
Membuat Data Survey Sintetis dengan synthpop di R
Beberapa tahun yang lalu, saya pernah menuliskan tentang bagaimana cara membuat data survey sintetis untuk keperluan training pengolahan data. Pada tulisan kali ini, saya akan memberikan contoh satu alternatif cara untuk membuat data sintetis berdasarkan data real yang dimiliki.
Jadi perbedaan mendasarnya adalah kali ini saya tidak membuat data dari nol tapi membuat data sintetis hasil “copy-an” dari data sebenarnya.
Untuk melakukannya, saya menggunakan
library(synthpop)
sehingga coding dan prosesnya sangat cepat dan mudah.
Oke, misalkan saya punya data hasil survey dari 365 orang responden berisi informasi seperti:
- Gender,
- Social economy status,
- Kelompok usia,
- Awareness (ya / tidak).
dengan tabulasi sebagai berikut:
Tabulasi Jenis Kelamin
gender n percent
Pria 180 49.3%
Wanita 185 50.7%
Tabulasi SES
ses n percent
Low 99 27.1%
Mid 171 46.8%
Up 95 26.0%
Tabulasi Usia
usia n percent
< 15 th 49 13.4%
> 30 th 42 11.5%
16 - 20 th 57 15.6%
21 - 25 th 132 36.2%
26 - 30 th 85 23.3%
Tabulasi Awareness
aware n percent
tidak 188 51.5%
ya 177 48.5%
Kemudian saya hendak membuat data sintetis sebanyak 365 baris juga. Sebelumnya saya harus memastikan bahwa semua variabel dalam dataframe tersebut sudah bertipe factor.
Misalkan data survey asli saya simpan dengan nama df_survey. Kemudian
saya cukup menggunakan perintah sebagai berikut:
library(synthpop)
mysyn = syn(df_survey)
Synthesis
-----------
