
Mencari Super Spreader di Suatu Kelompok Konsumen
Pada 2020 lalu, saya pernah menuliskan bagaimana aplikasi penggunaan social network analysis dalam konteks human resources di perusahaan tempat saya bekerja. Kali ini saya akan coba menuliskan aplikasi penggunaan social network analysis pada suatu komunitas konsumen.
Tahun 2003, Malcolm Gladwell mempopulerkan konsep ‘The Tipping Point’, yakni suatu gagasan dimana epidemi, tren sosial, dan produk viral tidak menyebar secara merata. Melainkan, penyebarannya sangat bergantung pada segelintir orang yang ia sebut Connectors, Mavens, dan Salesmen.
Dua dekade kemudian, saya masih sering mendengar versi modernnya saat meeting bersama tim marketing:
Kita perlu mencari influencer yang tepat!
Maka masalahnya sekarang adalah bagaimana caranya mengidentifikasi influencer organik di dalam komunitas konsumen kita sendiri. Bukan seorang artis berbayar tapi orang-orang nyata yang paling banyak mempengaruhi keputusan pembelian bagi orang lain.
Untuk menjawabnya, kita perlu melakukan social network analysis yang memandang komunitas konsumen bukan sebagai kumpulan individu, melainkan sebagai jaringan hubungan.
Apa itu Social Network Analysis?
Social Network Analysis (SNA) adalah metode untuk mempelajari struktur sosial melalui teori graf. Dalam konteks market research, kita memodelkan:
- Node (simpul) = konsumen atau individu.
- Edge (sisi/panah) = hubungan antar konsumen, misalnya ‘A merekomendasikan produk kepada B’.
- Weight (bobot) = kekuatan hubungan, misalnya frekuensi rekomendasi.
Jaringan ini bisa directed (berarah, maksudnya A → B tidak sama dengan B → A) atau undirected (tidak berarah). Untuk analisa word-of-mouth, kita biasanya menggunakan directed graph karena rekomendasi memiliki arah.
Metrik Centrality: Mengukur “Kepentingan” Sebuah Node
Inti dari identifikasi super spreader adalah mencari dan menghitung semua metrik centrality. Ada empat metrik utama yang akan kita gunakan:
| Metrik | Definisi | Analogi |
|---|---|---|
| Degree centrality | Jumlah koneksi langsung yang dimiliki node | Orang yang paling banyak temannya |
| Betweenness centrality | Seberapa sering node menjadi jembatan jalur terpendek antar node lain | Broker atau perantara informasi |
| Closeness centrality | Seberapa dekat (rata-rata) node ke semua node lain | Orang yang paling cepat menerima informasi baru |
| Page rank | Pengaruh berbasis kualitas koneksi, bukan hanya kuantitas | Populer di kalangan orang-orang yang juga populer |
Mengapa diperlukan empat metrik yang berbeda?
Setiap metrik menangkap dimensi pengaruh yang berbeda. Seseorang bisa punya degree tinggi (banyak teman) tapi betweenness rendah (temannya saling kenal satu sama lain, jadi dia bukan jembatan kritis). Super spreader sejati biasanya tinggi di beberapa metrik sekaligus.
Oke, saya akan coba membuat data sintetis untuk sebagai contoh studi kasus.
Data Survey Minuman Kesehatan
Saya akan mensimulasikan sebuah brand minuman kesehatan yang baru diluncurkan. Tim marketing melakukan survei kepada 50 konsumen awal dengan pertanyaan:
“Apakah Anda pernah merekomendasikan produk ini kepada seseorang? Jika ya, siapa saja (nama atau inisial)?” dan “Dari siapa Anda pertama kali mendengar tentang produk ini?”
