
Mengenal Data dan Pengelompokannya
Mungkin istilah data menjadi sangat populer belakangan ini. Tapi, sebenarnya apa sih data itu? Salah satu definisi yang paling sering saya gunakan adalah:
Data adalah representasi faktual dari suatu observasi.
Data itu sendiri bisa dikelompokkan sesuai dengan tipe atau karakteristiknya. Kali ini saya akan coba membahas 3 pengelompokkan data sesuai dengan cara kita berinteraksi dengan data.
Pengelompokan Pertama
Secara statistika, kita bisa mengelompokan data berdasarkan tipenya:
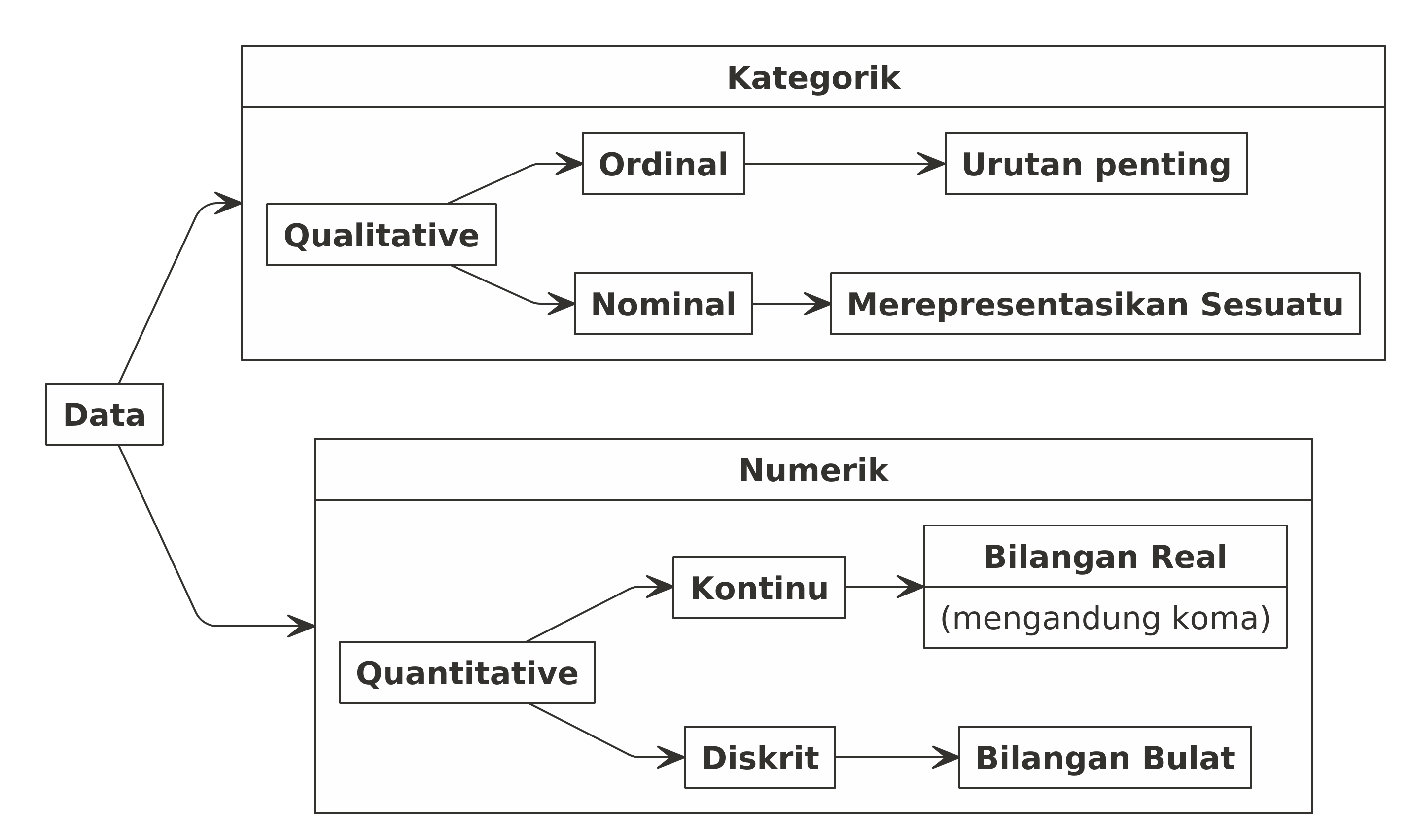
- Data kualitatif: adalah data yang tidak bisa dilakukan operasi aritmatika (penjumlahan, pengurangan, pembagian, dan perkalian). Data seperti ini bisa juga disebut sebagai data kategorik.