gender ses usia aware
summary(mysyn)
Synthetic object with one synthesis using methods:
gender ses usia aware
"sample" "cart" "cart" "cart"
gender ses usia aware
Pria :187 Low:107 < 15 th : 51 tidak:189
Wanita:178 Mid:156 > 30 th : 43 ya :176
Up :102 16 - 20 th: 58
21 - 25 th:129
26 - 30 th: 84
Oke, datanya sudah jadi. Mari kita bandingkan dengan data aslinya:
compare(mysyn, df_survey, stat = "counts")
Calculations done for gender
Calculations done for ses
Calculations done for usia
Calculations done for aware
Comparing counts observed with synthetic
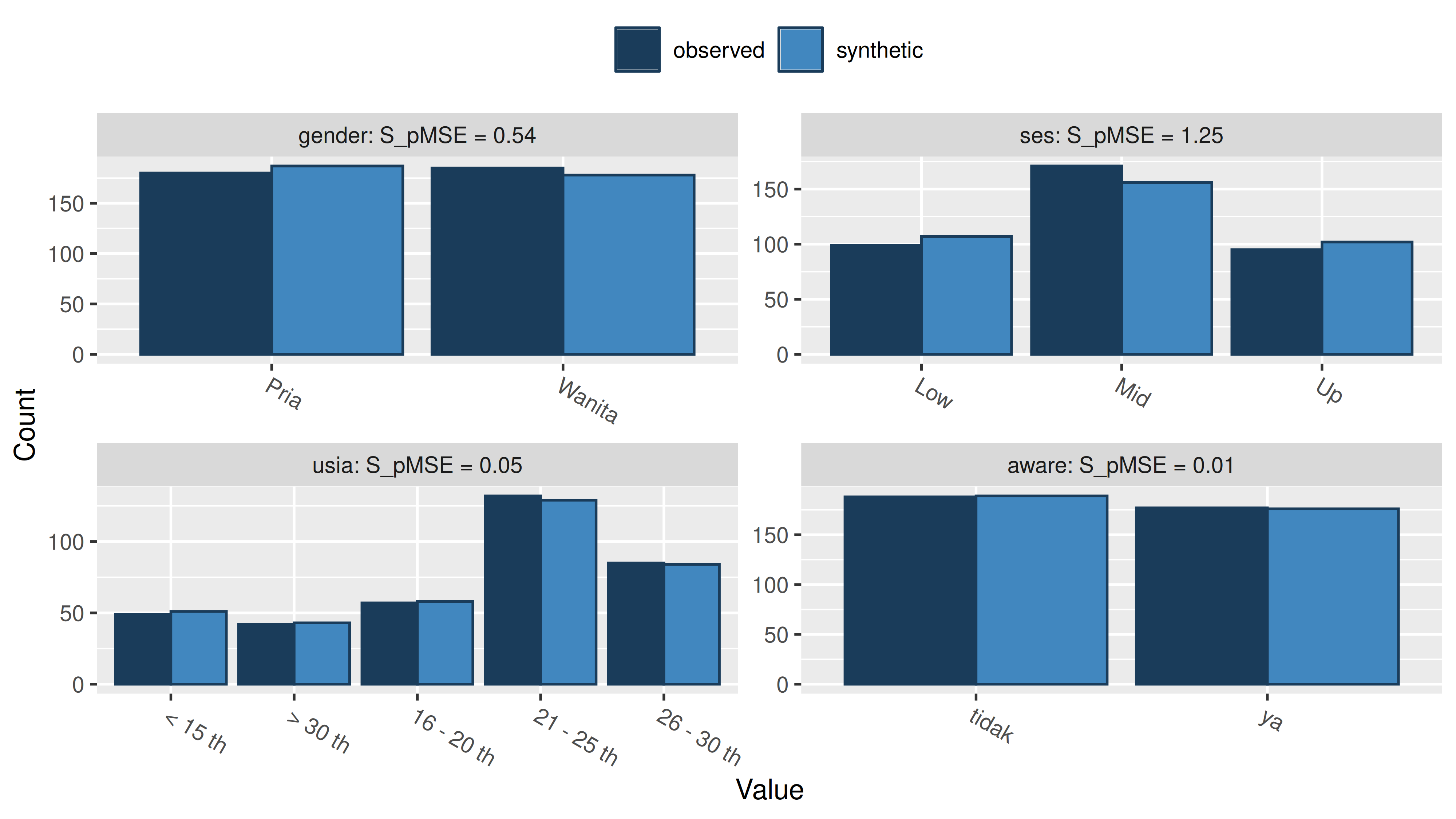
Selected utility measures:
pMSE S_pMSE df
gender 0.000092 0.537002 1
ses 0.000427 1.247484 2
usia 0.000035 0.050430 4
aware 0.000002 0.010971 1
Untuk menunjukkan seberapa baik data sintesis, kita bisa melihat parameter goodness of fit bernama S_pMSE (Standardized Propensity Mean Squared Error).
Standardized Propensity Mean Squared Error (S_pMSE) adalah metrik untuk mengevaluasi kualitas data sintetis dengan membandingkan seberapa mirip distribusinya dengan data asli.
Cut Off Nilai S_pMSE
| Nilai S_pMSE | Interpretasi | Kesimpulan |
|---|---|---|
| 0.5 - 2.0 | Sangat tinggi | Data sintetis sudah siap digunakan untuk analisis |
| 2.0 - 10.0 | Baik / cukup | Masih bisa diterima dengan beberapa catatan |
| > 10.0 | Rendah | Model data sintesis perlu diperbaiki |
Jika kita lihat grafik di atas, kita bisa simpulkan bahwa data sintesis yang dihasilkan sudah baik.
