
Mengolah Data Survey Pertanyaan Multiple Responses dengan Tidyverse
Sudah 5 tahun terakhir saya sudah meninggalkan SPSS dan menggunakan
R untuk mengolah data hasil survey. Salah satu hal yang paling
menarik saat mengolah data survey adalah saat menghadapi jawaban dari
pertanyaan multiple responses.
Maksudnya multiple responses seperti apa?
Pertanyaan yang bisa dijawab dengan lebih dari satu jawaban.
Contohnya apa?
Misalkan:
Sebutkan stasiun TV nasional yang biasa Anda tonton sehari-hari?
Masing-masing responden bisa menjawab lebih dari satu jawaban tergantung dari pengalaman masing-masing respondennya.
Berikut adalah contoh datanya:
| id | stasiun_tv |
|---|---|
| 1 | NET;RCTI;SCTV |
| 2 | NET;SCTV |
| 3 | INDOSIAR;NET |
| 4 | INDOSIAR;METRO |
| 5 | METRO |
| 6 | NET;KOMPAS |
| 7 | TV ONE;KOMPAS |
| 8 | NET;TV ONE;KOMPAS;RCTI |
| 9 | KOMPAS;SCTV |
| 10 | NET;SCTV;KOMPAS |
Jika diperhatikan, jawaban dari responden dicatat dengan cara menuliskan
jawaban dengan dipisahkan dengan semicolon (;).
Lantas bagaimana cara mengolahnya? Kita akan gunakan salah satu
function dari library(tidyr), yakni separate_rows() untuk mengubah
data tersebut menjadi tabular ke bawah.
Bagaimana caranya?
Misalkan datanya saya simpan dengan nama df:
df
## id stasiun_tv
## 1 1 NET;RCTI;SCTV
## 2 2 NET;SCTV
## 3 3 INDOSIAR;NET
## 4 4 INDOSIAR;METRO
## 5 5 METRO
## 6 6 NET;KOMPAS
## 7 7 TV ONE;KOMPAS
## 8 8 NET;TV ONE;KOMPAS;RCTI
## 9 9 KOMPAS;SCTV
## 10 10 NET;SCTV;KOMPAS
Selanjutnya saya akan panggil dua libraries berikut:
