
Optimization Story: Menentukan Sample Quick Count PEMILU di Bekasi Timur
Sejak quick count pertama kali digunakan pada Pemilu 2004, saya menjadi penasaran bagaimana cara mereka bekerja. Qodarullah, saat kuliah di Matematika ITB saya dipertemukan dengan seorang dosen yang membantu pengembangan metodologi quick count tersebut dengan tingkat kesalahan yang sangat amat kecil.
Saat mendengarkan pemaparan beliau, ternyata persiapannya sangat rumit ya.
Di pekerjaan saya di bidang market research, dikenal ada salah satu metode sampling yang disebut dengan stratified sampling. Kurang lebih penentuan berapa banyak dan daerah mana saja yang dijadikan sampel perhitungan quick count sama dengan penerapan stratified sampling tersebut.
Pada Pemilu 2019 lalu, salah seorang rekan saya yang menjadi simpatisan partai politik tertentu berdiskusi tentang proses perekapan formulir C1 yang dimiliki oleh saksi-saksi Parpol di TPS. Setelah berdiskusi dengannya, muncul pertanyaan di benak saya:
Apakah bisa saya melakukan quick count hanya di Bekasi namun hasilnya sangat akurat mendekati proporsi angka nasional?
Berhubung waktu itu belum punya ilmu yang cukup, pertanyaan ini saya selalu simpan di notes pribadi saya.
Saat kuliah magister Sains Komputasi beberapa tahun belakangan ini, saya cukup ngoprek tentang topik bernama optimisasi matematika. Setelah saya lihat kembali pertanyaan simpanan tersebut, saya berpikir bahwa proses penyelesaian pertanyaan ini harusnya bisa diselesaikan dengan membuat model optimisasi.
Bagaimana caranya? Oke, kita mulai prosesnya perlahan:
—-
Golden standard untuk menghitung dan menentukan sampel untuk quick count adalah dengan menggunakan stratified sampling. Namun berhubung saya tidak cukup waktu, tenaga, dan modal, saya tidak mungkin mencari data tentang kependudukan dan preferensi pemilih untuk menentukan strata populasi di Bekasi.
Oleh karena itu saya akan menggunakan suatu pendekatan lain, yakni menentukan area atau TPS mana yang harus dijadikan sampel quick count dari data Pilpres hasil Pemilu 2019. Saya berhipotesis, dari sekian banyak TPS yang ada (populasi TPS di Bekasi), pasti ada sekumpulan TPS yang kalau di-agregatkan proporsinya akan mendekati proporsi nasional. Tentu asumsinya adalah tidak ada perubahan demografi pemilih di TPS tersebut ya.
Untuk itu saya melakukan web scraping data hasil Pemilu 2019 dari situs KPU Nasional. Berikut adalah data yang saya dapatkan:
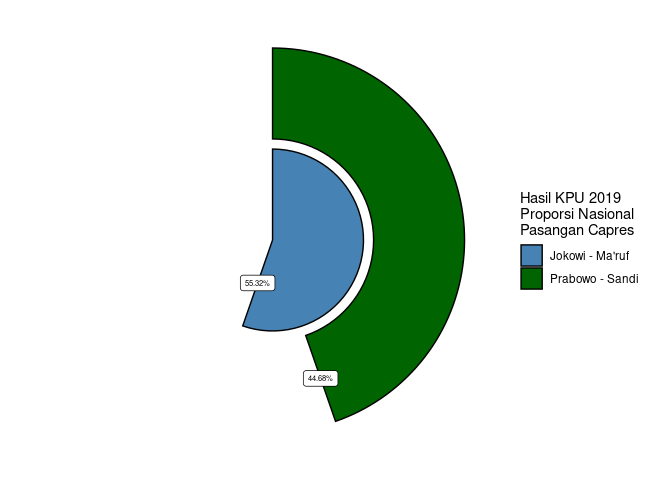
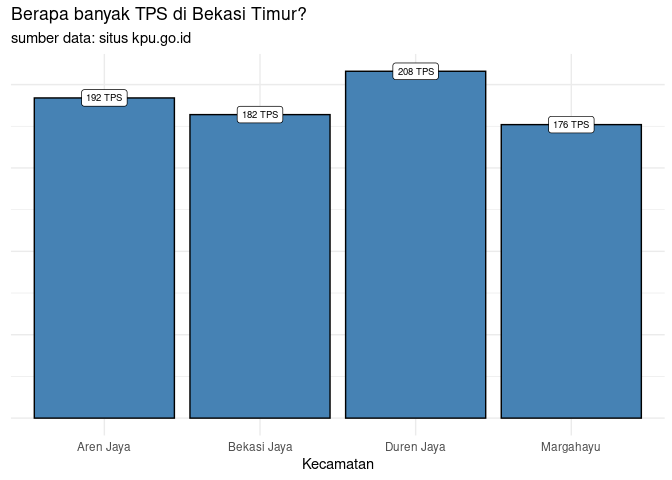
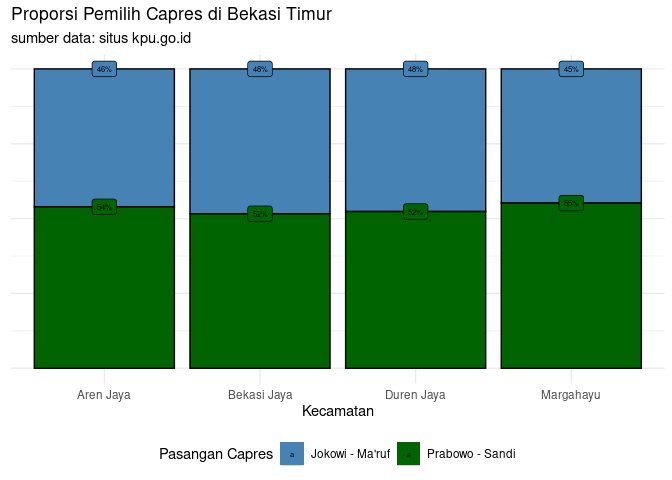
Terlihat di Bekasi Timur:
- Ada 758 buah TPS dari empat area: Margahayu, Aren Jaya, Bekasi Jaya, dan Duren Jaya.
- Secara nasional proporsi pemilih “Jokowi - Ma’ruf” lebih tinggi namun di empat area di Bekasi Timur pasangan “Prabowo Sandi” memiliki proporsi pemilih yang lebih tinggi.
Tujuan saya adalah:
Menentukan dari 758 TPS ini, berapa banyak TPS yang perlu diambil agar hasil proporsi suara totalnya akan mendekati proporsi suara Nasional.
Seru yah… hehe
Bagaimana caranya?
Tentu dengan membuat model Binary Linear Programming. Sama persis dengan masalah portofolio diskon produk.