Coba saya bandingkan kembali data real vs sintesis pada variabel SES dan gender:
Plots of ses by gender
Numbers in each plot (observed data):
gender
Pria Wanita
180 185
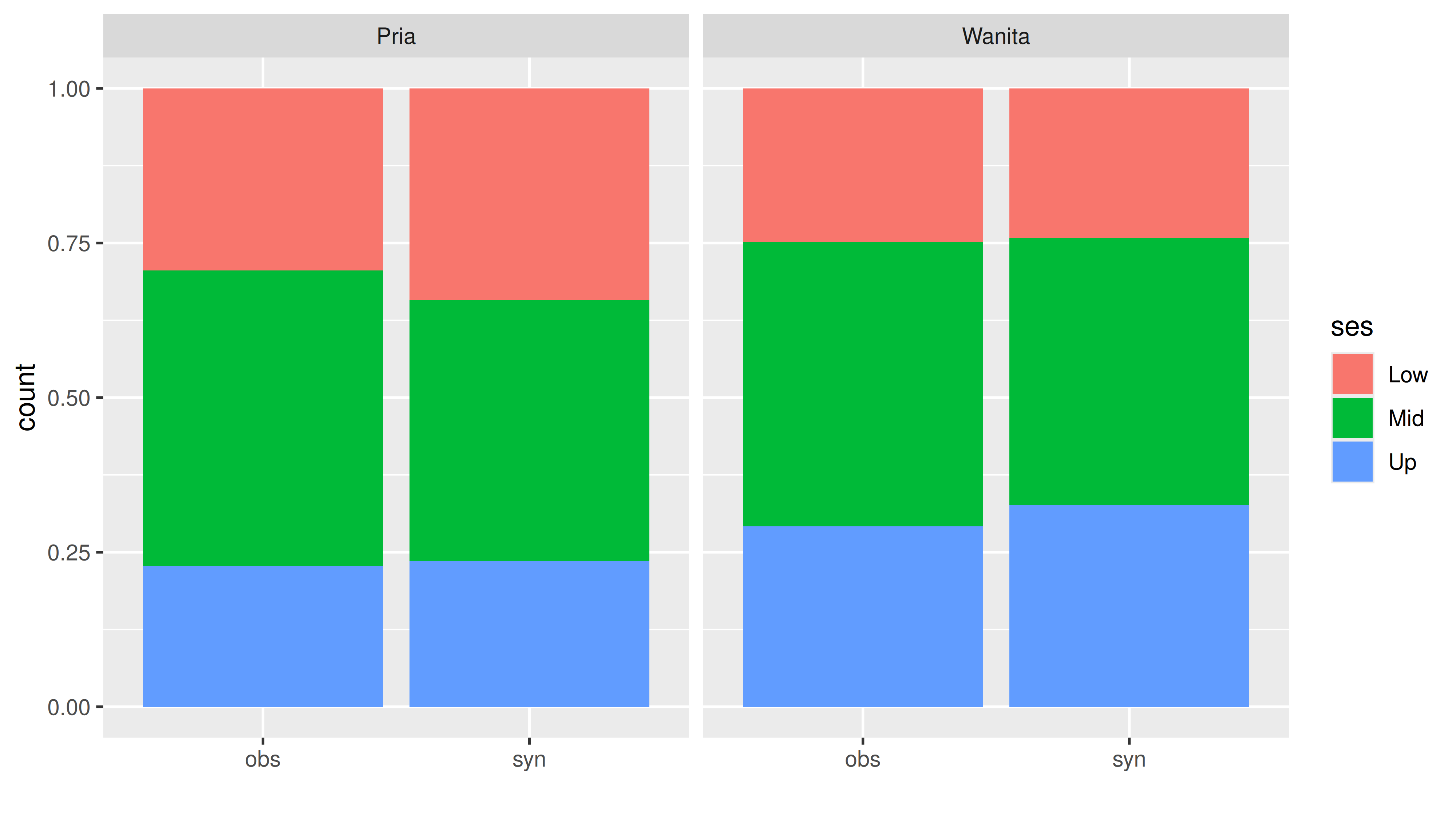
Secara visual proporsi yang dihasilkan sangat mirip. Berikut adalah sampel data yang dihasilkan:
| gender | ses | usia | aware |
|---|---|---|---|
| Pria | Mid | 21 - 25 th | tidak |
| Pria | Low | 26 - 30 th | ya |
| Wanita | Mid | < 15 th | tidak |
| Wanita | Mid | < 15 th | ya |
| Wanita | Mid | > 30 th | tidak |
| Wanita | Low | 26 - 30 th | ya |
| Pria | Low | 21 - 25 th | ya |
| Pria | Low | 21 - 25 th | tidak |
| Pria | Low | 26 - 30 th | tidak |
| Wanita | Up | 16 - 20 th | ya |
| Pria | Up | 21 - 25 th | tidak |
| Wanita | Up | 26 - 30 th | ya |
| Pria | Low | 21 - 25 th | ya |
| Pria | Up | > 30 th | ya |
| Pria | Mid | 16 - 20 th | ya |
| Pria | Mid | 16 - 20 th | tidak |
| Wanita | Up | 26 - 30 th | ya |
| Pria | Up | 21 - 25 th | tidak |
| Pria | Up | 16 - 20 th | tidak |
| Wanita | Up | > 30 th | ya |
if you find this article helpful, support this blog by clicking the ads.