
Membuat Algoritma Rekomendasi dari Nol
Semalam, saya dan istri bercerita bahwa di salah satu boarding school yang kami incar untuk si Sulung memberikan Macbook kepada para siswanya sebagai daily driver di sekolah. Karena penasaran dengan harganya, saya coba Googling terkait Macbook.
Tiba-tiba pagi ini, iklan-iklan yang muncul di gadget saya dipenuhi bukan hanya iklan Macbook, tapi juga aksesoris iPad (kebetulan saya juga pengguna iPad).
Saya rasa rekan-rekan semua pasti pernah mengalami saat membeli charger HP, lalu tiba-tiba kalian malah membeli juga casing, kabel data, dan powerbank? Atau saat kalian membuka Netflix untuk nonton satu film, tapi berakhir marathon tiga film atau series karena rekomendasi berikutnya selalu tepat sasaran?
Di dunia digital dimana data bisa ditambang dari user secara tak disadari, rekomendasi-rekomendasi itu bukan kebetulan belaka. Di balik setiap rekomendasi itu ada algoritma yang bekerja dan algoritma itu jauh lebih sederhana dari yang kita bayangkan.
Tidak ada sihir, tidak ada AI yang “membaca pikiran”. Fondasinya hanyalah satu premis sederhana, yakni:
Orang yang berperilaku serupa di masa lalu cenderung menyukai hal yang serupa di masa depan. Lalu produk yang sering dibeli bersama-sama kemungkinan besar saling melengkapi.
Di tulisan ini, saya akan membangun sistem rekomendasi dari nol menggunakan R tanpa library khusus yang menyembunyikan mekanismenya. Kita akan mencoba memahami cara kerja sistem rekomendasi melalui dua pendekatan utama:
- User-Based Collaborative Filtering dan
- Item-Based Collaborative Filtering.
Kemudian saya akan coba bandingkan keduanya.
Studi kasusnya: data transaksi toko online FMCG fiktif untuk produk-produk seperti minuman, snack, dan produk perawatan diri. Tentunya pendekatan ini bisa langsung diaplikasikan ke konteks e-commerce atau modern trade. Oke, saya mulai ya.
Beberapa Pendekatan Sistem Rekomendasi
Sebelum masuk ke algoritma, saya akan coba paparkan terlebih dahulu 2 + 1 pendekatan yang bisa digunakan untuk membangun sistem rekomendasi:
| Pendekatan | Ide Dasar | Contoh Penggunaan |
|---|---|---|
| Content-Based Filtering | Rekomendasikan produk yang mirip dengan yang sudah dibeli/disukai user, berdasarkan atribut produk | Spotify merekomendasikan lagu dengan genre dan tempo serupa |
| Collaborative Filtering | Rekomendasikan berdasarkan kesamaan perilaku antar user atau antar item | Netflix: “User seperti kamu juga menonton film ini” |
| Hybrid | Gabungan antara konten dan perilaku | Amazon |
Di tulisan ini saya hanya fokus ke Collaborative Filtering karena lebih bergantung pada data transaksi yang biasanya sudah tersedia dan tidak butuh deskripsi atribut produk yang lengkap. Collaborative Filtering sendiri punya dua variasi:
- User-Based CF: Cari user yang mirip dengan target user, lalu rekomendasikan apa yang mereka beli tapi target user belum beli.
- Item-Based CF: Cari item yang sering dibeli bersama dengan item yang sudah dibeli target user, lalu rekomendasikan item tersebut.
Mana yang Lebih Baik?
Item-Based CF umumnya lebih stabil dan lebih mudah di-upscale di dunia nyata karena hubungan antar produk lebih konsisten dibanding preferensi antar user. Netflix sendiri beralih dari User-Based ke Item-Based di awal 2000-an karena alasan ini. Tapi keduanya tetap relevan dan kita akan buat algoritma keduanya.
Matematika di Balik Sistem Rekomendasi
Di beberapa kesempatan, saat saya kembali ke kampus untuk sharing kepada mahasiswa, saya sering bilang bahwa:
Dunia ini dijalankan melalui aljabar.
Salah satu aplikasi aljabar yang nyata adalah sistem rekomendasi yang menggunakan prinsip matriks dalam aljabar.
