
TUTORIAL WEB SCRAPING di R dengan rvest dan chromote
Pada tulisan sebelumnya
saya telah memberikan penjelasan mengenai bagaimana web scrape
dilakukan dengan cara parsing html dengan ralger dan membaca .json
dari API web dengan jsonlite.
Sekarang saya akan memberikan tutorial web scraping dengan
library(rvest) dan library(chromote).
Kedua libraries ini adalah andalan saya untuk melakukan web scraping ke situs yang relatif sulit di-scrape. Kenapa?
rvest- Performanya cepat.
- Bisa diubah user agent-nya ke browser lainnya.
chromotebertindak sebagai mimicking Google Chrome.
Tutorial library(rvest)
Cara kerja library(rvest) adalah dengan parsing html. Mirip seperti
library(ralger),
yakni menargetkan css object dalam suatu page website.
Secara default, baik rvest dan ralger menggunakan libcurl atau
r-curl sebagai user agent.
Cara mengeceknya:
library(rvest)
se <- html_session( "https://httpbin.org/user-agent" )
se$response$request$options$useragent
## [1] "libcurl/7.68.0 r-curl/4.3 httr/1.4.2"
Kadangkala beberapa situs mem-block user agent ini. Oleh karena itu, kita perlu mengubahnya terlebih dahulu.
Pertama-tama, saya akan berikan contoh cara web scraping dengan
rvest tanpa mengubah user agent.
Web scraping dengan User Agent Default
Contoh I: GOFOOD
Misalkan saya hendak web scraping halaman depan dari Gofood berikut ini:
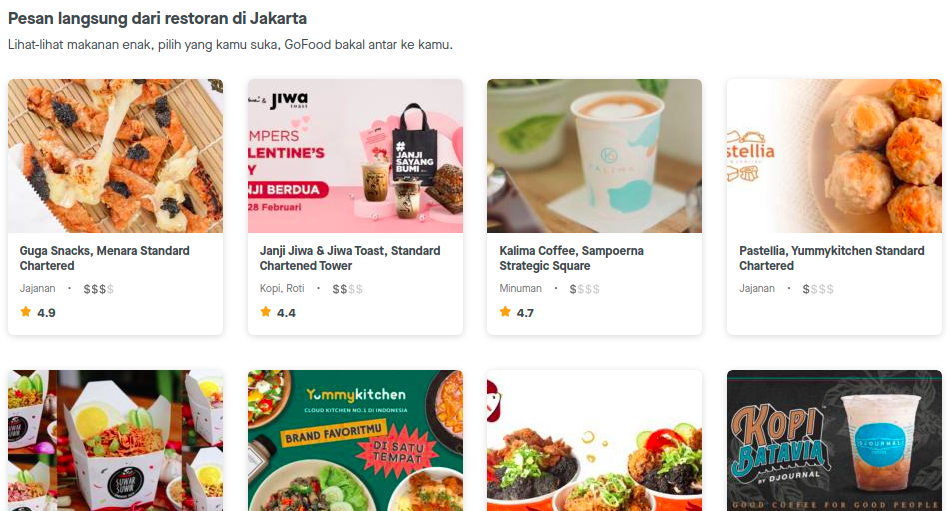
Saya akan mengambil informasi nama restoran dan jenis restorannya.
Menggunakan css selector, saya mendapatkan css object yang akan saya
ambil sebagai berikut:
- Nama restoran:
.m-0.font-maison-bold - Jenis restoran:
.cusineTextButler
Saya akan melakukan scraping dengan cara membuat dua vectors (atau arrays) per data yang mau saya ambil lalu kemudian kedua vectors tersebut saya gabung menjadi satu dataframe.
