
Mengenal K-Prototype Clustering untuk Mengelompokkan Data Campuran (Numerik dan Kategorik)
Sebagai market researcher, saya sering menemukan kasus di mana saya harus melakukan pengelompokan konsumen berdasarkan informasi atau data yang ada. Di blog ini, saya juga sudah pernah menjelaskan bagaimana melakukan k-modes clustering, k-means clustering, hierarchical clustering, dan DBScan clustering. Sebelum lanjut membaca tulisan ini, saya sarankan agar rekan-rekan bisa membaca terlebih dahulu tulisan saya sebelumnya.
Tentu masing-masing teknik clustering tersebut memiliki kelebihan dan kekurangan tergantung dari tujuan yang dicapai dan format data yang digunakan.
Kali ini, saya hendak membahas satu teknik clustering lain yang bernama k-prototype clustering. Secara singkat, saya bisa mendefinisikan teknik clustering ini sebagai perkawinan antara k-means dan k-modes. Artinya, teknik ini sangat berguna jika dihadapkan pada data yang mengandung numerik dan kategorik di dalamnya (data campuran).
Artinya kita tidak perlu melakukan konversi seperti one hot encoding pada data kategorik!
Teknik clustering ini menggunakan fungsi jarak yang menggabungkan:
- Jarak Euclidean untuk variabel numerik.
- Jarak Hamming untuk variabel kategorik.
Sehingga penentuan cluster centers menggunakan:
- Untuk variabel numerik: menggunakan mean (seperti k-means).
- Untuk variabel kategorikal: menggunakan modus (nilai yang paling sering muncul)
Implementasi di R
Library di R untuk melakukan k-prototype clustering di R adalah
library(clustMixType), yang mengimplementasikan algoritma
berdasarkan penelitian Z. Huang (1998).
Seperti pada k-means dan k-modes, maka penentuan nilai k menjadi
hal yang paling krusial. Untuk menentukan nilai k, kita bisa
menggunakan prinsip yang sama, yakni dengan menggunakan elbow method,
silhouette method, atau gap-stat method.
Penentuan k ini saya bisa bilang sebagai “seni” karena ada dua
pertimbangan utama seperti:
- Nilai
ktidak boleh terlalu sedikit karena akan membuat cluster yang terlalu umum (heterogen). Data yang berbeda bisa dipaksa masuk ke cluster yang sama. - Nilai
ktidak boleh terlalu banyak karena akan membuat beberapa clusters sangat eksklusif sehingga hanya berisi sedikit member.
Contoh Data
Oke, sekarang saya akan mencoba membuat analisa clustering dari data berikut ini:
| ID | Usia | TingkatEkonomi | TingkatPendidikan | Gender | NilaiAkademis | NilaiBahasaInggris |
|---|---|---|---|---|---|---|
| 1 | 25 | Menengah | SMA | P | 72 | 65 |
| 2 | 32 | MenengahKeatas | Sarjana | L | 85 | 78 |
| 3 | 41 | Atas | Magister | P | 92 | 88 |
| 4 | 19 | Rendah | SMA | L | 58 | 52 |
| 5 | 28 | MenengahKeatas | Sarjana | P | 79 | 82 |
| 6 | 35 | Atas | Magister | L | 89 | 91 |
| 7 | 22 | Rendah | SMA | P | 61 | 55 |
| 8 | 45 | Atas | Doktor | L | 95 | 93 |
| 9 | 31 | MenengahKeatas | Sarjana | P | 81 | 79 |
| 10 | 26 | Menengah | Diploma | L | 68 | 62 |
Di atas adalah sampel 10 baris data dari total 265 data orang. Dari data
di atas, kita bisa melihat TingkatEkonomi, TingkatPendidikan, dan
Gender merupakan variabel kategorik sedangkan Usia,
NilaiAkademis, dan NilaiBahasaInggris termasuk variabel numerik.
Sebagai catatan, data di atas merupakan data rekaan saja ya.
Langkah pertama adalah menentukan nilai k.