- Nominal; Representasi dari sesuatu. Contoh: data seperti
gender. Misalkan angka1saya tulis sebagai representasi daripriadan2sebagaiwanita. - Ordinal; Urutan dari data menjadi penting. Contoh: skala
likert, misalkan angka
1 - 6sebagai representasi dari tingkat kesukaan atau kesetujuan (sangat suka sampai sangat tidak suka).
- Data kuantitatif: adalah data yang bisa dilakukan operasi aritmatika (penjumlahan, pengurangan, pembagian, dan perkalian). Data seperti ini, kita akan sebut sebagai data numerik.
- Diskrit; bilangan bulat (integer). Contoh: banyaknya anak, banyaknya karyawan, dll.
- Kontinu; bilangan real (mengandung koma). Contoh: tinggi badan, berat badan, dll.
Apa sih gunanya kita mengetahui suatu data termasuk ke dalam kualitatif atau kuantitatif?
Dengan mengetahui tipe data yang kita miliki, kita bisa dengan lebih baik memahami dan memilih analisa yang tepat bagi data tersebut.
Contoh: Suatu waktu rekan saya pernah berujar bahwa: rata-rata peserta
webinar hari ini adalah laki-laki.
Percaya atau tidak, sebenarnya pernyataan teman saya tersebut adalah pernyataan yang salah.
Kok bisa?
Data berupa gender termasuk ke dalam data kualitatif yakni nominal.
Ingat kembali bahwa data bentuk kualitatif tidak bisa kita lakukan
operasi aritmatika! Sedangkan dalam menghitung rata-rata, kita
melakukan penambahan dan pembagian.
Masih belum paham? Oke, saya berikan ilustrasi yah. Misalkan dalam
suatu webinar ada 7 orang laki-laki dan 4 orang perempuan. Jika saya
menuliskan 1 untuk laki-laki dan 2 untuk perempuan, maka kalau saya
(paksakan) untuk menghitung rata-ratanya:
Didapatkan rata-rata sebesar 1.36. Jika saya kembalikan ke data
aslinya dimana 1 untuk laki-laki dan 2 untuk perempuan, lalu apa
arti dari nilai 1.36?
Apakah laki-laki yang agak ke-perempuan-an atau perempuan yang terlalu ke-laki-laki-an?
Oleh karena itu menghitung rata-rata dari data kualitatif tidak akan ada artinya. Pun hal yang sama dengan menghitung rata-rata dari skala likert. Hasil yang berupa angka yang mengandung koma tidak bisa diinterpretasikan secara langsung.
Oleh karena itu, data kualitatif akan lebih baik jika dihitung modusnya. Istilah sehari-harinya adalah menghitung siapa yang menjadi mayoritas dari data tersebut.
Jadi, yang benar adalah mayoritas peserta webinar adalah laki-laki.
Pengelompokan Kedua
Berikutnya adalah pengelompokan data berdasarkan sumbernya.
