
Anomaly Detection dalam Survey Online dan Bagaimana Mendeteksinya dengan Statistik / Machine Learning
Sepanjang karir saya di industri market riset, metode online survey merupakan salah satu metode yang paling saya tak rekomendasikan untuk dilakukan. Alasannya sederhana: kita tidak bisa memastikan siapa yang mengisi dan apakah diisi dengan benar. Walaupun online survey memiliki keuntungan secara timeline pengumpulan data yang cepat.
Namun saat pandemi kemarin, mau tak mau (hampir) semua project market riset harus dilakukan secara online survey. Untuk mengurangi bias dan pengisian bohong, kami coba membuat sistem rekrutmen responden sehingga kita bisa memastikan responden pengisi survey adalah benar-benar target responden yang diinginkan. Namun tetap kita tak bisa memastikan apakah isi kuesioner itu sudah baik dan berkualitas.
Setidaknya ada beberapa tipe responden yang bisa merusak kualitas data hasil online survey:
- Speedsters: mengisi secara cepat di luar kewajaran.
- Straightliners: mengisi semua pertanyaan secara seragam.
- Random clickers: mengisi semua pertanyaan secara acak.
- Flip-flopers: jawaban kontradiktif dalam satu survei.
- Duplicate Responses: satu orang responden mengisi survey berkali-kali.
Oleh karena itu, tantangan terbesarnya adalah bagaimana melakukan anomaly detection dalam online survey hanya berbekal isi dari jawaban responden.
Untuk itu setidaknya ada dua cara untuk mendeteksi keberadaan anomali pada data hasil survey:
- Cara sederhana menggunakan analisa statistika deskriptif:
- Mendeteksi outlier pada waktu pengisian survey dari semua responden. Waktu penyelesaian survei abnormal (terlalu cepat/lambat).
- menghitung variasi jawaban untuk melihat apakah responden termasuk straightliners atau flip-flopers.
- Cara menggunakan machine learning: membuat model isolation forest dari data untuk mendeteksi anomali.
Saya akan coba mendemokan kedua cara di atas menggunakan R sebagai berikut:
Membuat Data Survey Dummy (1000 Responden)
Kita simulasi data survei dengan:
- Variabel: Usia, Jenis Kelamin, 5 pertanyaan skala likert (skala 1-5).
- Anomali yang hendak dicari:
- Speedsters (waktu jawab < 30 detik).
- Straightliners (jawaban sama untuk semua pertanyaan).
- Flip-flopers (misal: jawaban ekstrem seperti 1 dan 5 bersamaan).
library(dplyr)
library(tidyr)
# Buat data dummy
n = 1000
data = tibble(
id = 1:n,
usia = sample(18:60, n, replace = TRUE),
gender = sample(c("L", "P"), n, replace = TRUE),
q1 = sample(1:5, n, replace = TRUE),
q2 = sample(1:5, n, replace = TRUE),
q3 = sample(1:5, n, replace = TRUE),
q4 = sample(1:5, n, replace = TRUE),
q5 = sample(1:5, n, replace = TRUE),
waktu_jawab = rpois(n, lambda = 90) # Waktu dalam detik
)
# banyak responden yang anomali
n_anom_speed = 101
n_aom_strait = 30
n_aom_inkon = 20
# Tambahkan fraud: Speedsters (waktu < 30 detik)
data$waktu_jawab[sample(1:n, n_anom_speed)] = rpois(n_anom_speed, lambda = 30)
# Tambahkan fraud: Straightliners (jawaban sama semua)
data[sample(1:n, n_aom_strait), 4:8] = matrix(rep(sample(1:5,
n_aom_strait,
replace = TRUE),
each = 5),
nrow = 5,
ncol = n_aom_strait) %>% t()
# Tambahkan fraud: Flip-flopers (jawaban 1 dan 5 dalam survei yang sama)
data[sample(1:n, n_aom_inkon), 4:8] = replicate(n_aom_inkon, c(1, sample(2:4, 3), 5)) %>% t()
# Lihat sampel data
head(data,10) %>% knitr::kable()
| id | usia | gender | q1 | q2 | q3 | q4 | q5 | waktu_jawab |
|---|---|---|---|---|---|---|---|---|
| 1 | 48 | L | 4 | 3 | 4 | 5 | 3 | 78 |
| 2 | 32 | P | 5 | 1 | 3 | 1 | 1 | 88 |
| 3 | 28 | P | 1 | 2 | 1 | 4 | 4 | 82 |
| 4 | 18 | P | 5 | 1 | 4 | 5 | 2 | 82 |
| 5 | 48 | L | 3 | 3 | 2 | 5 | 3 | 84 |
| 6 | 48 | P | 3 | 5 | 2 | 5 | 1 | 72 |
| 7 | 53 | P | 3 | 5 | 4 | 5 | 5 | 81 |
| 8 | 35 | P | 2 | 1 | 4 | 2 | 5 | 76 |
| 9 | 56 | L | 4 | 1 | 1 | 1 | 3 | 95 |
| 10 | 57 | P | 3 | 3 | 5 | 1 | 1 | 90 |
Cara Pertama: Statistika Deskriptif
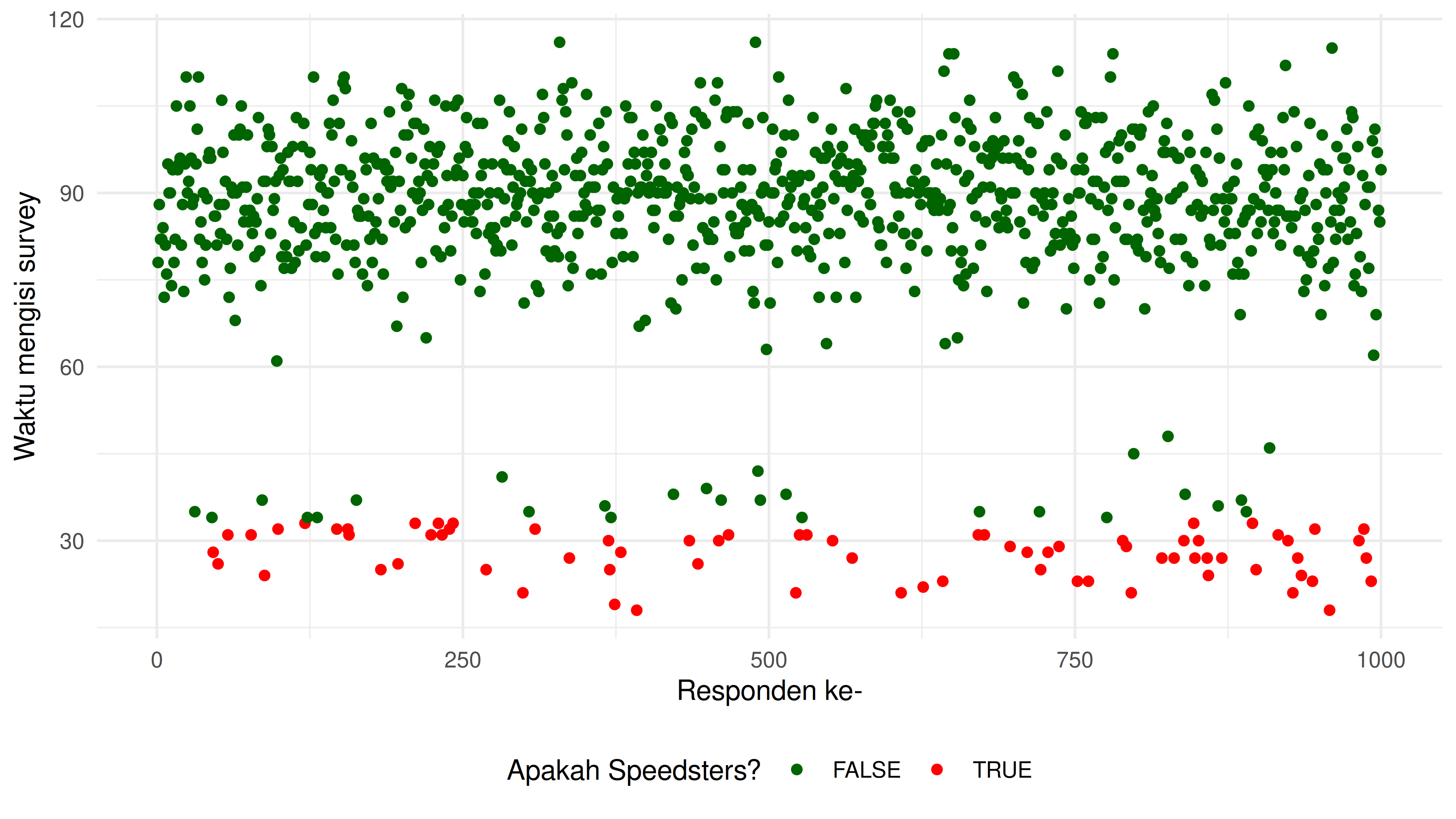
a. Deteksi Speedsters (Waktu Jawab Abnormal)
Untuk mendeteksi speedsters, saya akan menggunakan Z-score sebagai
marker apakah responden tersebut outlier atau bukan. Saya memilih
threshold sebesar
.