Dari survei ini, misalkan kita punya 50 orang konsumen. Kemudian kita mendapatkan edge list, yakni daftar pasangan konsumen (A merekomendasikan kepada B).
| from | to | weight |
|---|---|---|
| Andi | Budi | 1 |
| Andi | Citra | 1 |
| Andi | Dewi | 1 |
| Andi | Eko | 1 |
| Andi | Fani | 1 |
| Andi | Gilang | 1 |
| Andi | Hana | 1 |
| Andi | Irwan | 1 |
| Budi | Qori | 1 |
| Budi | Rafi | 1 |
| Citra | Joko | 1 |
| Citra | Kartika | 1 |
| Citra | Luki | 1 |
| Citra | Mira | 1 |
| Citra | Nanda | 1 |
| Citra | Oki | 1 |
| Citra | Prita | 1 |
| Dewi | Kevin | 1 |
| Dewi | Sinta | 1 |
| Evan | Cici | 1 |
| Evan | Dian | 1 |
| Fani | Juli | 1 |
| Galih | Zara | 1 |
| Gilang | Laras | 1 |
| Gilang | Mario | 1 |
| Hana | Nina | 1 |
| Irwan | Oscar | 1 |
| Irwan | Putri | 1 |
| Joko | Sinta | 1 |
| Joko | Tono | 1 |
| Joko | Umar | 1 |
| Joko | Vina | 1 |
| Joko | Wawan | 1 |
| Joko | Xena | 1 |
| Kartika | Evan | 1 |
| Kartika | Fitri | 1 |
| Kartika | Galih | 1 |
| Kartika | Hesti | 1 |
| Kartika | Imam | 1 |
| Laras | Agus | 1 |
| Luki | Reza | 1 |
| Mira | Sarah | 1 |
| Mira | Tegar | 1 |
| Nanda | Ulfa | 1 |
| Oki | Vino | 1 |
| Oki | Wulan | 1 |
| Prita | Xander | 1 |
| Rafi | Andi | 1 |
| Rafi | Yanti | 1 |
| Sinta | Agus | 1 |
| Sinta | Bagas | 1 |
| Sinta | Cici | 1 |
| Sinta | Dian | 1 |
| Sinta | Yudi | 1 |
| Sinta | Zara | 1 |
| Tono | Citra | 1 |
| Umar | Joko | 1 |
| Vina | Kartika | 1 |
| Vina | Sinta | 1 |
| Wawan | Bagas | 1 |
Untuk bisa melakukan social network analysis di R, kita perlu mengubah bentuk data di atas menjadi object graph.
# Buat directed graph dari edge list
g <- graph_from_data_frame(
d = df_edges,
directed = TRUE,
vertices = konsumen
)
Summary dari graph-nya adalah:
Jumlah node (konsumen): 50
Jumlah edge (rekomendasi): 60
Apakah graf connected? TRUE
Diameter jaringan: 5
Rata-rata path length: 2.738462
Densitas jaringan: 0.0245
Sekarang akan saya hitung semua metrik centrality. Tidak lupa saya menambahkan satu skor lagi bernama skor komposit yang merupakan rata-rata dari rank empat metrik yang ada. Artinya orang dengan ranking 1 memiliki centrality tertinggi. Maka skor komposit terendah menandakan konsumen tersebut merupakan super spreader.