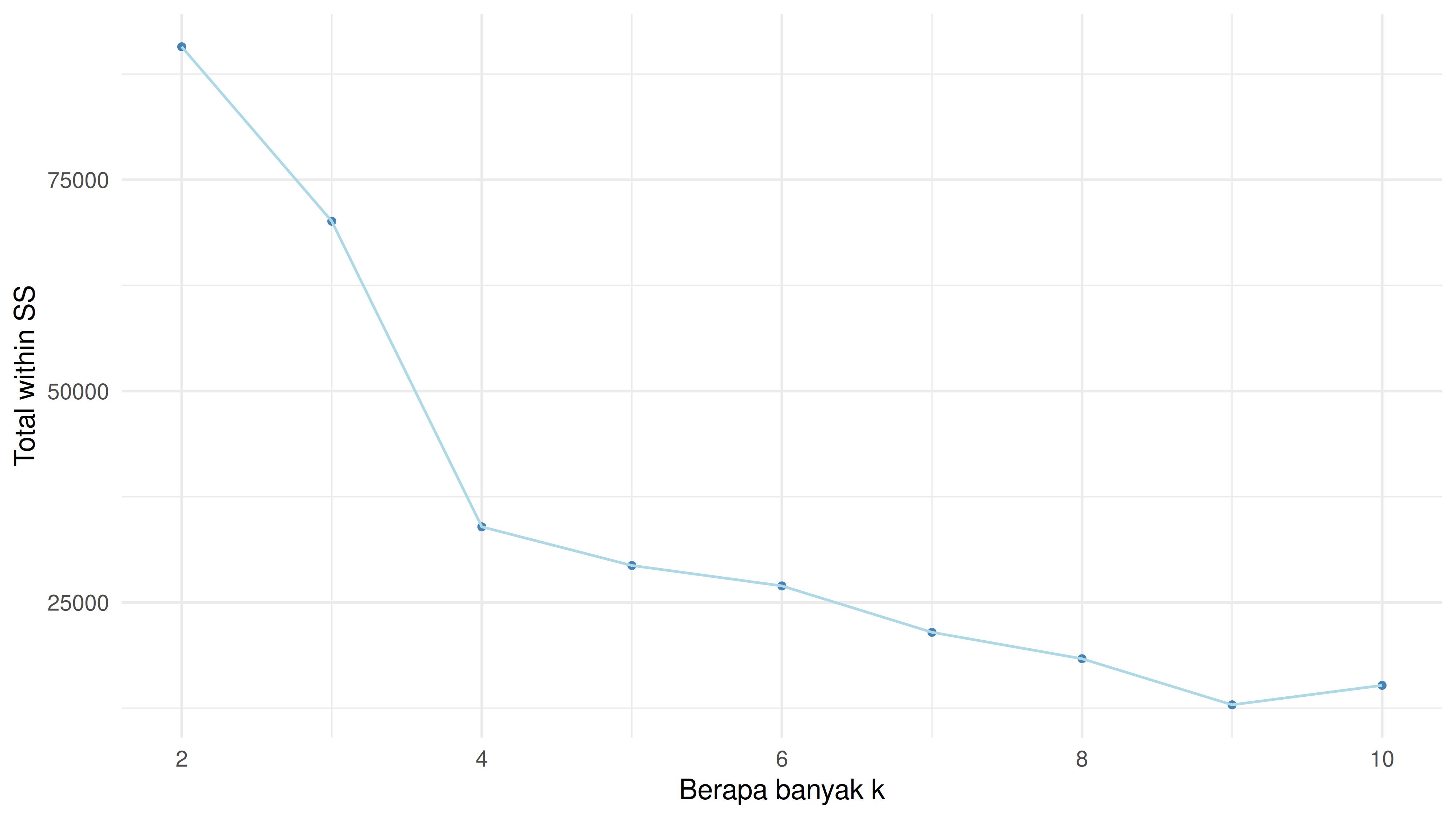
Secara visual, kita bisa melihat elbow berada pada k = 4. Mari
kita analisa 4 clusters yang terbentuk:
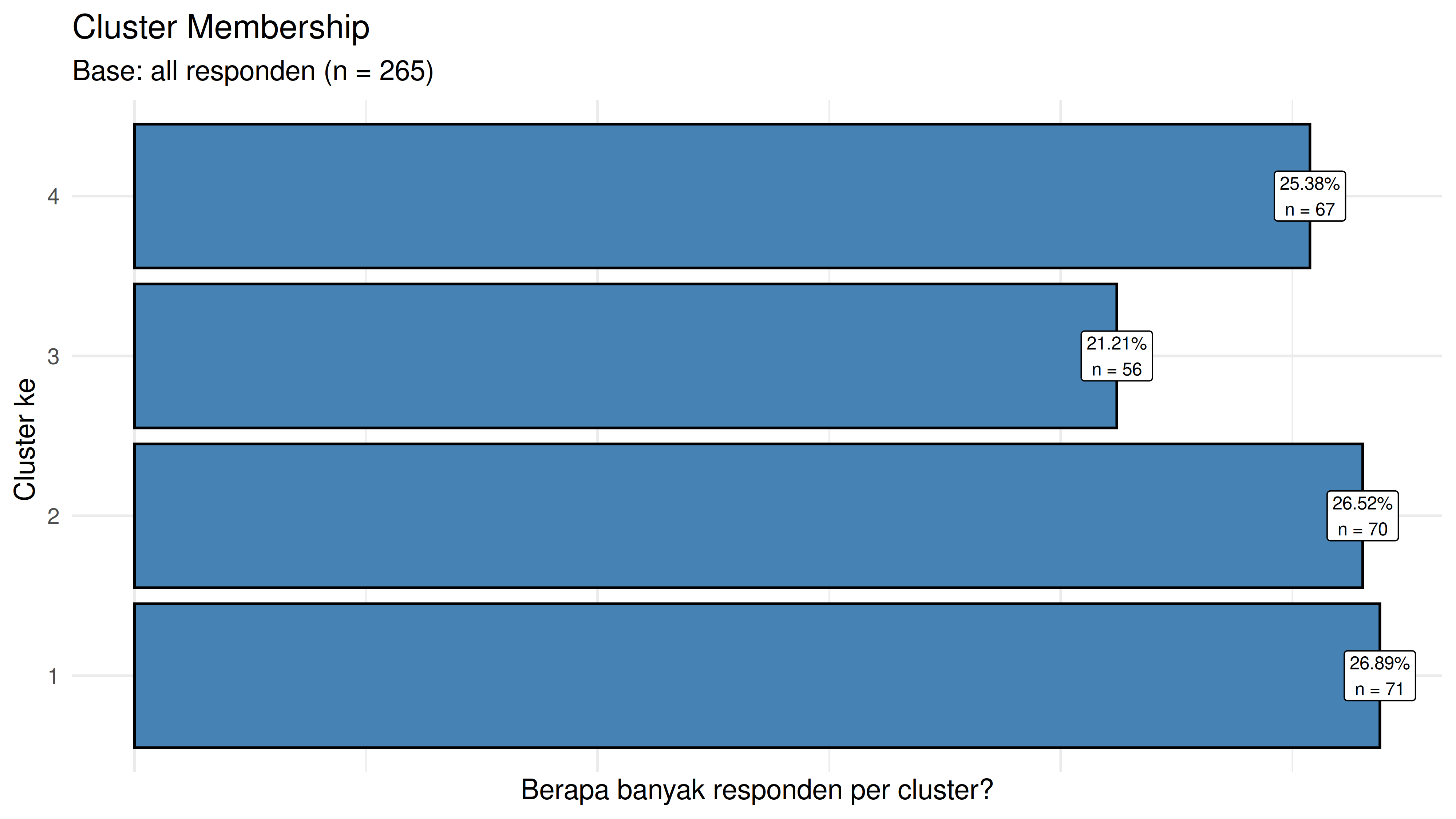
Berikut adalah clusters center yang dihasilkan:
| Usia | TingkatEkonomi | TingkatPendidikan | Gender | NilaiAkademis | NilaiBahasaInggris |
|---|---|---|---|---|---|
| 28 | Menengah | Sarjana | L | 74 | 70 |
| 40 | Atas | Magister | P | 91 | 88 |
| 24 | Rendah | SMA | P | 61 | 55 |
| 32 | MenengahKeatas | Sarjana | P | 82 | 80 |
Kita bisa melihat dengan detail profil setiap cluster yang terbentuk.
CLUSTER 1: “Generasi Muda Menengah” (71 orang)
- Usia: 28.4 tahun
- Ekonomi: Menengah
- Pendidikan: Sarjana
- Gender: Laki-laki
- Nilai Akademis: 73.7
- Nilai Bahasa Inggris: 70.0
Interpretasi: Kelompok profesional muda dengan latar belakang ekonomi menengah, berpendidikan sarjana, dengan performa akademis dan bahasa Inggris yang cukup baik.

CLUSTER 2: “Elite Senior” (70 orang)
- Usia: 39.7 tahun
- Ekonomi: Atas
- Pendidikan: Magister
- Gender: Perempuan
- Nilai Akademis: 90.5
- Nilai Bahasa Inggris: 88.3
Interpretasi: Kelompok elite dengan usia lebih matang, ekonomi atas, pendidikan tinggi (magister), dan performa akademis serta bahasa Inggris yang sangat baik.

CLUSTER 3: “Generasi Muda Terbatas” (56 orang)
