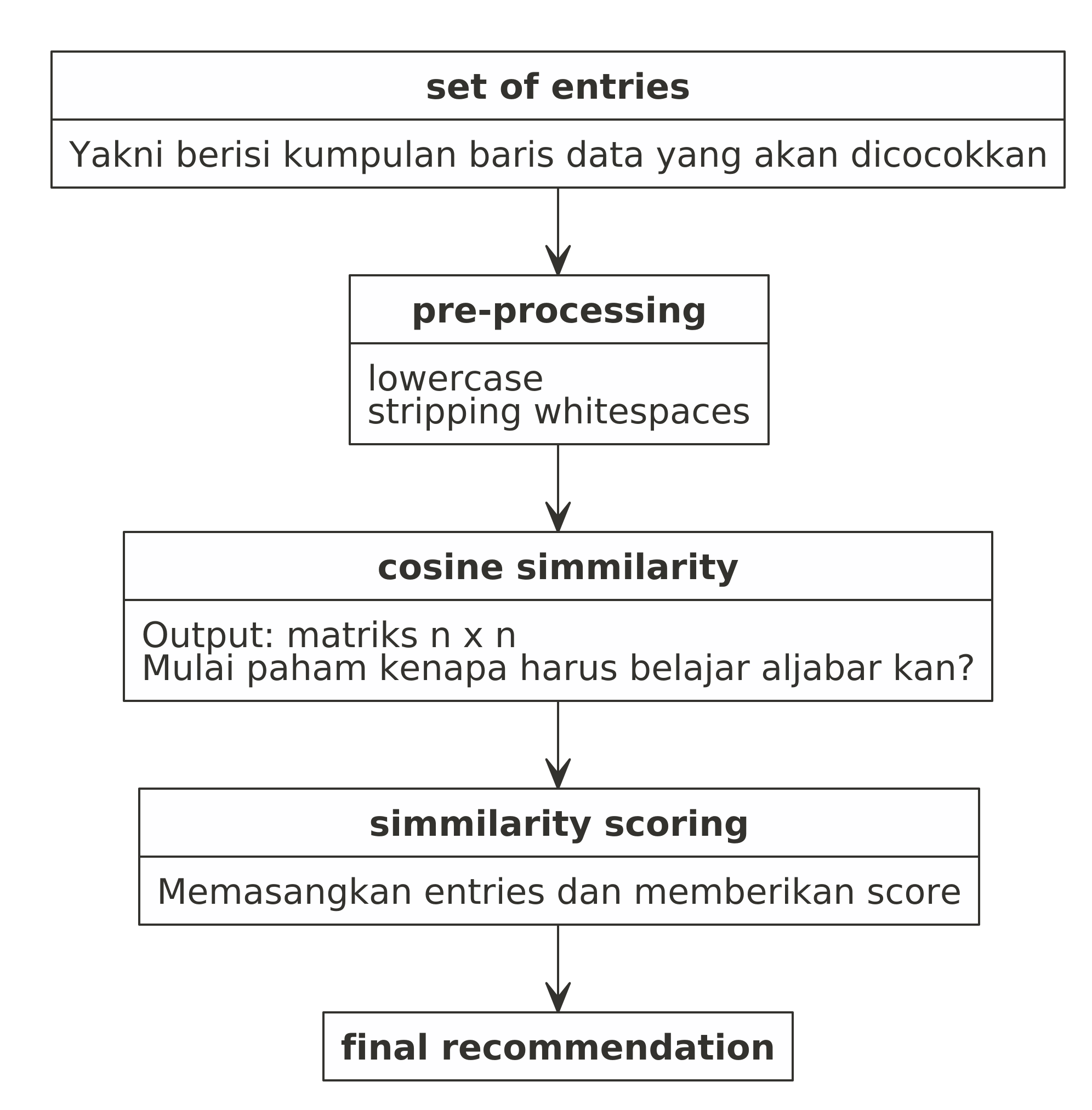
Cukup simpel kan?
Saya berikan contoh berikut yah.
John Smith Problems
Sebagai contoh, saya akan gunakan dataset berisi 10 nama John
Smith yang akan dicocokkan. Dataset ini tersedia di publik dan ada
beberapa data scientist lain yang membuat model simmilarity juga.
Lantas bedanya apa dengan algoritma yang saya buat? Saya menggunakan metode Cosine yang dinilai lebih baik berdasarkan salah satu jurnal yang saya baca.