Berikut adalah contoh 50 baris data TPS dari 758 baris data TPS yang berhasil saya ambil:
| TPS | Jokowi - Ma’ruf | Prabowo - Sandi | Kecamatan | |
|---|---|---|---|---|
| 3 | TPS 003 (100%) | 113 | 132 | Aren Jaya |
| 10 | TPS 010 (100%) | 119 | 67 | Aren Jaya |
| 12 | TPS 012 (100%) | 93 | 70 | Aren Jaya |
| 15 | TPS 015 (100%) | 106 | 113 | Aren Jaya |
| 26 | TPS 026 (100%) | 92 | 64 | Aren Jaya |
| 85 | TPS 085 (100%) | 71 | 115 | Aren Jaya |
| 91 | TPS 091 (100%) | 119 | 92 | Aren Jaya |
| 94 | TPS 094 (100%) | 113 | 101 | Aren Jaya |
| 96 | TPS 096 (100%) | 81 | 76 | Aren Jaya |
| 98 | TPS 098 (100%) | 87 | 106 | Aren Jaya |
| 145 | TPS 145 (100%) | 81 | 124 | Aren Jaya |
| 147 | TPS 147 (100%) | 104 | 93 | Aren Jaya |
| 214 | TPS 022 (100%) | 95 | 97 | Bekasi Jaya |
| 221 | TPS 029 (100%) | 60 | 91 | Bekasi Jaya |
| 226 | TPS 034 (100%) | 86 | 95 | Bekasi Jaya |
| 232 | TPS 040 (100%) | 184 | 47 | Bekasi Jaya |
| 241 | TPS 049 (100%) | 71 | 149 | Bekasi Jaya |
| 263 | TPS 071 (100%) | 86 | 67 | Bekasi Jaya |
| 272 | TPS 080 (100%) | 129 | 87 | Bekasi Jaya |
| 305 | TPS 113 (100%) | 107 | 125 | Bekasi Jaya |
| 318 | TPS 126 (100%) | 102 | 136 | Bekasi Jaya |
| 319 | TPS 127 (100%) | 106 | 102 | Bekasi Jaya |
| 321 | TPS 129 (100%) | 196 | 89 | Bekasi Jaya |
| 344 | TPS 152 (100%) | 115 | 89 | Bekasi Jaya |
| 347 | TPS 155 (100%) | 25 | 44 | Bekasi Jaya |
| 354 | TPS 162 (100%) | 42 | 32 | Bekasi Jaya |
| 367 | TPS 175 (100%) | 76 | 72 | Bekasi Jaya |
| 369 | TPS 177 (100%) | 73 | 36 | Bekasi Jaya |
| 373 | TPS 181 (100%) | 107 | 89 | Bekasi Jaya |
| 389 | TPS 015 (100%) | 80 | 105 | Duren Jaya |
| 415 | TPS 041 (100%) | 176 | 59 | Duren Jaya |
| 425 | TPS 051 (100%) | 103 | 114 | Duren Jaya |
| 448 | TPS 074 (100%) | 95 | 150 | Duren Jaya |
| 449 | TPS 075 (100%) | 70 | 166 | Duren Jaya |
| 505 | TPS 131 (100%) | 68 | 82 | Duren Jaya |
| 547 | TPS 173 (100%) | 101 | 82 | Duren Jaya |
| 568 | TPS 194 (100%) | 67 | 72 | Duren Jaya |
| 577 | TPS 203 (100%) | 31 | 35 | Duren Jaya |
| 580 | TPS 206 (100%) | 71 | 78 | Duren Jaya |
| 590 | TPS 008 (100%) | 88 | 105 | Margahayu |
| 596 | TPS 014 (100%) | 38 | 215 | Margahayu |
| 620 | TPS 038 (100%) | 93 | 132 | Margahayu |
| 653 | TPS 071 (100%) | 140 | 101 | Margahayu |
| 664 | TPS 082 (100%) | 115 | 113 | Margahayu |
| 675 | TPS 093 (100%) | 123 | 82 | Margahayu |
| 688 | TPS 106 (100%) | 141 | 88 | Margahayu |
| 691 | TPS 109 (100%) | 99 | 124 | Margahayu |
| 711 | TPS 129 (100%) | 100 | 119 | Margahayu |
| 726 | TPS 144 (100%) | 115 | 141 | Margahayu |
| 752 | TPS 170 (100%) | 43 | 66 | Margahayu |
Saya definisikan
dengan
sebagai bilangan biner:
- Dimana 1 berarti TPS tersebut saya pilih sebagai sampel quick count dan
- Nilai 0 berarti TPS tersebut tidak dipilih.
Tentu ada batasan dari masalah saya:
- Tentu saya menginginkan TPS yang saya sampel harus sesedikit mungkin karena keterbatasan sumber daya.
- Tentu saya menginginkan error yang terjadi sekecil-kecilnya.