Maka untuk setiap
,
maka responden tersebut termasuk speedsters.
Jika Anda memiliki nilai
sebesar -2.5, ini berarti nilai tersebut terletak 2.5 standar deviasi di bawah rata-rata. Nilai tersebut akan dianggap sebagai tidak biasa atau signifikan.
# Hitung Z-score waktu_jawab
data =
data %>%
mutate(
z_score = (waktu_jawab - mean(waktu_jawab)) / sd(waktu_jawab),
is_speed = ifelse(z_score < -2.5, TRUE, FALSE) # Threshold Z-score
)
b. Deteksi Straightliners (Pola Jawaban Sama)
Untuk mendeteksi keberadaan straightliners, kita cukup menghitung standar deviasi jawaban per responden. Jika standar deviasinya sama dengan 0, artinya responden tersebut straightliners.
data =
data %>%
rowwise() %>%
mutate(
sd_jawaban = sd(c(q1, q2, q3, q4, q5)),
is_straight = ifelse(sd_jawaban == 0, TRUE, FALSE)
)
| id | usia | q1 | q2 | q3 | q4 | q5 |
|---|---|---|---|---|---|---|
| 62 | 52 | 5 | 5 | 5 | 5 | 5 |
| 86 | 29 | 1 | 1 | 1 | 1 | 1 |
| 93 | 52 | 1 | 1 | 1 | 1 | 1 |
| 148 | 32 | 2 | 2 | 2 | 2 | 2 |
| 189 | 45 | 1 | 1 | 1 | 1 | 1 |
| 223 | 30 | 5 | 5 | 5 | 5 | 5 |
c. Deteksi Flip-flopers (Jawaban Kontradiktif)
Misalkan responden yang memberi nilai 1 dan 5 dalam survey yang sama padahal pertanyaan dirancang untuk konsisten satu sama lain.
data =
data %>%
mutate(
min_jawaban = pmin(q1, q2, q3, q4, q5),
max_jawaban = pmax(q1, q2, q3, q4, q5),
is_flip = ifelse(min_jawaban == 1 & max_jawaban == 5, TRUE, FALSE)
)
| id | usia | q1 | q2 | q3 | q4 | q5 |
|---|---|---|---|---|---|---|
| 2 | 32 | 5 | 1 | 3 | 1 | 1 |
| 4 | 18 | 5 | 1 | 4 | 5 | 2 |
| 6 | 48 | 3 | 5 | 2 | 5 | 1 |
| 8 | 35 | 2 | 1 | 4 | 2 | 5 |
| 10 | 57 | 3 | 3 | 5 | 1 | 1 |
| 11 | 48 | 5 | 3 | 4 | 1 | 3 |
d. Gabungkan Semua Anomaly Indicators
Sekarang kita gabungkan semua anomaly indicators dan hitung berapa banyak responden yang terindikasi sebagai “fraud”.
data =
data %>%
mutate(
is_fraud = is_speed | is_straight | is_flip
)
Kita bisa mendapatkan 498 orang responden yang terindikasi “fraud”.
Cara Kedua: Machine Learning
Cara alternatif untuk mendeteksi anomali adalah menggunakan model
machine learning. Model yang bisa kita gunakan bernama Isolation
Forest. Kita bisa memanfaatkan library(solitude) di R untuk
membuatnya.
a. Konsep Isolation Forest
Isolation Forest adalah algoritma yang bekerja dengan prinsip:
- “Anomali lebih mudah diisolasi daripada data normal”.
- Algoritma membangun random decision trees (pohon keputusan acak) untuk mengisolasi setiap observasi.
- Observasi yang memerlukan sedikit split untuk diisolasi dianggap sebagai anomali.
Penjelasan di atas mungkin sulit dimengerti, maka saya akan gunakan analogi seperti ini:
Analogi: Mencari Baju Kotor di Tumpukan Laundry
Bayangkan saya punya keranjang laundry berisi 1000 baju. Sebagian besar baju normal (bersih atau sedikit kotor), tapi ada beberapa yang sangat kotor. Saya hendak memisahkan baju normal dengan baju kotor.