# Hitung semua metrik centrality sekaligus
df_centrality <- data.frame(
nama = V(g)$name,
# Degree: jumlah koneksi langsung
# out-degree = berapa orang yang dia rekomendasikan
# in-degree = berapa orang yang merekomendasikan dia
degree_out = degree(g, mode = 'out'),
degree_in = degree(g, mode = 'in'),
degree_all = degree(g, mode = 'all'),
# Betweenness: seberapa sering jadi 'jembatan'
betweenness = betweenness(g, normalized = TRUE),
# Closeness: seberapa dekat ke semua node lain
closeness = closeness(g, mode = 'all', normalized = TRUE),
# PageRank: popularitas berbasis kualitas koneksi
pagerank = page_rank(g)$vector
) %>%
# Buat skor komposit: rata-rata rank dari semua metrik
mutate(
rank_degree = rank(-degree_all),
rank_betweenness = rank(-betweenness),
rank_closeness = rank(-closeness),
rank_pagerank = rank(-pagerank),
skor_komposit = (rank_degree + rank_betweenness +
rank_closeness + rank_pagerank) / 4
) %>%
arrange(skor_komposit)
Berikut ini adalah 10 orang konsumen yang termasuk ke dalam super spreader:
=== TOP 10 SUPER SPREADER ===
nama degree_out degree_in degree_all betweenness closeness pagerank
1 Citra 7 2 9 0.0536 0.4712 0.0290
2 Joko 6 2 8 0.0276 0.3889 0.0304
3 Sinta 6 3 9 0.0202 0.3712 0.0302
4 Andi 8 1 9 0.0391 0.4414 0.0205
5 Kartika 5 2 7 0.0183 0.3769 0.0232
6 Rafi 2 1 3 0.0204 0.3161 0.0188
7 Vina 2 1 3 0.0051 0.3224 0.0168
8 Tono 1 1 2 0.0111 0.3500 0.0168
9 Mira 2 1 3 0.0060 0.3311 0.0160
10 Oki 2 1 3 0.0060 0.3311 0.0160
rank_degree rank_betweenness rank_closeness rank_pagerank skor_komposit
1 2 1.0 1.0 6.0 2.500
2 4 3.0 3.0 4.0 3.500
3 2 5.0 5.0 5.0 4.250
4 2 2.0 2.0 15.5 5.375
5 5 6.0 4.0 14.0 7.250
6 10 4.0 16.0 24.0 13.500
7 10 11.0 13.0 30.0 16.000
8 22 7.0 7.0 30.0 16.500
9 10 9.5 8.5 41.0 17.250
10 10 9.5 8.5 41.0 17.250
Perhatikan bahwa ada lima orang super spreader yang memiliki skor komposit terendah.
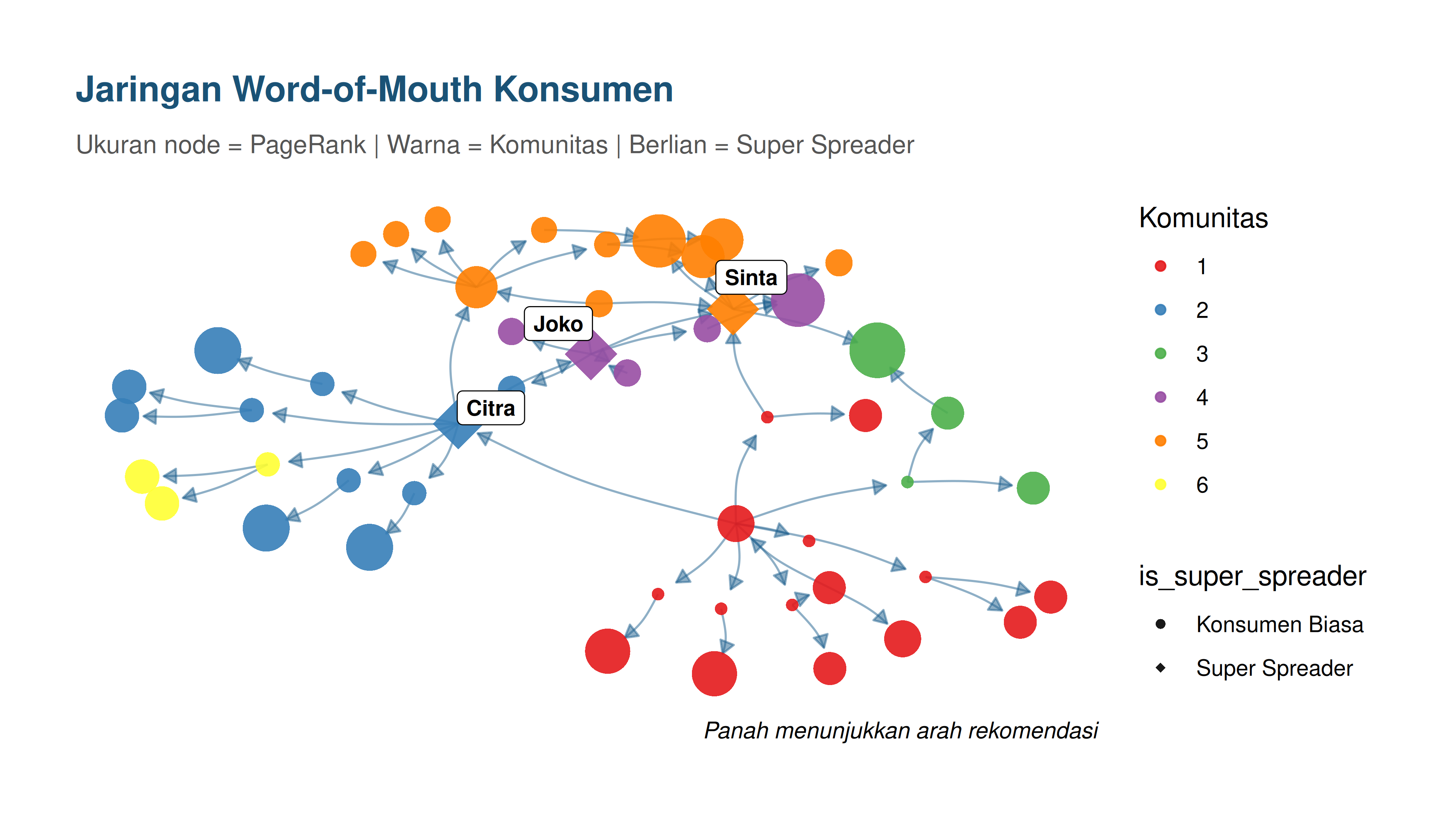
- Citra - Skor komposit: 2.5
- Joko - Skor komposit: 3.5
- Sinta - Skor komposit: 4.25
- Andi - Skor komposit: 5.375
