
Exploratory Model Analysis: Jaga Gula Darah Biar Gak Kena Diabetes Ya
Tulisan ini mengambil tema yang sama terkait eXplainable Artificial Intelligence yang pernah saya tulis sebelumnya.
Saya termasuk salah seorang keturunan diabetes. Beberapa anggota keluarga dari garis ayah dan ibu saya meninggal akibat komplikasi diabetes. Menurut data dari Riset Kesehatan Dasar (Riskedas) Kementrian Kesehatan 2018, prevalensi diabetes mencapai angka 10.9%. Asal teman-teman tahu, angka Riskesdas didapatkan dari diabetesi yang sudah didiagnosis oleh dokter. Sedangkan jika kita lihat sekilas di sekitaran kita, masih banyak orang yang tidak suka atau tidak mau berkonsultasi ke dokter.
Saya menduga angka prevalensi yang asli lebih banyak dibandingkan angka yang ada di Riskesdas.
Saya sempat bertanya kepada salah seorang teman saya yang bekerja di bidang biology and health science, penegakan diagnosis diabetes itu biasanya berdasarkan cek laboratorium berupa gula darah, Oral Glucose Tolerance Test (OGTT) atau HbA1C.
Orang awam seperti kita ini biasanya hanya mengira bahwa faktor yang paling terlihat dari seorang diabetesi adalah kadar gula darahnya.
Pernah saya mencari data publik yang detail di Indonesia tapi belum menemukannya. Sampai suatu saat saya sedang menjelajahi situs Kaggle kemudian saya menemukan data Pima Indians Diabetes Database. Berikut adalah deskripsi dari data tersebut:
Pima Indian Diabetes Database
Context
This dataset is originally from the National Institute of Diabetes and Digestive and Kidney Diseases. The objective of the dataset is to diagnostically predict whether or not a patient has diabetes, based on certain diagnostic measurements included in the dataset. Several constraints were placed on the selection of these instances from a larger database. In particular, all patients here are females at least 21 years old of Pima Indian heritage.
Content
The datasets consists of several medical predictor variables and one target variable, Outcome. Predictor variables includes the number of pregnancies the patient has had, their BMI, insulin level, age, and so on.
Kali ini saya akan mencoba membuat model prediksi berdasarkan data tersebut kemudian melakukan analisa eksplorasi terhadap model prediksi tersebut. Tapi jangan berharap tulisan ini sekelas jurnal penelitian ya, saya hanya ingin melakukan iseng-iseng berhadiah saja.
Seperti tulisan sebelumnya, saya akan membuat model prediksi deep
learning dan di-explain dengan DALEX.
Exploratory Model Analysis
Data
Berikut adalah cuplikan dataset yang saya gunakan:
| id_person | pregnancies | glucose | blood_pressure | skin_thickness | insulin | bmi | diabetes_pedigree_function | age | outcome |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 2 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 3 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 4 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 5 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
| 6 | 5 | 116 | 74 | 0 | 0 | 25.6 | 0.201 | 30 | 0 |
| 7 | 3 | 78 | 50 | 32 | 88 | 31.0 | 0.248 | 26 | 1 |
| 8 | 10 | 115 | 0 | 0 | 0 | 35.3 | 0.134 | 29 | 0 |
| 9 | 2 | 197 | 70 | 45 | 543 | 30.5 | 0.158 | 53 | 1 |
| 10 | 8 | 125 | 96 | 0 | 0 | 0.0 | 0.232 | 54 | 1 |
| 11 | 4 | 110 | 92 | 0 | 0 | 37.6 | 0.191 | 30 | 0 |
| 12 | 10 | 168 | 74 | 0 | 0 | 38.0 | 0.537 | 34 | 1 |
| 13 | 10 | 139 | 80 | 0 | 0 | 27.1 | 1.441 | 57 | 0 |
| 14 | 1 | 189 | 60 | 23 | 846 | 30.1 | 0.398 | 59 | 1 |
| 15 | 5 | 166 | 72 | 19 | 175 | 25.8 | 0.587 | 51 | 1 |
Berikut adalah struktur dari dataset tersebut:
## 'data.frame': 768 obs. of 9 variables:
## $ pregnancies : int 6 1 8 1 0 5 3 10 2 8 ...
## $ glucose : int 148 85 183 89 137 116 78 115 197 125 ...
## $ blood_pressure : int 72 66 64 66 40 74 50 0 70 96 ...
## $ skin_thickness : int 35 29 0 23 35 0 32 0 45 0 ...
## $ insulin : int 0 0 0 94 168 0 88 0 543 0 ...
## $ bmi : num 33.6 26.6 23.3 28.1 43.1 25.6 31 35.3 30.5 0 ...
## $ diabetes_pedigree_function: num 0.627 0.351 0.672 0.167 2.288 ...
## $ age : int 50 31 32 21 33 30 26 29 53 54 ...
## $ outcome : int 1 0 1 0 1 0 1 0 1 1 ...
Dari semua variables yang ada, saya tidak menggunakan semuanya sebagai predictor. Berikut adalah variables yang saya masukkan ke dalam model yang saya buat:
pregnancies: berapa kali wanita tersebut hamil,glucose: kadar gula darahbmi: body mass index (indeks massa tubuh. Didapatkan dari perhitungan rasio berat dan tinggi badan),age: usia, dandiabetes_pedigree_function: keturunan diabetes.
Target variable dari model saya adalah variabel outcome yang berisi:
0untuk non diabetes.1untuk diabetes.
Ternyata setelah saya cek datanya kembali, saya berhadapan dengan imbalance dataset.
| outcome | freq |
|---|---|
| Diabetes | 268 |
| Non Diabetes | 500 |
Oleh karena itu, train dataset yang akan saya gunakan harus saya paksa menjadi balance terlebih dahulu.
Berikut adalah langkah-langkah yang saya lakukan:
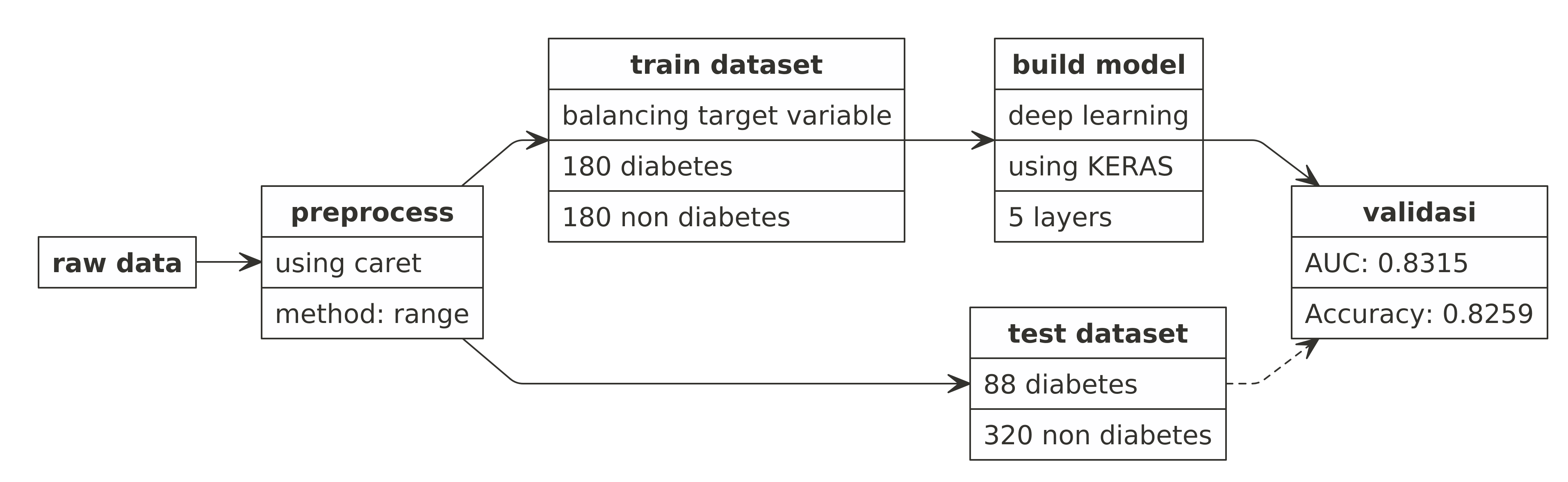
Performa Model
Berikut adalah parameter performa model yang saya gunakan:
performa_model$measures$accuracy
## [1] 0.8259804
performa_model$measures$auc
## [1] 0.8315696
Saya hanya melihat dari dua parameter saja, yakni accuracy dan luas area under curve (AUC).
Mari kita lihat bersama beberapa penjelasan dari model tersebut:
Features Importance
Dari 5 variables yang saya jadikan predictor, variabel mana yang
paling penting untuk memprediksi seorang wanita (di India) termasuk
diabetes atau tidak?