Jika kita memeriksa baju satu persatu, kita telah melakukan proses secara manual yang lama dan melelahkan.
Nah, kita bisa menggunakan cara isolation forest dengan trik cerdas berikut:
- Saya minta bantuan 10 teman (decision tree) yang akan membantu.
- Langkah Acak:
- Setiap teman mengambil satu kriteria acak (misal: “apa ada noda?”, “apa baunya menyengat?”).
- Mereka memisahkan baju berdasarkan kriteria itu.
- Isolasi Cepat = Anomali:
- Baju normal butuh banyak pertanyaan untuk mengisolasi.
- Baju sangat kotor langsung ketahuan dalam 1-2 langkah:
Contoh:- Apakah bau keringat? Ya akibatnya langsung terisolasi!
- Voting dari Semua Teman:
- Jika 8 dari 10 teman bilang baju X gampang diisolasi, artinya baju ini adalah baju kotor (anomali).
b. Tentang library(solitude)
Berikut adalah fitur dari library(solitude):
- Mudah Digunakan: Hanya perlu memanggil fungsi
isolationForest$new()danfit(). - Unsupervised: Tidak membutuhkan label anomali dalam data.
- Cepat: Optimized untuk dataset besar.
- Output: Menghasilkan anomaly score (skor 0-1, semakin tinggi semakin anomali).
Kelebihan dari isolation forest:
- Efisien untuk data high-dimensional.
- Tidak memerlukan asumsi distribusi data.
- Cepat karena kompleksitas waktu linear.
Kekurangan dari isolation forest:
- Tidak seakurat metode supervised jika label anomali tersedia.
- Threshold (
anomaly_score) perlu diatur manual.
Tips dan trik membuat model ini:
- Normalisasi Data: Pastikan fitur numerik di-scale (misal: pakai
scale()). - Tuning Parameter:
num_trees: Semakin besar, semakin stabil (tapi lebih lambat).sample_size: Sesuaikan dengan ukuran dataset.
- Threshold: Evaluasi dengan business case (misal: ambil 5% skor tertinggi sebagai anomali).
c. Isolation Forest dari Data Survey
Sekarang kita akan buat modelnya untuk mengukur apakah responden anomali atau tidak dengan threshold tertentu.
Penentuan threshold bisa dilakukan melalui tiga pendekatan:
- Default (> 0.5) untuk eksplorasi awal.
- Persentil 95% atau mean + 2SD untuk analisis lebih akurat.
- Validasi manual untuk memastikan threshold sesuai kebutuhan.
Untuk kasus ini, saya akan mendefinisikan threshold sebesar 90% percentile.
library(solitude)
# Gabungkan fitur untuk anomaly detection
features =
data %>%
select(q1, q2, q3, q4, q5, waktu_jawab) %>%
scale() # Normalisasi
# Train Isolation Forest
model = isolationForest$new()
model$fit(features)
INFO [07:24:03.490] dataset has duplicated rows
INFO [07:24:03.528] Building Isolation Forest ...
INFO [07:24:04.317] done
INFO [07:24:04.318] Computing depth of terminal nodes ...
INFO [07:24:05.212] done
INFO [07:24:05.234] Completed growing isolation forest
# Prediksi anomali
anomaly_scores = model$predict(features)
# Penentuan Batas 95%
batas = quantile(anomaly_scores$anomaly_score,.90)
anomaly_scores =
anomaly_scores %>%
mutate(is_anomaly = ifelse(anomaly_score > batas, TRUE, FALSE)) # Threshold
data$is_anomaly = anomaly_scores$is_anomaly
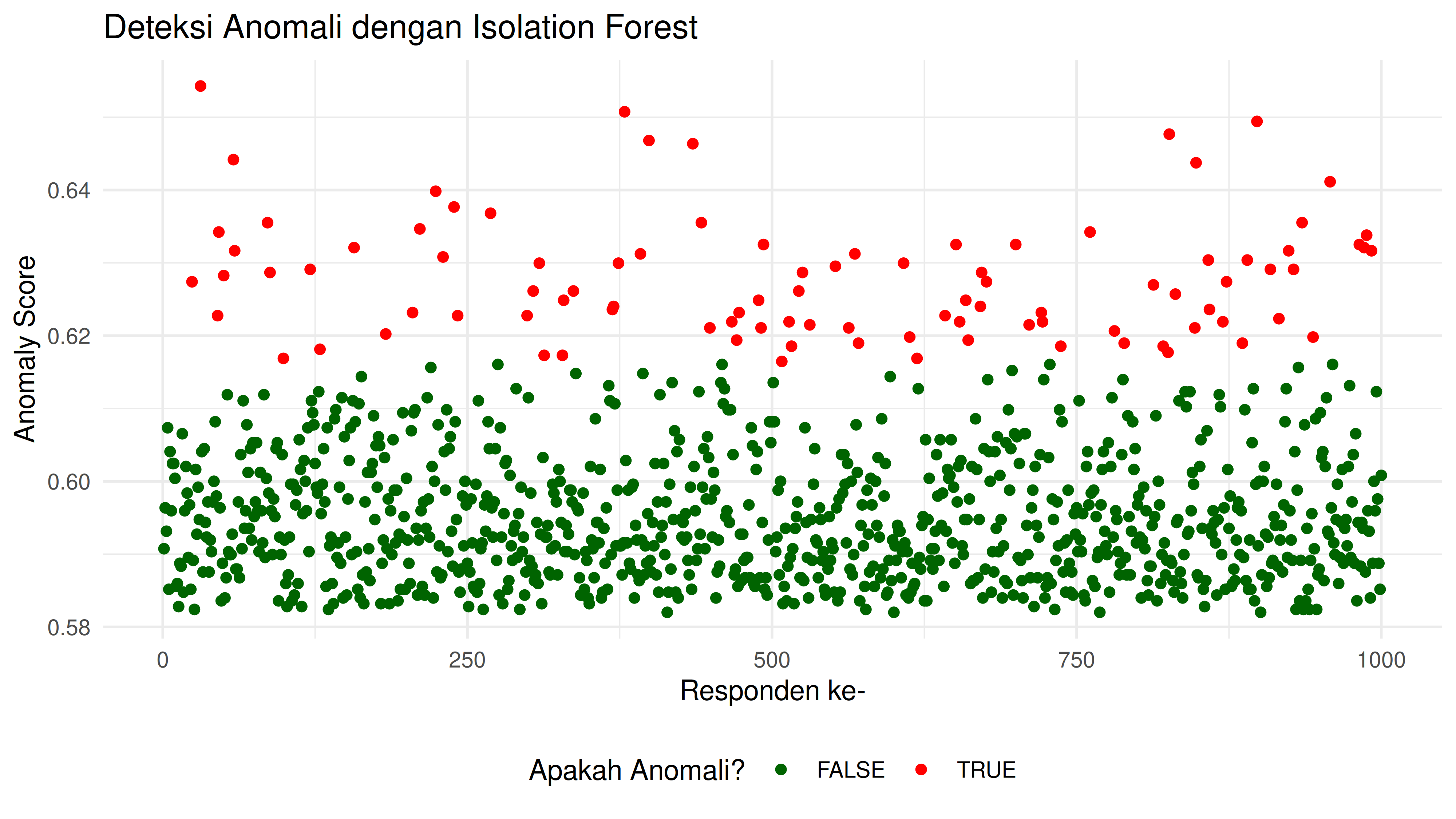
Dari model ini, kita bisa mendapatkan ada 97 orang yang terindikasi “fraud”.