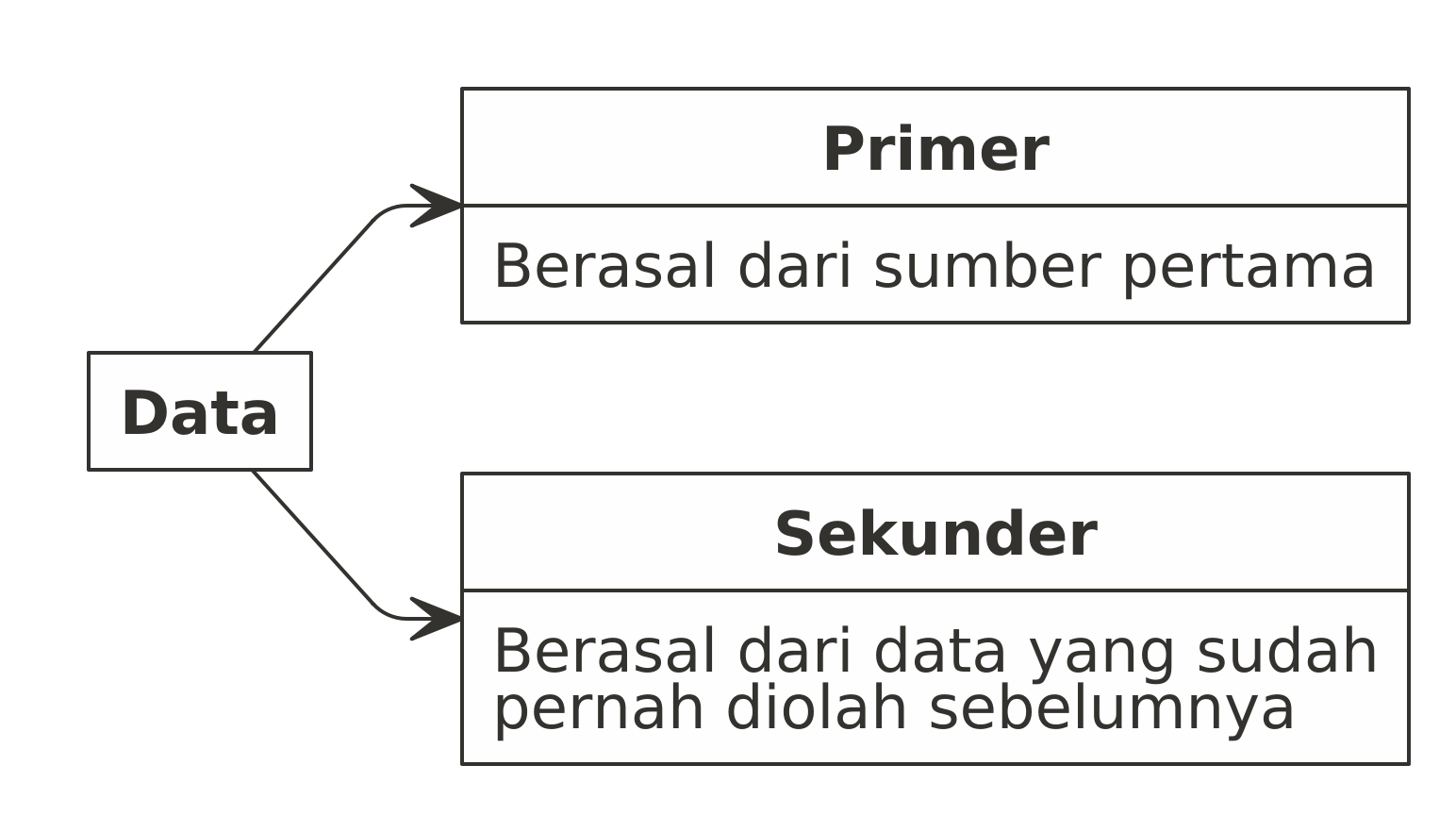
Data primer adalah data yang berasal dari sumber pertama. Sebagai contoh adalah data yang kita himpun sendiri dari hasil interview menggunakan quesioner (survey), data yang kita ambil dari mesin atau data hasil web scrape.