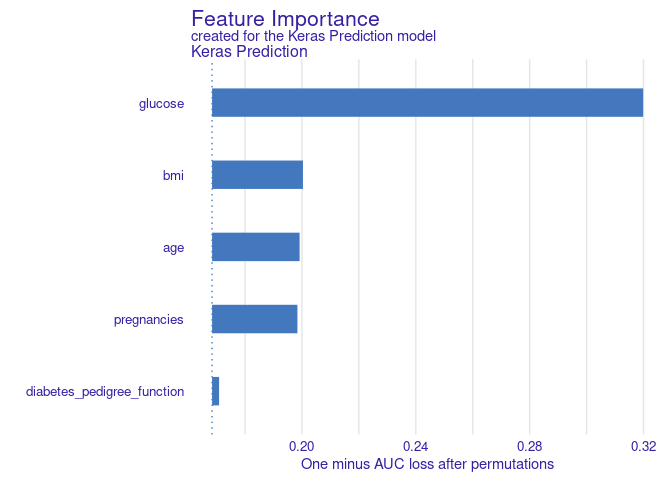
Ternyata obvious glucose menjadi satu variabel yang paling
terpenting dalam memprediksi seorang wanita (di India) terkena diabetes
atau tidak.
Hal yang menarik adalah bmi, age dan pregnancies memiliki bobot
yang hampir sama tapi diabetes_pedigree memiliki andil yang kecil
dalam model.
Walaupun keturunan diabetes 6x lebih beresiko terkena diabetes tidak menjadikan orang tanpa keturunan menjadi aman ya!
Partial Dependence Profile
Sekarang saya akan melihat dari 4 variabel teratas, bagaimana
kontribusinya terhadap prediksi diabetes atau tidak.
plot(mp_ball)
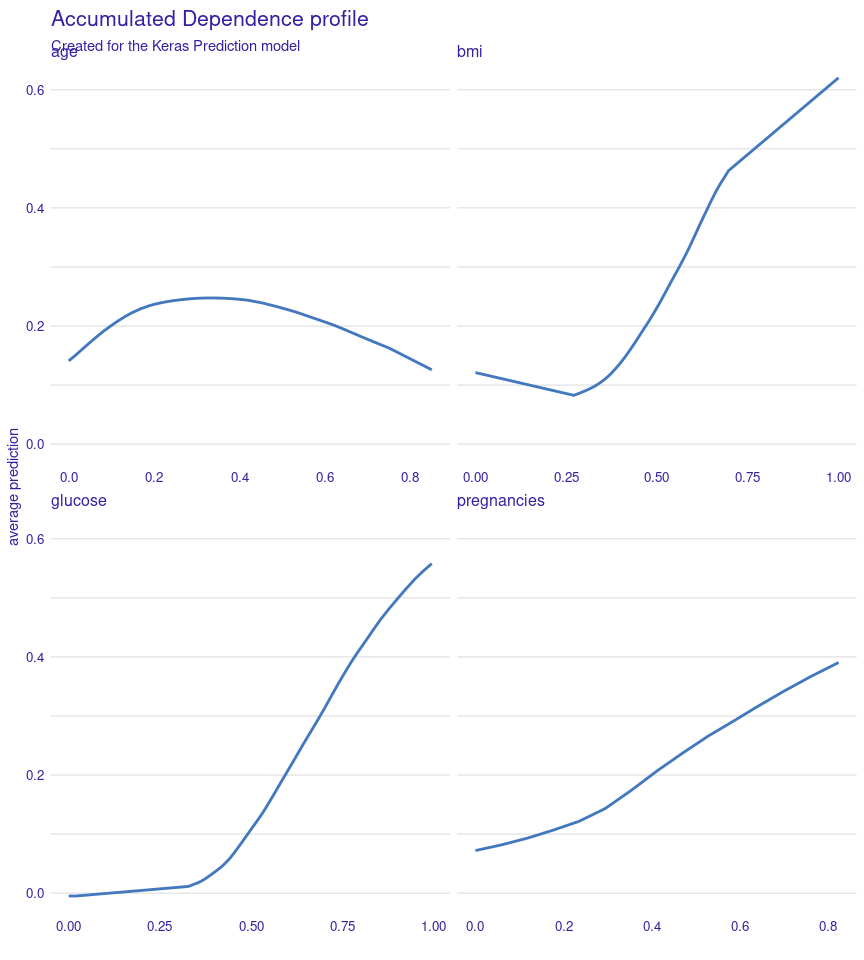
Dari grafik di atas, kita melihat bahwa variabel glucose dan bmi
memiliki kenaikan yang sangat curam saat nilainya makin ke kanan
dibandingkan pregnancies.
Salah satu key point dari grafik di atas adalah menjaga glucose dan
bmi (rasio berat dan tinggi badan) bisa menjadi kunci menurunkan
resiko diabetes (setidaknya untuk wanita India).
Sayangnya tidak ada data Indonesia yang cukup sehingga bisa dianalisa seperti ini.
if you find this article helpful, support this blog by clicking the
ads.