Oke, berikut adalah datanya:
| ID | FirstName | LastName | Title | AddressLine1 | AddressSuburb | AddressPostcode | Phone |
|---|---|---|---|---|---|---|---|
| 1 | John | Smith | Mr | 12 Acadia Rd | Burnton | 9671 | 1234 5678 |
| 2 | Jhon | Smith | Mr | 12 Arcadia Road | Bernton | 967 | 1233 5678 |
| 3 | J | Smith | Mr. | 12 Acadia Ave | Burnton | 867`1 | 1233 567 |
| 4 | John | Smith | Mr | 13 Kynaston Rd | Burnton | 9671 | 34561234 |
| 5 | John | Smith | Dr | Burnton | 9671 | 34561233 | |
| 6 | John | S | Dr. | 12 Kinaston Road | Bernton | 9677 | 34561223 |
| 7 | Jon | Smith | Mr. | 13 Kinaston Rd | Barnston | 9761 | 36451223 |
| 8 | John | Smith | Dr | 12 Aracadia St | Brenton | 9761 | 12345666 |
| 9 | John | Smith | Mr | 13 Acacia Ave | Burnside | 8961 | 67231231 |
| 10 | John | Smith | Dr | 12 Kingsford Rd | Burnton | 9671 | 89624328 |
Saya akan menggunakan semua informasi yang ada pada data tersebut
(tentunya selain variable id) untuk melihat pasangan baris yang
mungkin merupakan satu entry.
Pre-Processing
Langkah pre-processing ini hanya tinggal menjadikan semua tulisan menjadi lowercase, lalu menghilangkan whitespaces yang tidak perlu, dan menggabungkan semua variable yang saya kehendaki.
## [1] "johnsmithmr12acadiardburnton967112345678"
## [2] "jhonsmithmr12arcadiaroadbernton96712335678"
## [3] "jsmithmr12acadiaaveburnton86711233567"
## [4] "johnsmithmr13kynastonrdburnton967134561234"
## [5] "johnsmithdrburnton967134561233"
## [6] "johnsdr12kinastonroadbernton967734561223"
## [7] "jonsmithmr13kinastonrdbarnston976136451223"
## [8] "johnsmithdr12aracadiastbrenton976112345666"
## [9] "johnsmithmr13acaciaaveburnside896167231231"
## [10] "johnsmithdr12kingsfordrdburnton967189624328"
Membuat matriks cosine simmilarity dan scoring
Berikutnya adalah membuat matriks kesamaan antara 10 entries yang
ada.
## 1 2 3 4 5 6 7 8 9 10
## 1 0 0.959 0.931 0.875 0.857 0.872 0.893 0.940 0.879 0.868
## 2 0 0.000 0.922 0.840 0.825 0.889 0.885 0.930 0.876 0.834
## 3 0 0.000 0.000 0.776 0.765 0.784 0.833 0.904 0.944 0.710
## 4 0 0.000 0.000 0.000 0.957 0.901 0.962 0.843 0.748 0.857
## 5 0 0.000 0.000 0.000 0.000 0.871 0.917 0.822 0.750 0.853
## 6 0 0.000 0.000 0.000 0.000 0.000 0.933 0.871 0.735 0.886
## 7 0 0.000 0.000 0.000 0.000 0.000 0.000 0.886 0.805 0.862
## 8 0 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.869 0.808
## 9 0 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.701
## 10 0 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
Pairing Entries
Sekarang dari matriks di atas, kita akan ekstrak pasangan entries mana saja yang mendapatkan score tertinggi.
Oh iya, max score yang memungkinkan adalah nilai 1 yah. Kali ini
saya akan buat threshold di angka 0.95.
| entry_1 | entry_2 | score |
|---|---|---|
| 4 | 7 | 0.962 |
| 1 | 2 | 0.959 |
| 4 | 5 | 0.957 |
Final Recommendation
Dari hasil di atas, kita bisa memberikan rekomendasi bahwa:
## Rekomendasi 1 dengan score: 0.962
## Entry ke: 4 ~ 4 John Smith Mr 13 Kynaston Rd Burnton 9671 34561234
## Entry ke: 7 ~ 7 Jon Smith Mr. 13 Kinaston Rd Barnston 9761 36451223
##
## Rekomendasi 2 dengan score: 0.959
## Entry ke: 1 ~ 1 John Smith Mr 12 Acadia Rd Burnton 9671 1234 5678
## Entry ke: 2 ~ 2 Jhon Smith Mr 12 Arcadia Road Bernton 967 1233 5678
##
## Rekomendasi 3 dengan score: 0.957
## Entry ke: 4 ~ 4 John Smith Mr 13 Kynaston Rd Burnton 9671 34561234
## Entry ke: 5 ~ 5 John Smith Dr Burnton 9671 34561233
Summary
Jika dirasa belum puas terhadap kinerja atau rekomendasi yang diberikan, kita bisa melakukan beberapa cara untuk tweaking the algorithm, apa saja?
- Mengubah cara pre-processing dengan:
- Hanya mengambil beberapa variables yang dinilai penting (instead of mengambil all variables).
- Mengilangkan angka.
- Mengubah aturan mengenai whitespaces.
- Mengubah nilai threshold.