- Kartika - Skor komposit: 7.25
Berikut adalah karakteristik masing-masing super spreader:
- Citra (Super Spreader #1)
- Degree centrality tertinggi: degree_all = 9 (maksimum)
- Betweenness centrality tertinggi: 0.0536 (ranking 1)
- Closeness centrality tertinggi: 0.4712 (ranking 1)
- PageRank: 0.029 (ranking 6)
- Karakteristik: Citra adalah hub utama dalam jaringan, memiliki koneksi keluar (degree_out = 7) yang sangat tinggi, berperan sebagai broker informasi (betweenness tinggi), dan dapat menjangkau semua node dengan cepat (closeness tinggi).
- Joko (Super Spreader #2)
- Degree_all: 8 (sangat tinggi)
- Betweenness: 0.0276 (ranking 3)
- Closeness: 0.3889 (ranking 3)
- PageRank: 0.0304 (ranking 4) - tertinggi di antara semua
- Karakteristik: Joko memiliki pengaruh yang kuat (PageRank tertinggi) meskipun degree centrality sedikit lebih rendah dari Citra.
- Sinta (Super Spreader #3)
- Degree_all: 9 (maksimum, sama dengan Citra)
- Betweenness: 0.0202 (ranking 5)
- Closeness: 0.3712 (ranking 5)
- PageRank: 0.0302 (ranking 5)
- Karakteristik: Sinta memiliki koneksi inbound yang lebih baik (degree_in = 3, tertinggi di antara super spreader), menunjukkan popularitas yang tinggi.
- Andi (Super Spreader #4)
- Degree_out: 8 (tertinggi)
- Betweenness: 0.0391 (ranking 2)
- Closeness: 0.4414 (ranking 2)
- PageRank: 0.0205 (ranking 15.5) - relatif rendah
- Karakteristik: Andi adalah eksporter informasi aktif (degree_out tertinggi) dan broker yang kuat, tetapi kurang berpengaruh dalam PageRank.
- Kartika (Super Spreader #5)
- Degree_all: 7 (tinggi)
- Betweenness: 0.0183 (ranking 6)
- Closeness: 0.3769 (ranking 4)
- PageRank: 0.0232 (ranking 14)
- Karakteristik: Kartika memiliki profil yang seimbang dengan semua metrik di atas rata-rata.
Saya bisa rangkum menjadi beberapa poin penting berikut ini:
1. Tipe Super Spreader:
- Citra: Complete Hub - Unggul di semua aspek.
- Joko: Influencer - PageRank tertinggi, pengaruh kuat.
- Sinta: Popular Connector - Koneksi inbound terbaik.
- Andi: Active Exporter - Outbound connections terkuat.
- Kartika: Balanced Connector - Profil seimbang.