url = "https://gofood.co.id/jakarta/restaurants"
nama_restoran =
read_html(url) %>%
html_nodes(".m-0.font-maison-bold") %>%
html_text()
jenis_restoran =
read_html(url) %>%
html_nodes(".cusineTextButler") %>%
html_text()
knitr::kable(data.frame(nama_restoran,jenis_restoran))
| nama_restoran | jenis_restoran |
|---|---|
| Kopi Batavia by Djournal Coffee, Yummykitchen Standard Chartered | Aneka nasi, Ayam & bebek |
| Pastellia, Yummykitchen Standard Chartered | Jajanan |
| Warteg Kharisma Bahari Kuningan, Prof Dr Satrio | Aneka nasi |
| Mannaya Coffee, Plaza Sentral | Sweets, Kopi, Minuman |
| Kwetiau Sapi Aciap, Prof Dr Satrio | Bakmie |
| McDonald’s, Plaza Sentral | Cepat saji, Sweets, Jajanan |
| Dapoe Aceh Melayu, Plaza Sentral | Aneka nasi |
| Siomay / Batagor Ikan Firman, Sudirman | Jajanan |
| Mie Ayam Uninga, Sudirman | Bakmie |
| Gule Kambing Widarno, Sudirman | Bakso & soto |
| Starbucks, Plaza Sentral | Kopi |
| Bakmi Naga, Sampoerna Square | Bakmie |
| Mie N Chicks, Professor Doktor Satrio | Bakso & soto, Aneka nasi, Bakmie |
| Lawson, Dr. Satrio | Jepang |
| Martabak Djuara, Kuningan | Martabak |
| Samakamu Kopi, Karet | Kopi |
| Pisang Goreng Krenyes OK Dr. Satrio | Jajanan |
| Nyapii - Sei Sapi Asap, Dr. Satrio Kuningan | Aneka nasi |
| Bakso Solo Samrat, Karet | Bakso & soto |
| Nasi Gila Bucin, Setiabudi | Aneka nasi, Ayam & bebek |
Contoh II: Cookpad
Contoh berikutnya misalkan saya hendak mengambil bahan-bahan yang digunakan untuk memasak tongseng kambing yang ada di situs cookpad berikut ini.
Saya akan mengambil tiga data, yakni:
- Judul masakan dengan css:
.field-group--no-container-xs. - User atau author dari resep ini dengan css:
.truncate. - Bahan masakah dengan css:
.border-dashed div.
Berbeda dengan contoh pertama, saya akan langsung buat data hasil scraping saya berbentuk dataframe.
url = "https://cookpad.com/id/resep/13602209-tongseng-kambing"
data =
read_html(url) %>% {
tibble(
judul_masakan = html_nodes(.,".field-group--no-container-xs") %>% html_text(),
author = html_nodes(.,".truncate") %>% html_text(),
bahan_masakan = html_nodes(.,".border-dashed div") %>% html_text()
)
}
knitr::kable(data)
| judul_masakan | author | bahan_masakan |
|---|---|---|
| Tongseng Kambing | Nindyta | Daging Kambing |
| Tongseng Kambing | Nindyta | 6 Siung Bawang Merah |
| Tongseng Kambing | Nindyta | 2 Siung Bawang Putih |
| Tongseng Kambing | Nindyta | Secukupnya Kubis |
| Tongseng Kambing | Nindyta | Cabai Rawit (sesuai selera) |
| Tongseng Kambing | Nindyta | Secukupnya Garam |
| Tongseng Kambing | Nindyta | Kecap Manis |
| Tongseng Kambing | Nindyta | Merica/Lada bubuk |
| Tongseng Kambing | Nindyta | Ketumbar |
| Tongseng Kambing | Nindyta | 1 buah Kemiri |
| Tongseng Kambing | Nindyta | secukupnya Air Putih |
| Tongseng Kambing | Nindyta | Kunyit |
Mengubah User Agent rvest
Sekarang saya akan menginformasikan bagaimana caranya mengubah user
agent di rvest. Caranya adalah dengan memanfaatkan library(httr)
dan menggunakan function user_agent() untuk mengubah default value
rvest ke browser lain.
Sebagai contoh, saya akan mengubah user agent menjadi
Chrome/54.0.2840.71.
uastring <- "Chrome/54.0.2840.71"
se <- html_session("https://httpbin.org/user-agent",httr::user_agent(uastring))
se$response$request$options$useragent
## [1] "Chrome/54.0.2840.71"
Apa sih manfaatnya?
Dengan mengubah user agent kita bisa mengakses situs yang dijaga oleh
robot.txtkarena mereka biasanya memblokir user agentlibcurlataucurl.
Tutorial library(chromote)
chromote memberikan sensasi mirip dengan RSelenium, yakni bekerja
dengan cara mimicking browser. Sesuai namanya, chromote merupakan
library untuk melakukan otomasi di Google Chrome namun kita bisa
memanfaatkannya untuk melakukan web scraping dengan menuliskan
sedikit javascript dalam algoritmanya.
