
Mengenal Latent Profile Analysis: Teknik Pengelompokan yang Lebih Manusiawi untuk Data Survey Engagement
Beberapa hari yang lalu, saya diajak berdiskusi oleh rekan dari departemen HR tentang hasil analisa survey engagement karyawan. Mereka menggunakan teknik yang disebut Latent Profile Analysis (LPA) untuk mengelompokkan karyawan berdasarkan pola respons survey.
“Kenapa nggak pakai k-means aja? Kan lebih simpel,” tanya saya penasaran.
Rekan HR itu tersenyum dan menjawab: “Karena LPA lebih ‘manusiawi’. Dia ngerti bahwa satu orang bisa punya kecenderungan ke beberapa kelompok sekaligus.”
Dan itu membuat saya penasaran. Apa sebenarnya perbedaan mendasar antara LPA dengan algoritma clustering tradisional seperti k-means? Kapan kita harus memilih yang satu daripada yang lain?
Apa Itu Latent Profile Analysis?
Latent Profile Analysis (LPA) adalah teknik pengelompokan berbasis model probabilistik yang mencari subkelompok tersembunyi (latent) dalam populasi berdasarkan pola respons pada beberapa variabel.
Bayangkan kita punya data survey engagement dari 500 karyawan dengan 10 pertanyaan. Setiap karyawan memberikan skor 1-5 untuk setiap pertanyaan. LPA akan mencari:
“Apakah ada pola respons tertentu yang muncul berulang? Apakah ada tipe-tipe karyawan yang berbeda berdasarkan cara mereka merespons survey?”
Sederhananya, jika kita memiliki data mentah yang terlihat berantakan, LPA membantu kita menemukan “profil” atau tipe orang yang memiliki pola jawaban serupa. LPA berasumsi bahwa individu-individu dalam satu kelompok memiliki parameter distribusi (seperti rata-rata dan varians) yang mirip.
Analogi Sederhana
Jika k-means seperti mengelompokkan buah berdasarkan berat dan diameter (fisik semata), maka LPA seperti mengelompokkan buah berdasarkan rasa, tekstur, dan aroma (karakteristik intrinsik yang lebih kompleks).
Perbedaan Fundamental: LPA vs K-Means
Mari kita lihat perbedaan mendasar antara kedua teknik ini:
| Aspek | Latent Profile Analysis (LPA) | K-Means Clustering |
|---|---|---|
| Dasar Teori | Model probabilistik (mixture model) | Algoritma optimisasi jarak |
| Keanggotaan | Probabilistik (0-1 probability) | Deterministik (0 atau 1) |
| Asumsi | Asumsi distribusi (biasanya normal) | Tidak ada asumsi distribusi |
| Penentuan Jumlah Kluster | Kriteria statistik (AIC, BIC, LRT) | Heuristik (elbow method) |
| Penanganan Noise | Robust (melalui model probabilistik) | Sensitif terhadap outlier |
| Missing Data | Bisa ditangani langsung | Harus diimputasi dulu |
Kelebihan LPA dibanding K-Means:
- Fit Indices: LPA menyediakan metrik seperti AIC, BIC, dan Entropy untuk menentukan jumlah kelompok yang paling optimal secara statistik, bukan sekadar intuisi visual (seperti metode Elbow pada K-Means).
- Penanganan Error: Karena berbasis model, LPA memperhitungkan kesalahan pengukuran.
Keanggotaan Probabilistik: Kekuatan Utama LPA
Inilah yang membuat LPA “lebih manusiawi”. Dalam LPA, satu responden bisa memiliki:
Responden #101:
- 70% probability masuk Profil "Highly Engaged"
- 25% probability masuk Profil "Moderately Engaged"
- 5% probability masuk Profil "Disengaged"
Sedangkan di k-means:
Responden #101: Cluster 1 (100%)
LPA mengakui ambiguitas, maksudnya manusia bisa memiliki karakteristik campuran dari beberapa tipe.