2. Pola Koneksi:
- Citra & Sinta: Degree_all = 9 (full connectivity).
- Joko & Andi: Degree_out sangat tinggi (6 dan 8).
- Sinta: Degree_in tertinggi (3) - paling populer.
3. Peran dalam Jaringan:
- Broker (Betweenness tinggi): Citra, Andi, Joko.
- Influencer (PageRank tinggi): Joko, Sinta.
- Accessible (Closeness tinggi): Citra, Andi.
Untuk Marketing Campaign:
- Fokus pada Citra sebagai primary influencer - dampak terbesar.
- Gunakan Joko untuk viral campaigns karena PageRank tertinggi.
- Libatkan Sinta untuk endorsement karena popularitas inbound tinggi.
- Manfaatkan Andi untuk outreach aktif karena outbound connections kuat.
Segmentasi Super Spreader:
- Elite Influencers (Citra, Joko): Untuk brand awareness maksimal.
- Active Promoters (Andi): Untuk product launches.
- Community Connectors (Sinta, Kartika): Untuk engagement programs.
Deteksi Cluster dalam Komunitas
Selain menemukan super spreader, kita juga bisa mencari tahu apakah ada kelompok-kelompok (clusters) konsumen yang lebih sering berinteraksi satu sama lain. Hal ini penting untuk strategi segmentasi pesan marketing.
Untuk community detection, saya menggunakan undirect graph dengan metode Louvain.
Metode Louvain adalah algoritma populer untuk menemukan kelompok (komunitas) dalam jaringan besar dengan cara memaksimalkan nilai modularity, yaitu ukuran yang menilai seberapa kuat hubungan antar node di dalam kelompok dibandingkan hubungan acak. Prosesnya terdiri dari dua fase yang berulang: pertama, algoritma memindahkan setiap node ke komunitas tetangganya secara rakus (greedy) untuk melihat apakah kepadatan koneksi meningkat; kedua, node-node yang sudah berkelompok tersebut disatukan menjadi satu “node raksasa” untuk membentuk jaringan baru yang lebih ringkas. Langkah-langkah ini terus diulangi hingga tidak ada lagi perpindahan yang bisa meningkatkan kualitas pengelompokan, sehingga menghasilkan struktur komunitas yang hierarkis dan efisien secara komputasi.