Perbandingan dengan Metode Statistik
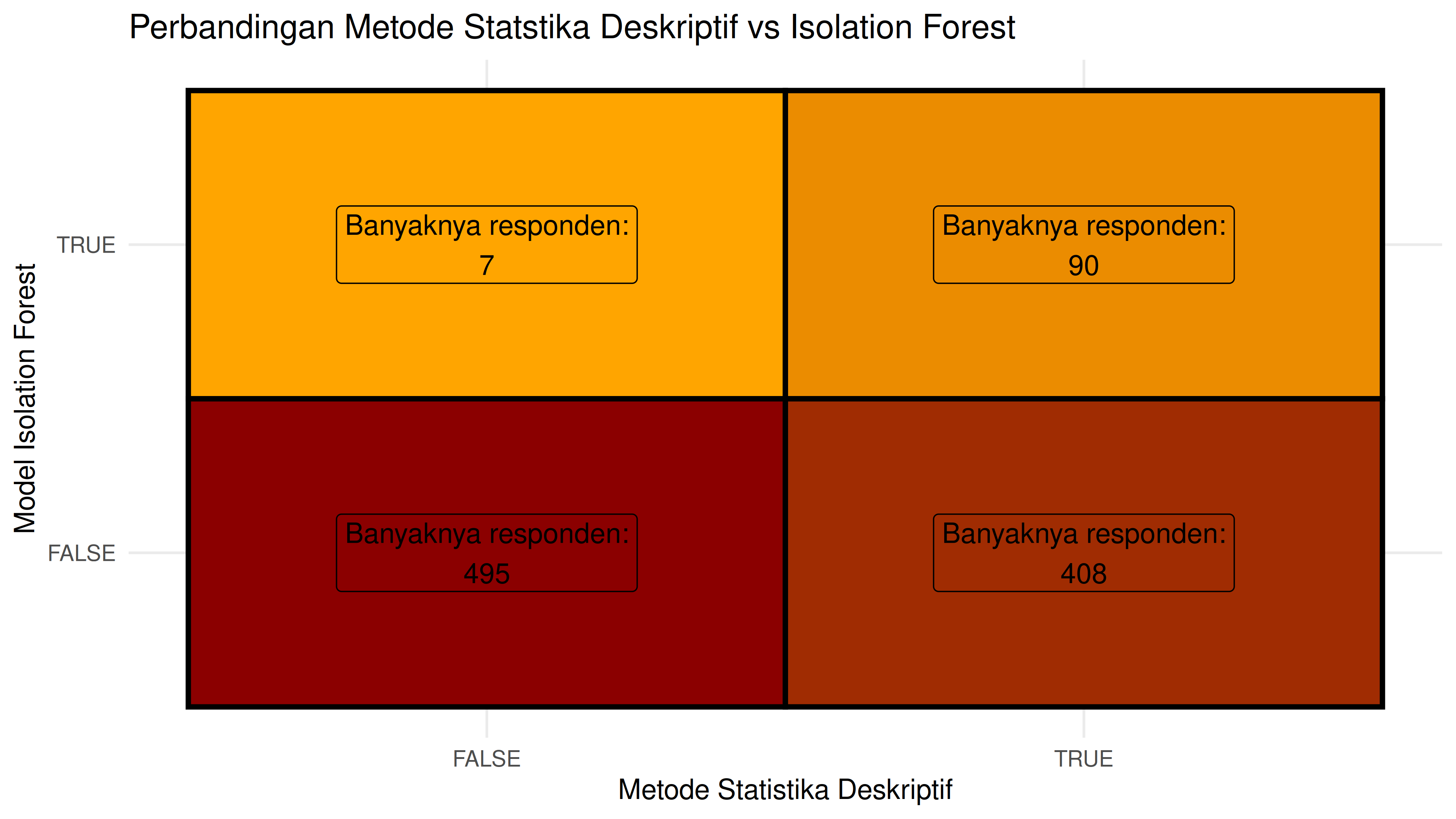
Kita dapatkan:
- 90 orang responden fraud terdeteksi oleh kedua metode.
- 408 orang responden fraud terdeteksi secara manual only.
- 7 orang responden fraud terdeteksi dari model only.
Mari kita lihat 7 orang yang terdeteksi dari model only:
data %>%
filter(is_fraud == F) %>% filter(is_anomaly == T) %>%
select(id,usia,gender,q1,q2,q3,q4,q5,waktu_jawab) %>%
knitr::kable()
| id | usia | gender | q1 | q2 | q3 | q4 | q5 | waktu_jawab |
|---|---|---|---|---|---|---|---|---|
| 45 | 50 | L | 4 | 3 | 5 | 5 | 3 | 34 |
| 304 | 34 | L | 1 | 4 | 2 | 1 | 2 | 35 |
| 449 | 56 | P | 5 | 2 | 4 | 4 | 2 | 39 |
| 514 | 46 | L | 1 | 4 | 4 | 1 | 3 | 38 |
| 721 | 59 | P | 3 | 1 | 2 | 4 | 2 | 35 |
| 781 | 18 | P | 5 | 5 | 3 | 3 | 4 | 114 |
| 909 | 33 | P | 1 | 2 | 1 | 4 | 1 | 46 |
Dari responden ini, kita bisa dapatkan kesamaan yakni berupa waktu pengisian survey yang sama-sama singkat kecuali untuk satu responden.
Kesimpulan
- Metode statistika deskriptif sangat efektif untuk pendeteksian anomali eksplisit.
- Machine Learning (Isolation Forest) bisa menangkap pola yang lebih halus jika threshold yang digunakan tepat.
- Perlu oprekan lebih lanjut untuk bisa menggabungkan kedua metode ini.
if you find this article helpful, support this blog by clicking the ads.