Apa Perbedaan LPA dengan Bayesian Clustering?
Jika rekan-rekan pernah membaca tulisan saya sebelumnya terkait Bayesian Clustering, salah satu output-nya juga memberikan fleksibilitas atau ambiguitas untuk masing-masing subject bisa masuk ke satu atau lebih cluster. Selain itu, parameter BIC yang disebutkan pada LPA memiliki kepanjangan: Bayesian Information Criterion. Maka pertanyaannya adalah:
“Apakah LPA termasuk ke dalam metode Bayesian?”
Oke, saya akan bahas secara sederhana sebagai berikut:
Perbedaan LPA dengan Bayesian Clustering
Bayesian Clustering bukanlah satu algoritma spesifik, melainkan kerangka kerja (framework) dalam melakukan clustering. Perbedaan utamanya terletak pada bagaimana parameter diestimasi.
- Estimasi Parameter
- LPA: Biasanya menggunakan metode Maximum Likelihood (ML) dengan algoritma Expectation-Maximization (EM). Tujuannya adalah mencari satu nilai parameter yang paling mungkin menghasilkan data yang diamati.
- Bayesian Clustering: Menggunakan distribusi prior dan data untuk menghasilkan distribusi posterior. Ia tidak hanya menghasilkan satu titik estimasi, melainkan seluruh distribusi probabilitas untuk parameter tersebut.
- Penentuan Jumlah Cluster
- Dalam LPA, kita biasanya menjalankan model berkali-kali (model dengan 2 profil, 3 profil, dst) lalu membandingkan nilai BIC/AIC.
- Dalam Bayesian Clustering (terutama yang menggunakan Dirichlet Process), model bisa menentukan jumlah cluster secara otomatis dari data tanpa kita harus menentukan “K” di awal.
- Ketidakpastian (Uncertainty)
- Metode Bayesian jauh lebih unggul dalam mengukur ketidakpastian, terutama pada sampel kecil atau model yang sangat kompleks. kita bisa mengetahui seberapa yakin model terhadap struktur kelompok yang terbentuk.
Keputusan untuk memilih antara Latent Profile Analysis (LPA) konvensional (berbasis Frequentist/Maximum Likelihood) dan Bayesian Clustering biasanya bergantung pada kompleksitas model, ukuran sampel, dan kebutuhan Anda akan informasi mengenai ketidakpastian (uncertainty).
Gunakan Latent Profile Analysis (LPA) Jika…
LPA standar adalah pilihan utama untuk efisiensi dan standarisasi dalam riset.
- Sampel Besar: Jika Anda memiliki ribuan observasi, LPA konvensional jauh lebih cepat secara komputasi dibandingkan Bayesian yang memerlukan iterasi MCMC (Markov Chain Monte Carlo).
- Kebutuhan Fit Indices Standar: Anda membutuhkan metrik perbandingan model yang umum diterima seperti BIC (Bayesian Information Criterion), AIC, dan Entropy untuk menentukan jumlah profil secara objektif.
- Studi Eksploratori Sederhana: Jika tujuannya hanya ingin mengelompokkan orang berdasarkan pola jawaban tanpa asumsi awal yang kuat, LPA adalah benchmark industri yang sangat solid.
Gunakan Bayesian Clustering Jika…
Bayesian clustering memberikan fleksibilitas lebih besar ketika model statistik standar mulai mencapai batas kemampuannya.
- Sampel Kecil: Dalam sampel kecil, estimasi Maximum Likelihood (LPA standar) sering kali gagal konvergen atau memberikan estimasi yang bias. Bayesian dengan priors yang tepat dapat menstabilkan model.
- Model Sangat Kompleks: Jika Anda ingin menggabungkan pengelompokan dengan model lain (misalnya: Multilevel Modeling atau variabel yang memiliki hubungan non-linear), framework Bayesian jauh lebih fleksibel.