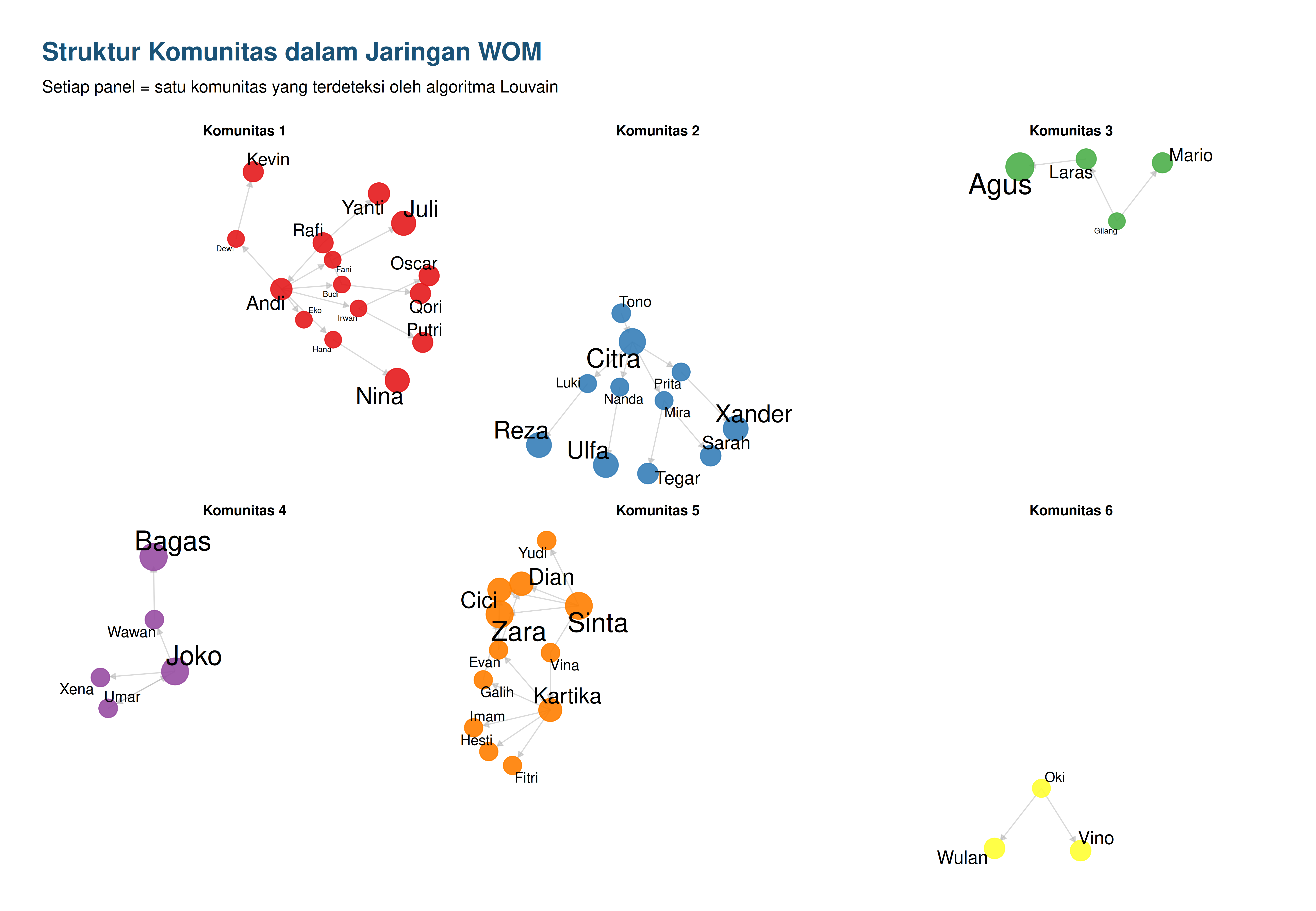
Berikut adalah kelompok-kelompok konsumen yang dihasilkan:
Modularity Louvain: 0.5956
| kelompok | n_anggota | anggota |
|---|---|---|
| 1 | 15 | Andi, Budi, Dewi, Eko, Fani, Hana, Irwan, Qori, Rafi, Juli, Kevin, Nina, Oscar, Putri, Yanti |
| 5 | 12 | Kartika, Sinta, Vina, Yudi, Zara, Cici, Dian, Evan, Fitri, Galih, Hesti, Imam |
| 2 | 11 | Citra, Luki, Mira, Nanda, Prita, Tono, Reza, Sarah, Tegar, Ulfa, Xander |
| 4 | 5 | Joko, Umar, Wawan, Xena, Bagas |
| 3 | 4 | Gilang, Agus, Laras, Mario |
| 6 | 3 | Oki, Vino, Wulan |
Terlihat ada 6 kelompok dengan banyaknya anggota bervariasi. Kelompok pertama merupakan kelompok terbesar berisikan 15 orang konsumen. Selanjutnya adalah kelompok 5 dan 2 yang berisi 12 orang dan 11 orang konsumen.
Visualisasi Graph
Berikut adalah beberapa visualisasi dari graph yang dibentuk:
Implikasi dari Social Network Analysis yang Dihasilkan
Dari uraian yang saya paparkan di atas, salah satu kegunaan dari SNA adalah kita bisa melakukan simulasi bagaimana penyebaran informasi terjadi. Perbedaan orang yang memulai kabar akan membedakan seberapa cepat kabar tersebut beredar. Sebagai contoh, saya akan coba buat simulasi penyebaran kabar dengan menggunakan prinsip model SIR (saya pernah menggunakan model ini untuk memodelkan penyebaran hoax).
Saya akan mencoba dua skenario, yakni:
- Saat kabar dimulai dari super spreader, misalkan: Citra.
- Saat kabar dimulai dari orang biasa, misalkan: Oki.
