
Membuat Sendiri (semisal) ChatGPT dari Data Sendiri
Salah satu cita-cita luhur hampir semua perusahaan yang saya kenali adalah membuat ChatGPT versi lokal mereka sendiri. Maksudnya apa? Mereka hendak membuat suatu sistem semacam ChatGPT yang bisa menjawab pertanyaan-pertanyaan yang diajukan berdasarkan data internal yang di-feed ke dalamnya.
Kenapa harus dijalankan secara lokal? Karena beberapa data bersifat confidential sehingga tidak bisa di-share ke manapun (kadang sampai tidak boleh di-save secara cloud).
Jika kita Googling, ada beberapa tools dan cara yang sebenarnya bisa digunakan. Jika perusahaan tersebut punya dana yang cukup, mereka bisa menggunakan layanan Azure Cognitive Search atau Google Vertex AI. Namun, jika secara perhitungan cost benefit ternyata tidak masuk, perusahaan bisa mempertimbangkan solusi dengan cara membuat sendiri menggunakan model-model open source yang bisa diambil dari Huggingface.
Seperti biasa, karena penasaran saya mencoba membuat sistem semacam itu menggunakan R, sedikit Py, dan model-model open source di Huggingface. Istilah untuk sistem semacam ini adalah RAG-LLM. Berikut adalah penjelasan singkat tentang RGA-LLM:
Penjelasan RAG
RAG adalah singkatan dari Retrieval-Augmented Generation. Ini adalah sebuah arsitektur atau teknik dalam kecerdasan buatan (AI), khususnya pada Large Language Models (LLM). Tujuan utama RAG adalah untuk meningkatkan kualitas jawaban yang dihasilkan oleh LLM dengan cara menggabungkan:
- Kemampuan LLM dalam menghasilkan teks dengan
- Kemampuan mengambil (retrieve) informasi relevan dari sumber data yang diberikan.
Untuk membuatnya secara DIY, saya membuat sebuah kerangka kerja sebagai berikut:
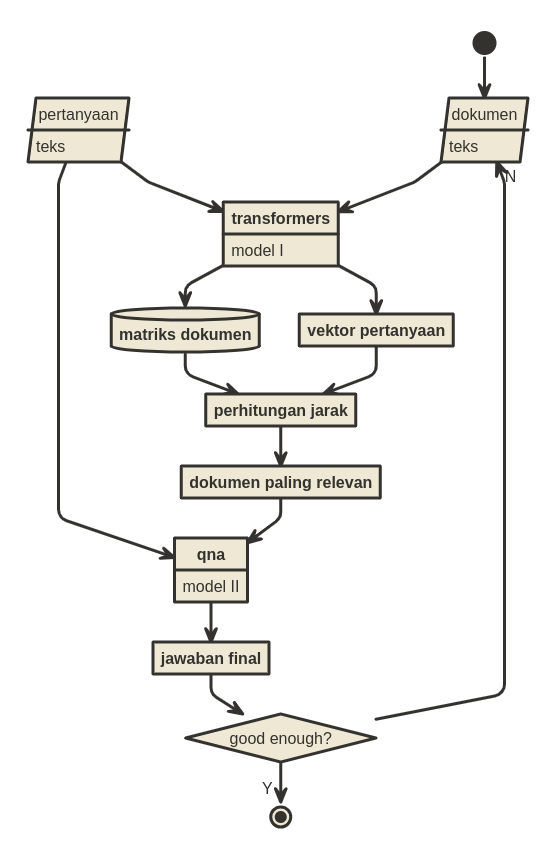
Penjelasannya seperti ini:
- Input pertama adalah multiple text documents. Menggunakan model transformers saya akan mengubah semua dokumen yang ada dalam bentuk matriks.
- Input berikutnya adalah pertanyaan yang berupa kalimat. Menggunakan model yang sama, saya mengubahnya menjadi vektor.
- Saya akan hitung kedekatan matriks dengan vektor untuk mendapatkan dokumen mana yang paling relevan dengan pertanyaan yang diajukan. Saya menggunakan formula cosine untuk menentukan jarak.
- Menggunakan model QnA, saya akan menanyakan pertanyaan ke dalam dokumen tersebut.
Cukup mudah kan?
Model yang saya gunakan adalah:
- Model transformers:
naufalihsan/indonesian-sbert-large. - Model QnA:
Rifky/Indobert-QA.
Kedua model ini berjalan di Bahasa Indonesia.
Untuk menjalankannya saya menggunakan reticulate di R.
if you find this article helpful, support this blog by clicking the ads.