- Informasi Prior Tersedia: Jika Anda memiliki pengetahuan dari studi sebelumnya tentang bagaimana profil tersebut seharusnya terbentuk, Anda bisa memasukkan informasi tersebut sebagai prior untuk mempertajam hasil.
- Ketidakpastian yang “Jujur”: Meskipun LPA memberikan soft assignment (probabilitas), Bayesian memberikan Posterior Distribution. Artinya, Anda tidak hanya tahu probabilitas subjek X masuk ke Profil 1 adalah 0.8, tapi Anda juga tahu rentang keyakinan (credible interval) dari probabilitas tersebut.
- Jumlah Kelompok Tidak Diketahui: Jika Anda menggunakan Bayesian Non-parametric (seperti Dirichlet Process), model bisa “belajar” menentukan jumlah cluster yang optimal secara otomatis tanpa Anda harus mencoba model K=2, K=3, dst., satu per satu.
Apa itu BIC (Bayesian Information Criterion)?
BIC adalah kriteria untuk seleksi model. Fungsinya adalah untuk menyeimbangkan antara seberapa fit model terhadap data (akurasi) dengan seberapa sederhana model tersebut (parsimoni).
Rumus dasarnya adalah:
Di mana:
: adalah likelihood. Semakin besar nilai ini, semakin buruk modelnya (maka diberi tanda negatif agar angka kecil berarti lebih baik).
: adalah penalti.
adalah jumlah parameter dan
adalah jumlah sampel.
Jika kita terus menambah jumlah kelompok (profil) dalam LPA, model pasti akan semakin “fit” dengan data. Namun, model yang terlalu kompleks akan menjadi overfit. BIC memberikan hukuman (penalti) yang berat pada penambahan parameter, terutama jika sampel Anda besar. Model dengan nilai BIC terkecil dianggap sebagai model yang paling seimbang.
Kenapa Namanya “Bayesian”?
Meskipun sering digunakan dalam metode non-Bayesian, BIC disebut “Bayesian” karena diturunkan dari Bayes Factor. Secara teknis, BIC dikembangkan oleh Gideon Schwarz (1978) sebagai pendekatan untuk menghitung probabilitas posterior dari sebuah model. Jika kita mengasumsikan bahwa semua model yang kita uji memiliki probabilitas awal (prior) yang sama, maka memilih model dengan BIC terkecil secara matematis setara dengan memilih model dengan probabilitas posterior tertinggi.
Jadi, istilah “Bayesian” di sini merujuk pada akar matematisnya, bukan berarti setiap kali Anda menggunakan BIC, Anda sedang melakukan komputasi Bayesian penuh.
Jadi, saat kita melihat BIC di output R, sebenarnya kita sedang menggunakan “alat deteksi” yang berbasis logika Bayesian untuk mengevaluasi model yang dibangun dengan cara frequentist.
Apakah LPA Termasuk Pendekatan Bayesian?
Jawabannya: Umumnya Tidak. Secara tradisional, LPA yang dilakukan di R menggunakan pendekatan Frequentist (Maximum Likelihood). Selain itu pada LPA standar tidak ada prior distribution yang dilibatkan.
Studi Kasus: Data Survey Engagement Karyawan
Mari kita buat simulasi data survey engagement. Katakanlah kita punya
9 variabel yang ditanyakan pada survey engagement: yakni
.
Masing-masing variabel mewakili aspek-aspek yang mempengaruhi
engagement.
Responden akan memberikan jawaban berupa skala likert 1 (sangat tidak setuju) sampai 5 (sangat setuju). Data simulasi yang akan saya buat adalah data yang sudah ditransformasi dari data tipe ordinal ke numerik dengan cara metode suksesif interval.