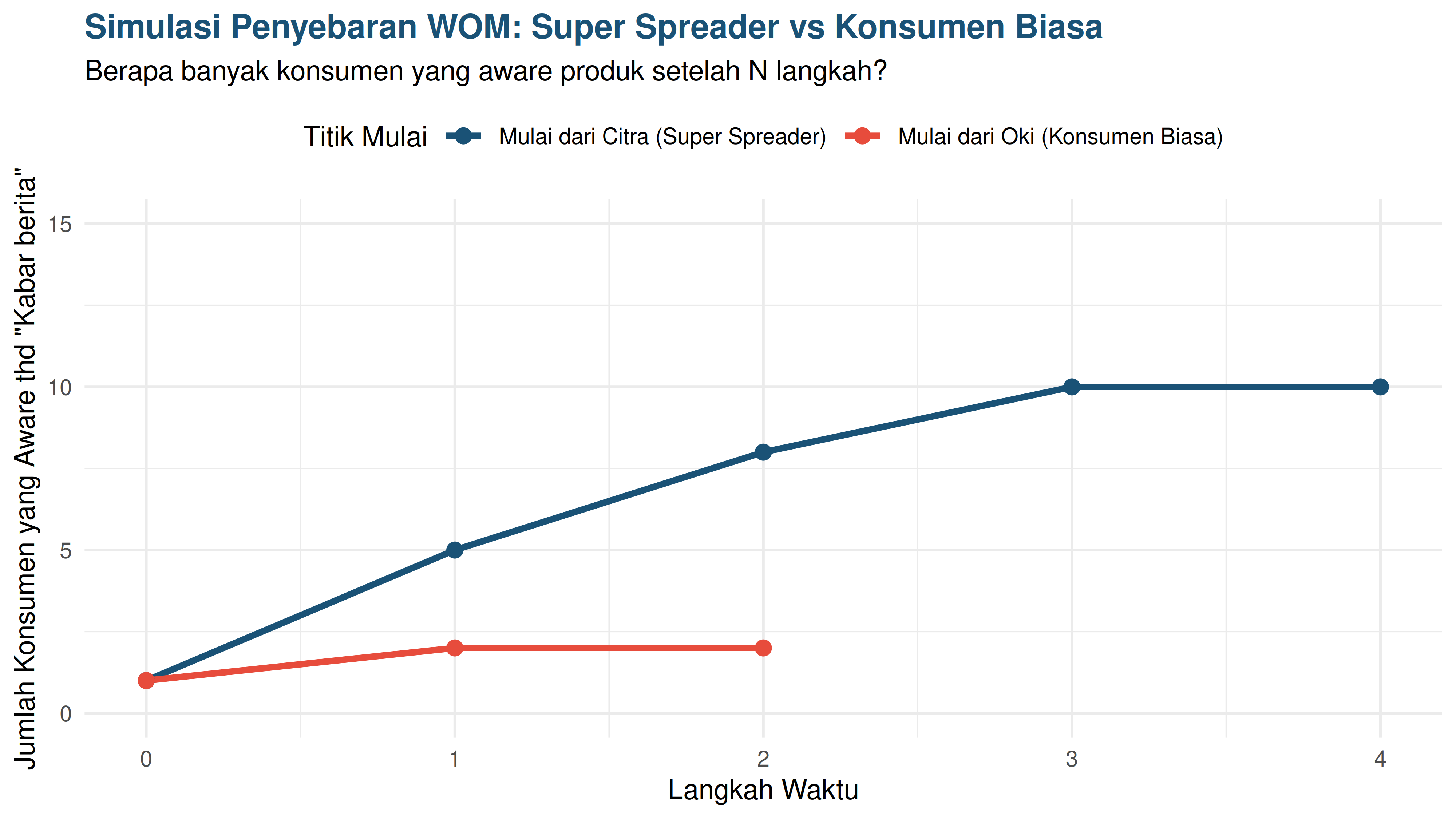
Hanya butuh 3 langkah waktu bagi Citra agar 10 orang dalam circle-nya menjadi aware dengan kabar berita. Sedangkan kabar yang disebar dari Oki hanya diketahui oleh dua orang saja.
if you find this article helpful, support this blog by clicking the ads.