Data sekunder adalah data yang berasal dari sumber data lain yang sudah pernah diolah (atau minimal sudah dibersihkan - pre-processing). Contohnya adalah data kependudukan hasil sensus BPS, laporan absensi karyawan, atau data Covid-19 yang tersedia di website resmi pemerintah.
Pertanyaannya: Kapan kita menggunakan data primer? Kapan kita menggunakan data sekunder?
Mungkin pertanyaan ini simpel tapi percayalah setiap kali saya memberikan training basic statistics hanya sedikit sekali trainee yang bisa menjawabnya.
Lalu apa jawabannya?
Kita akan menggunakan data primer saat data sekunder tidak ada!
Nah lho!? Kok gitu?
Sejujurnya mencari data primer itu relatif sulit. Setidaknya kita membutuhkan waktu, tenaga, dan biaya untuk mencari data langsung dari sumbernya. Contoh, saya ingin mencari tahu berapa banyak orang yang teridentifikasi COVID-19 di Bekasi. Alih-alih saya datang ke semua RS yang ada di Bekasi, saya cukup cek saja website Pikobar Jawa Barat.
Jadi, jika data sekundernya sudah tersedia kita bisa
mempertimbangkan untuk memakai data tersebut daripada mengambil data
primer. TAPI jika ternyata karakteristik data yang kita mau cari
tersebut sangat dinamis dan cepat berubah ATAU ada perbedaan
kondisi, situasi atau limitasi maka kita harus mempertimbangkan
untuk mencari data primer dan tidak menggunakan data sekunder.
Keputusan ada di tangan kita sebagai peneliti yah!
Pengelompokan Ketiga
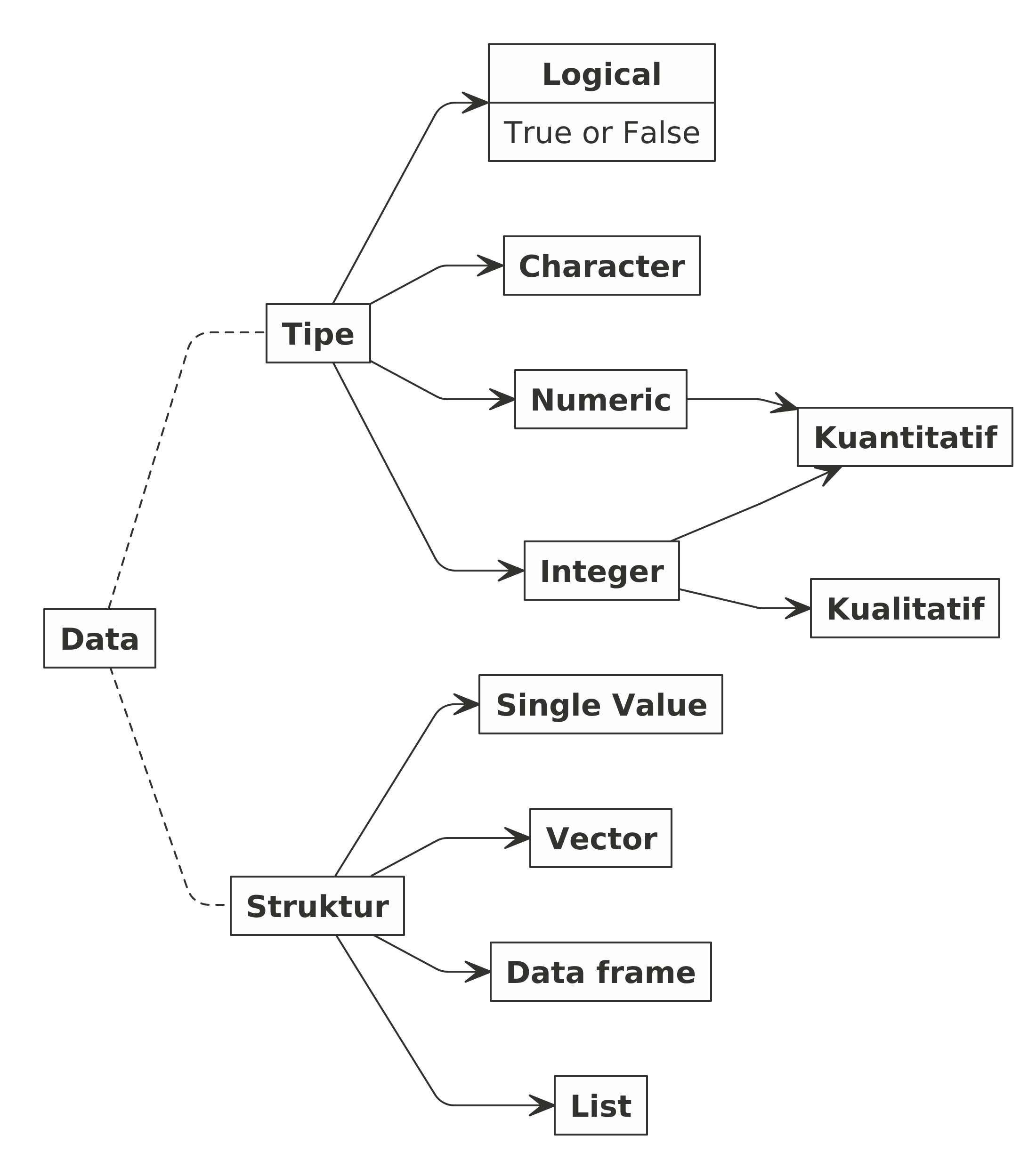
Di dalam dunia data science (setidaknya saat kita bekerja dengan R), ada beberapa tipe data yang sering digunakan. Secara hierarki, bisa diurutkan sebagai berikut:
Saya coba jelaskan satu persatu yah:
character: merupakan tipe data berupa karakter ataustring. Semua data bisa dilihat sebagaicharacter. Oleh karena itu, secara hierarki tipe data ini ditempatkan di urutan paling atas. Namun, data tipe ini tidak bisa dilakukan operasi aritmatika yah.numeric: merupakan tipe data angka berupa bilangan real. Kalau saya boleh bilang, tipe data ini mirip dengan data kuantitatif kontinu.integer: merupakan tipe data angka berupa bilangan bulat. Sekilas mirip dengan tipe data diskrit pada data kuantitatif. Namun di beberapa kondisi, tipe data ini bisa dijadikan data kategorik sehingga kita bisa sebut tipenya menjadifactor.logical: merupakan tipe data boolean. Hanya berisiTRUEatauFALSE. Tipe data ini sangat berguna saat kita melakukan if conditional, looping, atau membuat regex (reguler expression).
Selain tipe data, ada juga namanya struktur data, yakni dalam bentuk apa data itu berwujud, yakni:
- Single value; satu objek yang berisi satu value saja.
- Vector; kumpulan dari beberapa single value(s) yang menjadi satu objek. Bayangkan sebagai satu buah kolom di file Ms. Excel.
- Data frame atau tibble; merupakan kumpulan dari beberapa vectors yang memiliki ukuran sama. Bayangkan sebagai satu tabel di Ms. Excel yang banyaknya baris di setiap kolom sama.
- List; merupakan bentuk struktur data yang sangat kompleks. Berisi
multiple data dengan struktur bermacam-macam. Biasanya data dengan
format
.jsonmemiliki struktur berupa list.
Apa gunanya kita mengetahui jenis dan struktur data di R?
Beberapa algoritma yang tersedia di library mengharuskan kita memiliki input yang ter-standar, baik dari segi jenis dan strukturnya.
Dengan mengetahui jenis dan struktur data, kita bisa lebih mudah bekerja dengan algoritma yang ada di library.
Contoh: algoritma analisa simple linear regression lm() memerlukan
input berupa data.frame() dengan masing-masing variables yang ada di
dalamnya berjenis numeric.
Dukung selalu blog ini agar bisa terus bertumbuh dengan cara klik iklan selepas Kamu membaca setiap tulisan yang ada yah.