Membuat Data Dummy di R
Saya akan buat data survey sebanyak 500 baris sebagai berikut:
=== SUMMARY DATA SURVEY ENGAGEMENT ===
Jumlah responden: 500
Jumlah variabel: 9
Sampel data
x1 x2 x3 x4 x5 x6 x7 x8 x9
1 3.02 2.47 2.71 3.32 2.51 3.63 3.69 3.10 3.81
2 3.18 1.83 2.85 3.66 2.66 3.19 3.48 4.47 4.42
3 4.08 2.11 3.85 3.51 3.16 3.19 4.19 3.22 3.56
4 3.34 2.25 2.53 3.81 2.56 2.59 3.54 3.43 3.52
5 3.36 3.51 3.01 3.73 2.86 3.52 4.00 3.66 3.54
6 4.16 2.01 4.05 3.32 2.89 3.12 4.08 3.39 3.53
7 3.53 2.54 3.05 3.55 2.96 2.94 4.17 3.14 2.76
8 2.67 2.45 2.42 3.02 2.21 2.64 4.06 3.82 2.83
9 2.96 1.82 2.77 3.74 3.31 3.08 3.78 4.05 3.47
10 3.08 2.36 3.34 3.22 2.31 2.86 4.30 3.39 3.27
Rata-rata per variabel:
x1 x2 x3 x4 x5 x6 x7 x8 x9