Dari rumusan di atas, maka masalah saya sekarang adalah menentukan nilai
dari .
Algoritma Komputasi
Untuk menyelesaikan masalah di atas, saya membuat algoritma menggunakan
library(ompr) di R. Saya membuat dua skenario:
- Skenario I: Jika saya tidak membatasi berapa banyak TPS yang harus diambil dan hanya mengejar akurasi tertinggi (error terkecil).
- Skenario II: Jika saya hanya membatasi 40 TPS saja yang harus diambil dengan akurasi yang tinggi juga.
Bagaimana hasilnya? Cekidot:
Skenario I
Hasil skenario I mengharuskan saya mengambil n buah TPS sebagai sampel quick count saya. Dari semua TPS tersebut saya dapatkan hasil sebagai berikut:
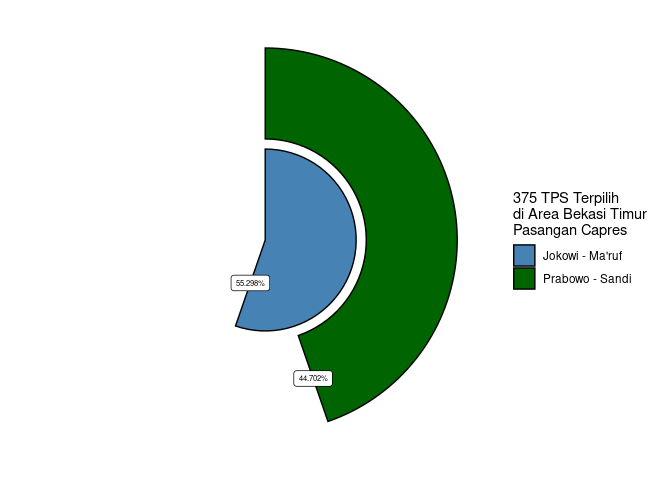
Pada skenario I ini, model mengharuskan saya memilih 375 TPS tertentu sebagai target quick count. Hasilnya bisa dilihat bahwa error yang dihasilkan sanga kecil (proporsi TPS terpilih sangat mendekati proporsi nasional).
Jika rekan-rekan penasaran 375 TPS tersebut apa saja dan di mana, silakan DM saya saja ya.
Skenario II
Sekarang kita beralih ke skenario II, yakni hanya memilih 40 TPS. Berikut adalah hasilnya:
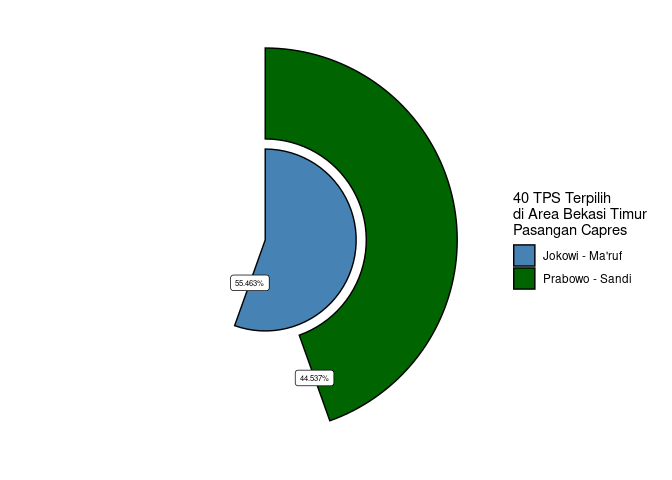
Saya dapatkan 40 TPS yang memiliki proporsi agregat yang memiliki error yang kecil (walau tidak sekecil skenario I).
Jika rekan-rekan penasaran juga dengan mana saja 40 TPS ini, silakan DM ke saya ya.
Summary
Dari pemaparan di atas, ternyata optimisasi bisa saya gunakan untuk mencari TPS mana saja yang perlu saya ambil sehingga proporsinya bisa mendekati proporsi hasil akhir nasional.