library(dplyr)
library(tidyr)
Selanjutnya untuk mengubah menjadi data tabular, prosesnya cukup mudah, yakni:
df %>%
separate_rows(stasiun_tv,
sep = ";")
## # A tibble: 23 × 2
## id stasiun_tv
## <int> <chr>
## 1 1 NET
## 2 1 RCTI
## 3 1 SCTV
## 4 2 NET
## 5 2 SCTV
## 6 3 INDOSIAR
## 7 3 NET
## 8 4 INDOSIAR
## 9 4 METRO
## 10 5 METRO
## # … with 13 more rows
Selanjutnya, kita bisa menghitung tabulasi frekuensinya sebagai berikut:
df %>%
separate_rows(stasiun_tv,
sep = ";") %>%
group_by(stasiun_tv) %>%
tally(sort = T) %>%
ungroup()
## # A tibble: 7 × 2
## stasiun_tv n
## <chr> <int>
## 1 NET 6
## 2 KOMPAS 5
## 3 SCTV 4
## 4 INDOSIAR 2
## 5 METRO 2
## 6 RCTI 2
## 7 TV ONE 2
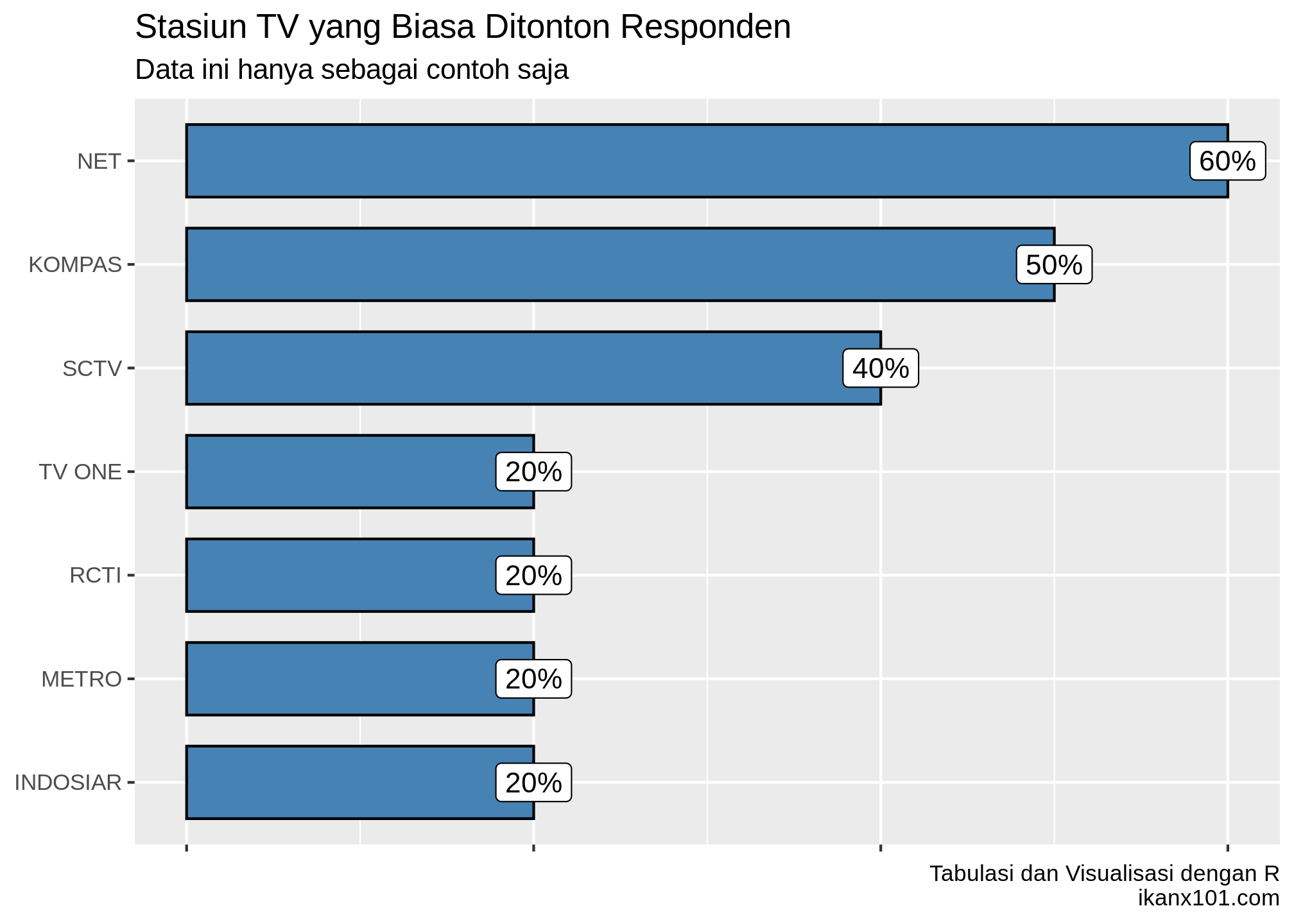
Sekarang dari tabulasi frekuensi di atas, kita bisa membuat visualisasi seperti ini:
df %>%
separate_rows(stasiun_tv,
sep = ";") %>%
group_by(stasiun_tv) %>%
tally(sort = T) %>%
ungroup() %>%
rowwise() %>%
mutate(persen = n*10,
label = paste0(persen,"%")) %>%
ungroup() %>%
ggplot(aes(x = reorder(stasiun_tv,n),
y = n)) +
geom_col(color = "black",
fill = "steelblue",
width = .7) +
geom_label(aes(label = label)) +
coord_flip() +
labs(title = "Stasiun TV yang Biasa Ditonton Responden",
subtitle = "Data ini hanya sebagai contoh saja",
caption = "Tabulasi dan Visualisasi dengan R\nikanx101.com") +
theme_get() +
theme(axis.title = element_blank(),
axis.text.x = element_blank())
Semoga membantu ya.