1 2.61 2.26 2.51 2.66 2.19 2.55 2.71 2.58 2.43
Analisis dengan Latent Profile Analysis (LPA)
Pertama-tama saya akan analisa menggunakan LPA.
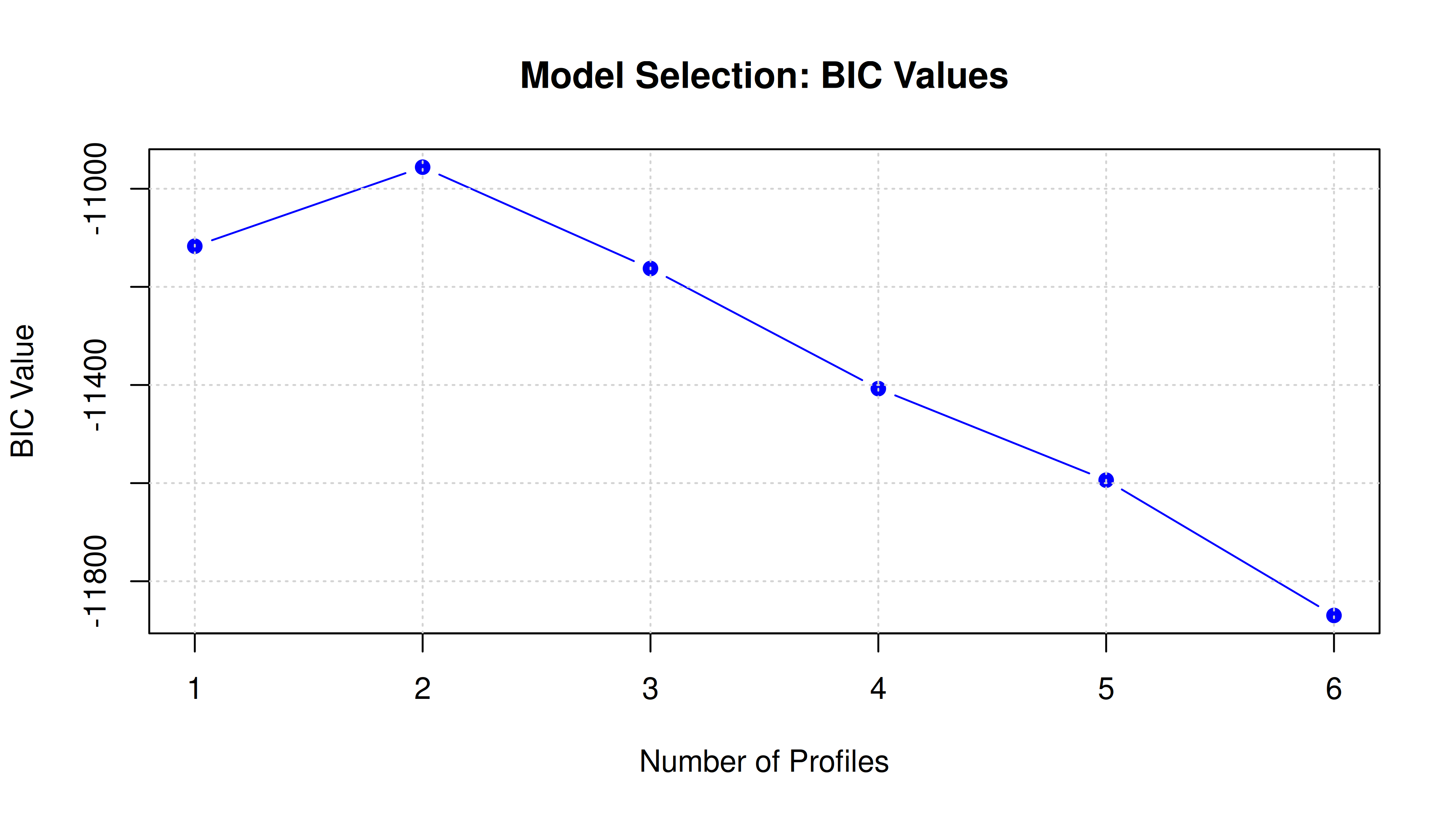
Jumlah profil optimal: 2
=== HASIL LPA ===
Jumlah profil ditemukan: 2
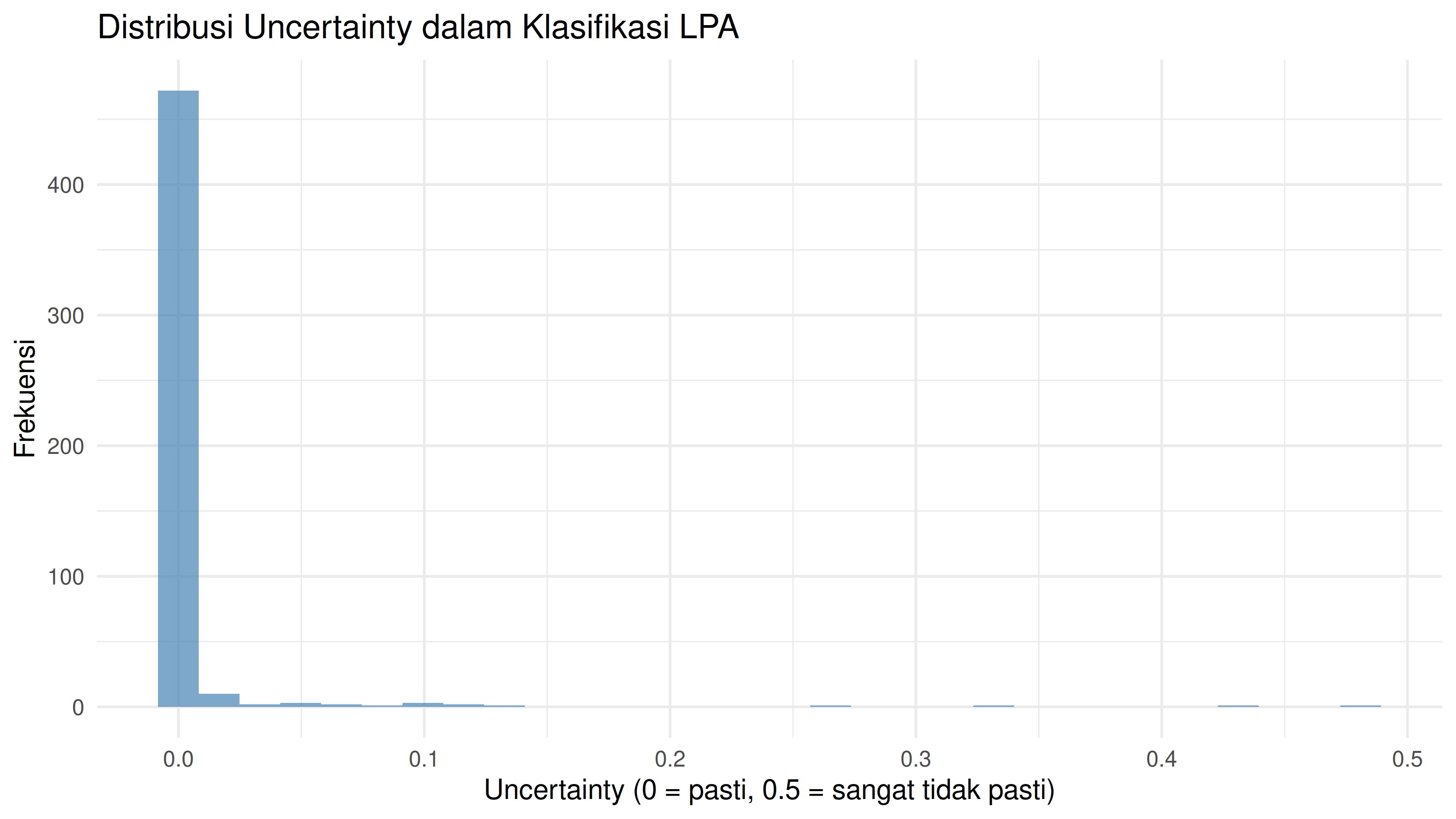
Entropy: 7.914
Rata-rata uncertainty: 0.006
# A tibble: 2 × 11
lpa_profile n x1 x2 x3 x4 x5 x6 x7 x8 x9
<dbl> <table[1d]> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 264 3.17 2.43 2.93 3.21 2.43 3.02 3.59 3.19 3.14
2 2 236 1.99 2.08 2.03 2.05 1.91 2.02 1.74 1.91 1.63
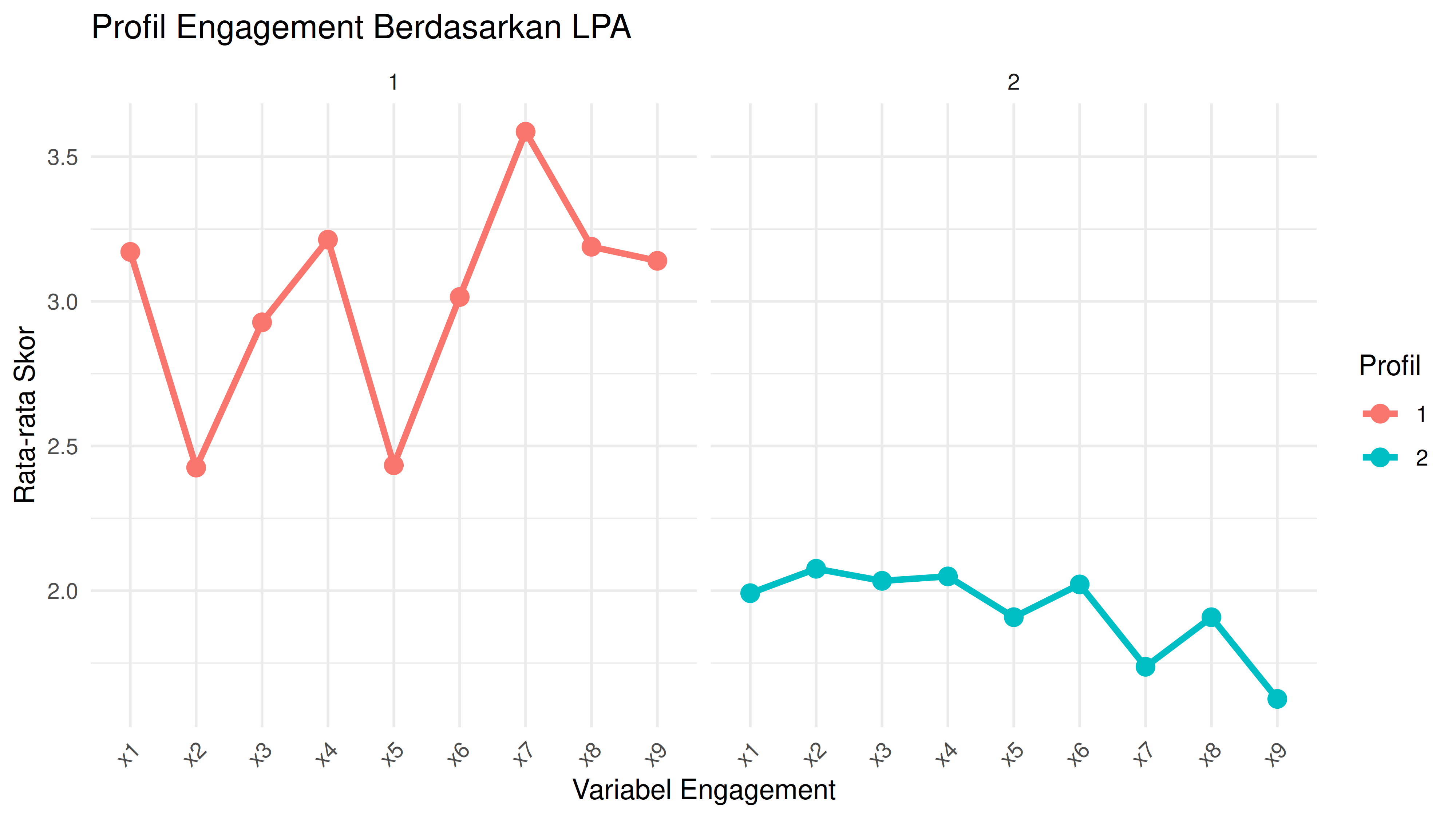
Dari hasil di atas, didapatkan ada dua buah profiles responden yang terbentuk. Masing-masing memiliki karakteristik berdasarkan jawaban 9 variabel yang berbeda-beda.