Web Scraping Linkedin
Kali ini saya akan mencoba web scraping data dari Linkedin. Sebagai contoh, saya akan mengambil data yang simpel-simpel saja, yakni profil dari Sir Richard Branson di akun Linkedin-nya.
Cara kerja chromote adalah dengan membuka tab devtools di Google
Chrome sebagai berikut:
library(chromote)
url = "https://www.linkedin.com/in/rbranson/"
b <- ChromoteSession$new()
b$Network$setUserAgentOverride(userAgent = "Chrome Ikanx")
b$view()
cookies <- b$Network$getCookies()
b$Network$setCookies(cookies = cookies$cookies)
b$Page$navigate(url)
Sehingga akan muncul seperti ini:
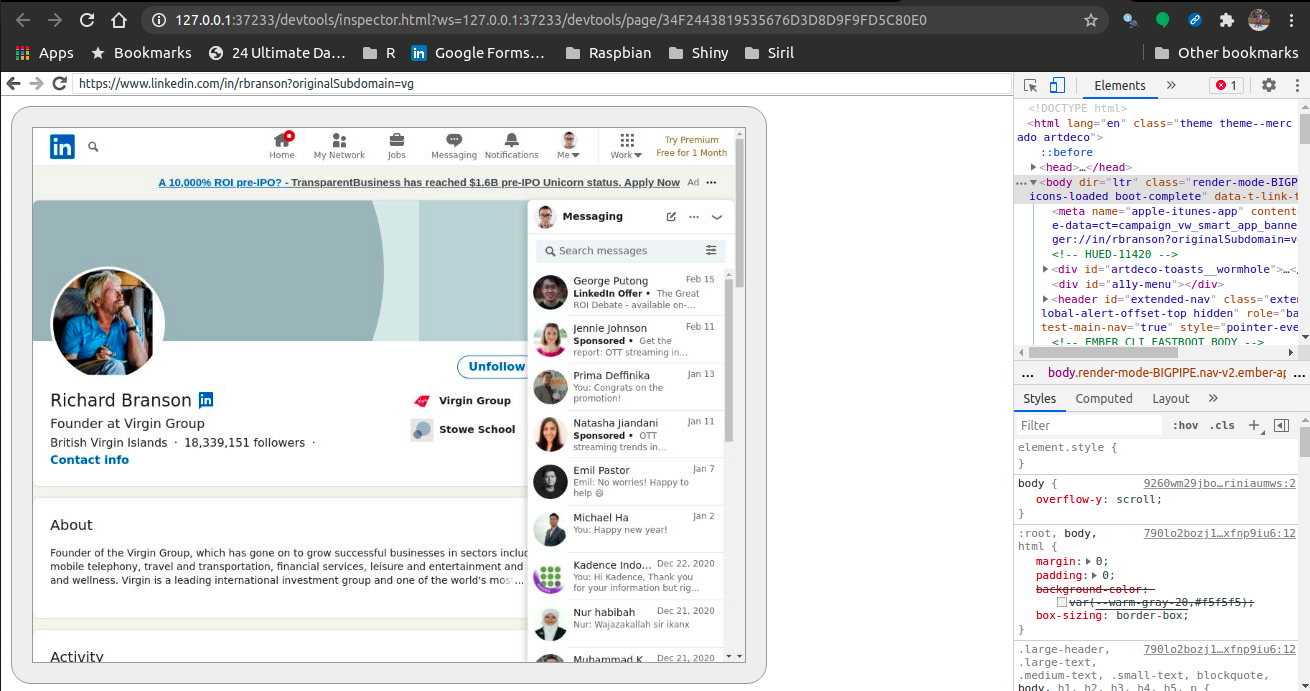
Untuk melakukan web scraping, saya tetap menggunakan css selector
untuk mendapatkan css object yang kemudian saya masukkan ke dalam
javascript seperti ini:
x = b$Runtime$evaluate('document.querySelector(".t-24").innerText')
nama = x$result$value
nama
## [1] "Richard Branson"
x = b$Runtime$evaluate('document.querySelector(".inline-block+ .t-normal").innerText')
follower = x$result$value
follower
## [1] "18,339,151 followers "
x = b$Runtime$evaluate('document.querySelector(".t-18").innerText')
job = x$result$value
job
## [1] "Founder at Virgin Group"
Bagaimana? Any comments?
if you find this article helpful, support this blog by clicking the
ads.