
Exploratory Model Analysis: Kenapa Pemain Bola Dihargai Mahal?
Artificial intelligence (AI) adalah salah satu buzzwords yang sedang terkenal belakangan ini. Salah satu cabang pembahasan AI yang sekarang ini cukup berkembang adalah Responsible AI.
Apa sih responsible AI?
Banyak orang berkata bahwa AI tidak mungkin salah alias flawless. Ucapan tersebut benar jika dikatakan dalam lingkup otomasi well-defined jobs.
Tapi saat kita mengandalkan AI untuk melakukan prediksi dan klasifikasi, ucapan tersebut harus diperhatikan dengan seksama. Saya pernah menuliskan tentang bias yang mungkin muncul saat kita membuat atau menggunakan algoritma machine learning, deep learning, atau AI.
Oleh karena itu, kita harus bisa mengeliminir bias tersebut. Apalagi
bias yang bisa ditimbulkan saat kita mengikutsertakan variables
seperti gender atau SARA saat kita membuat algoritmanya.
Black Box
Beberapa model prediksi seperti random forest, XGBoost, sampai Artificial Neural Network bekerja seperti black box.
Apa lagi ini maksudnya?
Saya jelaskan dengan contoh sederhana ya:
Misalkan saya memiliki 1.000 baris data dari 50 kolom variables.
Misalkan saya ingin memprediksi sesuatu kondisi dari data tersebut
dengan algoritma Artificial Neural Network.
Maka hal yang saya lakukan adalah melempar data tersebut ke dalam
ANN dan kita akan dapatkan output hasil prediksinya.

ANN secara otomatis akan belajar dan memberikan prediksi terbaiknya kepada kita.
TAPI, jika kita bertanya-tanya:
Mengapa hasil prediksinya seperti ini? Kenapa tidak seperti itu? Dari
50variables, mana saja yang penting?
Kita tidak akan pernah bisa mendapatkan jawaban dari model tersebut.
Oleh karena itu deep learning (machine learning algorithm yang berbasis Neural Network) selalu saya katakan sebagai hal ghaib yang terjadi nyata di kehidupan sehari-hari.
- Inputnya ada, yakni datanya.
- Prosesnya perhitungannya nyata tapi kita tidak bisa melihat bagaimana mesin bisa belajar.
- Outputnya ada berupa hasil prediksi.
TAPI kita kehilangan
whydalam algoritma ini!
More Traditional Algorithm
Jika beberapa algoritma terbaru tersebut susah untuk menjelaskan
why-nya, kenapa kita tidak pakai algoritma jadul saja?
Algoritma-algoritma jadul seperti keluarga regresi dan
discriminant analysis lebih mudah bagi kita untuk mengekplorasi sisi
why-nya.
Tapi masalahnya algoritma jadul tersebut konon kurang reliable saat berhadapan dengan data berskala besar dengan struktur yang lebih aneh juga (contoh: data images. Bagi yang belum baca, coba baca deh. Ada penjelasan terkait ANN dan Tensorflow).
Oleh karena itu, kita membutuhkan suatu tools yang bisa menjelaskan
sisi why dari algoritma kekinian seperti ANN.
Explainable AI
Saat ini ada beberapa libraries di R yang bisa digunakan untuk membedah cara kerja dari algoritma. Analoginya seperti ini:
Kalau dulu kita biasa melakukan exploratory data analysis, sekarang kita akan melakukan exploratory model analysis.
Alih-alih menganalisa datanya, kita akan fokus menganalisa modelnya (baca: algoritmanya).
Proses inilah yang disebut dengan explainable AI (atau interpretable machine learning).
Gimana? Sudah cukup bingung?
Saya akan gunakan contoh sesuai dengan judul tulisan ini yah.
Problem
Kenapa pemain bola dihargai mahal?
Beberapa saat lalu, saya mengambil data dari FIFA terkait statistik pemain dan nilai harga transfer mereka.
Sejak SMA dulu, saya penasaran apa sih yang membuat seorang pemain bola dihargai mahal?
Dari sekian puluh ribu data pemain, saya hanya akan melihat pemain-pemain bola dengan kondisi:
- Bukan goal keeper dan pemain belakang.
- Memiliki harga minimal
10juta Euro.
Sehingga saya dapatkan 341 baris data pemain bola. Lalu saya hanya
akan melihat 14 variables berikut ini:
## [1] "name" "age" "target" "crossing" "finishing"
## [6] "dribbling" "ball_control" "acceleration" "agility" "reactions"
## [11] "balance" "shot_power" "stamina" "strength" "positioning"
## [16] "vision"
Variables di atas akan saya gunakan untuk memprediksi harga pemain.
Saya mengeliminir faktor-faktor lain seperti reputasi dan fame.
Berikut adalah cuplikan data yang digunakan:
| name | age | harga_dlm_juta | crossing | finishing | dribbling | ball_control | acceleration | agility | reactions | balance | shot_power | stamina | strength | positioning | vision |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L. Messi | 31 | 110.5 | 84 | 95 | 97 | 96 | 91 | 91 | 95 | 95 | 85 | 72 | 59 | 94 | 94 |
| Cristiano Ronaldo | 33 | 77.0 | 84 | 94 | 88 | 94 | 89 | 87 | 96 | 70 | 95 | 88 | 79 | 95 | 82 |
| Neymar Jr | 26 | 118.5 | 79 | 87 | 96 | 95 | 94 | 96 | 94 | 84 | 80 | 81 | 49 | 89 | 87 |
| K. De Bruyne | 27 | 102.0 | 93 | 82 | 86 | 91 | 78 | 79 | 91 | 77 | 91 | 90 | 75 | 87 | 94 |
| E. Hazard | 27 | 93.0 | 81 | 84 | 95 | 94 | 94 | 95 | 90 | 94 | 82 | 83 | 66 | 87 | 89 |
| L. Modrić | 32 | 67.0 | 86 | 72 | 90 | 93 | 80 | 93 | 90 | 94 | 79 | 89 | 58 | 79 | 92 |
Membuat Regression Model dengan Deep Learning
Untuk menjawab pertanyaan saya tersebut, saya akan membuat model regresi:
Alih-alih membuat model regresi biasa, saya akan membuat model regresi dengan deep learning menggunakan Tensorflow. Mungkin terlihat overkill tapi worth to try.
Berikut langkah kerjanya:

Berikut adalah model yang saya buat:

Bagaimana performa modelnya?
## Performa Model
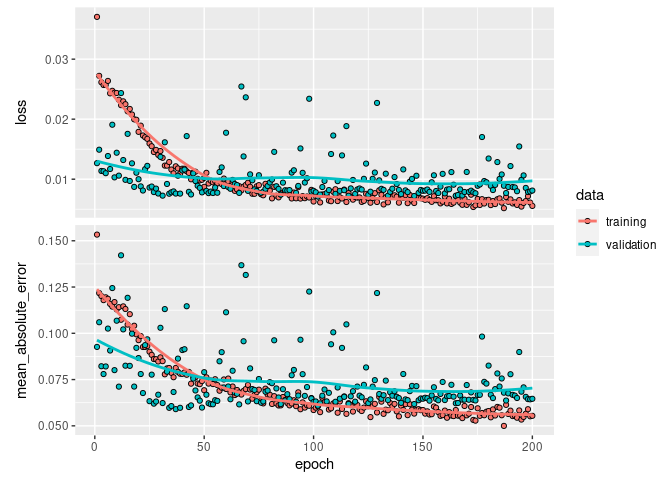
## Hasil Validasi Model dengan Test Dataset
## Measures for: regression
## mse : 0.004932182
## rmse : 0.0702295
## r2 : 0.8910342
## mad : 0.03040409
##
## Residuals:
## 0% 10% 20% 30% 40% 50%
## -0.142171518 -0.053362463 -0.027217926 -0.018586988 -0.004533927 0.007816591
## 60% 70% 80% 90% 100%
## 0.018197898 0.032700665 0.056591385 0.108786733 0.211647391
Performa modelnya acceptable, nilai mean standard error-nya kecil
dan nya
lumayan.
Sekarang saya akan melakukan exploratory model analysis dari model deep learning ini.
Exploratory Model Analysis
Features Importance
Problem utama yang saya ingin selesaikan adalah:
Apa yang membuat pemain bola dihargai mahal?
Maka dari itu, saya perlu mengetahui. Dari sekian banyak variables yang ada, mana yang merupakan variable terpenting?
Analisa yang bisa dilakukan adalah features importance. Berikut adalah features importance dari model saya:

Features importance ini didapatkan dengan cara melakukan permutasi terhadap semua variables yang ada.
Jadi untuk mengetahui seberapa penting
reactionsterhadap model prediksi ini. Algoritma melakukan permutasi terhadap isi variablereactions(sedangkan isi variables lainnya dibiarkan tetap sama) lalu memasukkannya ke dalam model prediksi.
Perubahan output yang terjadi akan menjadi dasar penentuan seberapa penting variabel ini kelak.
Partial Dependence Profile
Kita sudah melihat dari grafik sebelumnya bahwa top 4 variables yang penting terhadap harga pemain bola adalah:
reactionsball_controlagedribbling
Permasalahannya adalah kita belum mengetahui apa efek dari masing-masing variable tersebut.
Apakah berefek positif atau negatif?
Maksudnya apa?
- Positif, contoh:
Apakah dengan semakin bagus reactions, maka harganya semakin mahal? - Negatif, contoh:
Apakah semakin tua seorang pemain maka harganya semakin murah?
Untuk menjawabnya, saya akan melakukan analisa partial dependence profile.
Bagaimana caranya?
Misalkan saya ingin mengetahui efek dari age. Maka yang saya lakukan
adalah membuat variables lainnya fixed (misalkan dengan mean,
median, atau modus) lalu menjadikan age bergerak nilainya.
Sekarang saya akan coba hitung efeknya untuk beberapa variables berikut ini:
 Dari grafik di atas terlihat dengan jelas bahwa:
Dari grafik di atas terlihat dengan jelas bahwa:
- Semakin tua umur pemain, harganya semakin turun dengan landai.
- Semakin tinggi
reactionsdanball controlseorang pemain, harganya semakin tinggi dengan cepat.
Break Down
Kalau dua analisa di atas adalah analisa yang terkait model secara global. Kali ini saya akan melakukan analisa dalam lingkup kecil, yakni: per pemain bola.
Maksudnya gimana?
Misalkan saya ingin tahu kenapa Cristiano Ronaldo dihargai sekian? Kenapa Messi sekian? Kenapa Griezmann sekian? Kenapa Bruno Fernandes sekian?
## CRISTIANO RONALDO

## LIONEL MESSI

## GRIEZMANN

## BRUNO FERNANDES
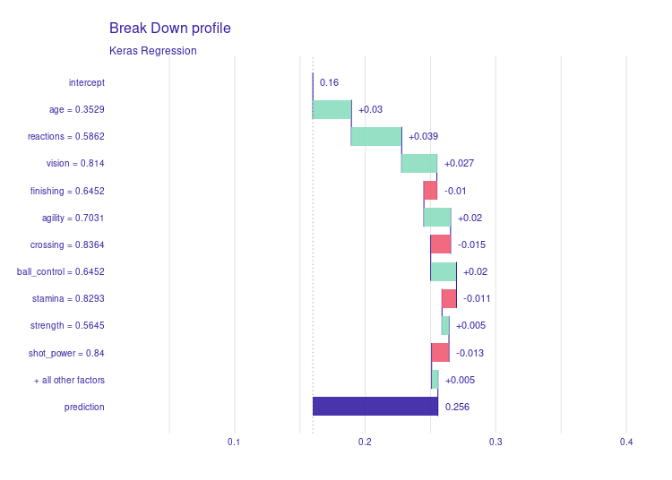
Ada yang bisa menyimpulkan grafik di atas?
Notes
Seluruh exploratory model analysis yang saya lakukan di atas
diselesaikan menggunakan library(DALEX) di R.