Responden di profil kedua cenderung memiliki skor yang lebih rendah di semua variabel dibandingkan responden di profil pertama. Uncertainty level per responden juga rendah, artinya setiap responden punya kecenderungan untuk berada di profilnya masing-masing (sangat jarang yang bisa masuk ke dua profil).
Analisis dengan K-Means untuk Perbandingan
Mari kita bandingkan dengan k-means sebagai perbandingan:
=== PERBANDINGAN LPA vs K-MEANS ===
KMeans
LPA 1 2
1 256 8
2 0 236
K-means juga menghasilkan dua buah clusters. Saat saya bandingkan hasilnya, kedua analisa ini memberikan hasil yang hampir mirip.
Hanya ada 8 orang responden yang berbeda hasil pengelompokkan.
Epilog
Latent Profile Analysis bukan sekadar “versi fancy” dari k-means. Ini adalah pendekatan yang fundamentally berbeda dengan filosofi berbeda:
- K-Means: “Setiap orang pasti masuk satu kelompok”
- LPA: “Setiap orang punya kecenderungan ke beberapa kelompok dengan tingkat keyakinan berbeda”
Pilihan antara LPA dan k-means tergantung pada:
- Tujuan analisis (eksplorasi vs decision-making).
- Sifat data (lengkap vs ada missing values).
- Kebutuhan interpretasi (sederhana vs nuanced).
- Audience (teknis vs non-teknis).
Seperti kata rekan HR saya:
“LPA itu seperti punya teman yang ngerti nuansa. K-means itu seperti teman yang hitam-putih.”
Kadang kita butuh yang hitam-putih. Tapi seringkali, dunia (dan data manusia) berwarna abu-abu.
if you find this article helpful, support this blog by clicking the ads.