- Usia: 24.1 tahun
- Ekonomi: Rendah
- Pendidikan: SMA
- Gender: Perempuan
- Nilai Akademis: 61.5
- Nilai Bahasa Inggris: 55.0
Interpretasi: Kelompok usia sangat muda dengan latar belakang ekonomi terbatas, pendidikan menengah, dan performa akademis serta bahasa Inggris yang rendah.

CLUSTER 4: “Profesional Menengah-Atas” (67 orang)
- Usia: 32.3 tahun
- Ekonomi: Menengah-Keatas
- Pendidikan: Sarjana
- Gender: Perempuan
- Nilai Akademis: 82.3
- Nilai Bahasa Inggris: 79.5
Interpretasi: Kelompok profesional dengan ekonomi menengah-keatas, pendidikan sarjana, dan performa akademis serta bahasa Inggris yang baik.

Pola pada Clusters
Dari clusters yang terbentuk, kita bisa melihat beberapa pola seperti ini:
- Pola antara usia dengan “performa” (atau nilai-nilai).
- Usia lebih tua cenderung memiliki performa yang lebih tinggi
- Usia muda cenderung memiliki performa yang bervariasi tergantung latar belakang ekonomi dan pendidikan.
- Pengaruh latar belakang ekonomi dan pendidikan.
- Responden dengan ekonomi atas dan berpendidikan tinggi cenderung memiliki performa yang lebih optimal.
- Responden dengan ekonomi rendah dan pendidikan menengah cenderung memiliki keterbatasan performa.
if you find this article helpful, support this blog by clicking the ads.