Semua Collaborative Filtering bekerja di atas satu struktur data yang disebut User-Item Matrix. Baris menandakan user, Kolom menandakan item atau produk, dan Nilai menandakan rating dari produk tersebut atau jumlah pembelian.
Coba lihat contoh ilustrasi matriks berikut ini:
Teh Botol Indomie Oreo Pocari Pringles
Andi 3 1 0 2 0
Budi 0 2 3 0 2
Citra 2 0 1 3 0
Dewi 0 3 2 0 3
Angka 0 berarti belum pernah beli (atau rating tidak diketahui). Ini disebut sparse matrix karena mayoritas nilainya 0. Pada kondisi real di e-commerce, seorang user mungkin hanya pernah beli 0.1% dari semua produk yang tersedia.
Beberapa tahun yang lalu, saya sempat menuliskan tentang kemiripan sepasang data. Salah satu metode untuk mengukur kemiripan adalah menggunakan cosine simmilarity. Kunci dari Collaborative Filtering adalah mengukur seberapa mirip dua user atau dua item menggunakan cosine simmilarity.
Secara teknis, saya memperlakukan histori pembelian setiap user sebagai sebuah vektor di ruang N-dimensi (N = jumlah produk). Dua users disebut mirip kalau vektor mereka menunjuk ke arah yang sama (maksudnya adalah mereka beli produk yang sama dalam proporsi yang serupa).
Lift dan Support: Cara Alternatif untuk Item-Based CF
Untuk Item-Based CF, ada metode yang lebih populer yang bisa digunakan, yakni: association rules (Market Basket Analysis). Dua metrics penting yang bisa didapatkan dari analisa ini adalah:
Support(A → B), artinya P(A dan B dibeli bersama). Jumlah transaksi yang berisi A dan B per total transaksi. Seberapa sering keduanya (A dan B) muncul bersamaan.Lift(A → B) = P(A dan B) / (P(A) × P(B)). Nilailift > 1berarti produk A dan B lebih sering ditemui bersama dari yang diharapkan secara acak (ada asosiasi positif yang nyata). Begitu pula sebaliknya,lift < 1berarti produk A dan B jarang ditemui bersama.
Memulai Simulasi
Membuat Katalog Produk
Pertama-tama, saya akan membuat katalog produk berisi:
Jumlah produk dalam katalog: 30
kategori n
1 Minuman 10
2 Perawatan Diri 10
3 Snack 10
Ini sampel katalog produknya:
item_id nama_item kategori harga
9 9 Good Day RTD Minuman 7000
14 14 Chitato Sapi Panggang Snack 15000
23 23 Sunsilk Shampoo Perawatan Diri 18000
25 25 Vaseline Lotion Perawatan Diri 20000
Membuat Simulasi Transaksi
Selanjutnya saya akan membuat 500 orang users dengan masing-masing 5-20 transaksi. Agar realistis, saya akan tanamkan polas asosiasi secara eksplisit pada algoritma simulasinya. Misalkan: “Indomie sering dibeli bersamaan degan Teh Botol atau sabun sering dibeli bersamaan dengan shampoo”.
Total baris transaksi: 19432
Jumlah transaksi unik: 6218
Jumlah user: 500
Rata-rata item per transaksi: 3.13
Berikut adalah beberapa sampel transaksinya:
[1] user_id transaksi_id item_id nama_item kategori
[6] harga
<0 rows> (or 0-length row.names)
user_id transaksi_id item_id nama_item kategori harga
1 81 T0081_04 4 Sprite 390ml Minuman 5000
2 81 T0081_04 5 Kopi Kapal Api Minuman 2500
3 81 T0081_04 8 Yakult 5pcs Minuman 12000
user_id transaksi_id item_id nama_item kategori harga
1 78 T0078_01 17 Choki-Choki Snack 1000
2 78 T0078_01 10 Milo RTD Minuman 7000
3 78 T0078_01 1 Teh Botol 500ml Minuman 5500
4 78 T0078_01 2 Aqua 600ml Minuman 3000
5 78 T0078_01 10 Milo RTD Minuman 7000
6 78 T0078_01 11 Indomie Goreng Snack 3500
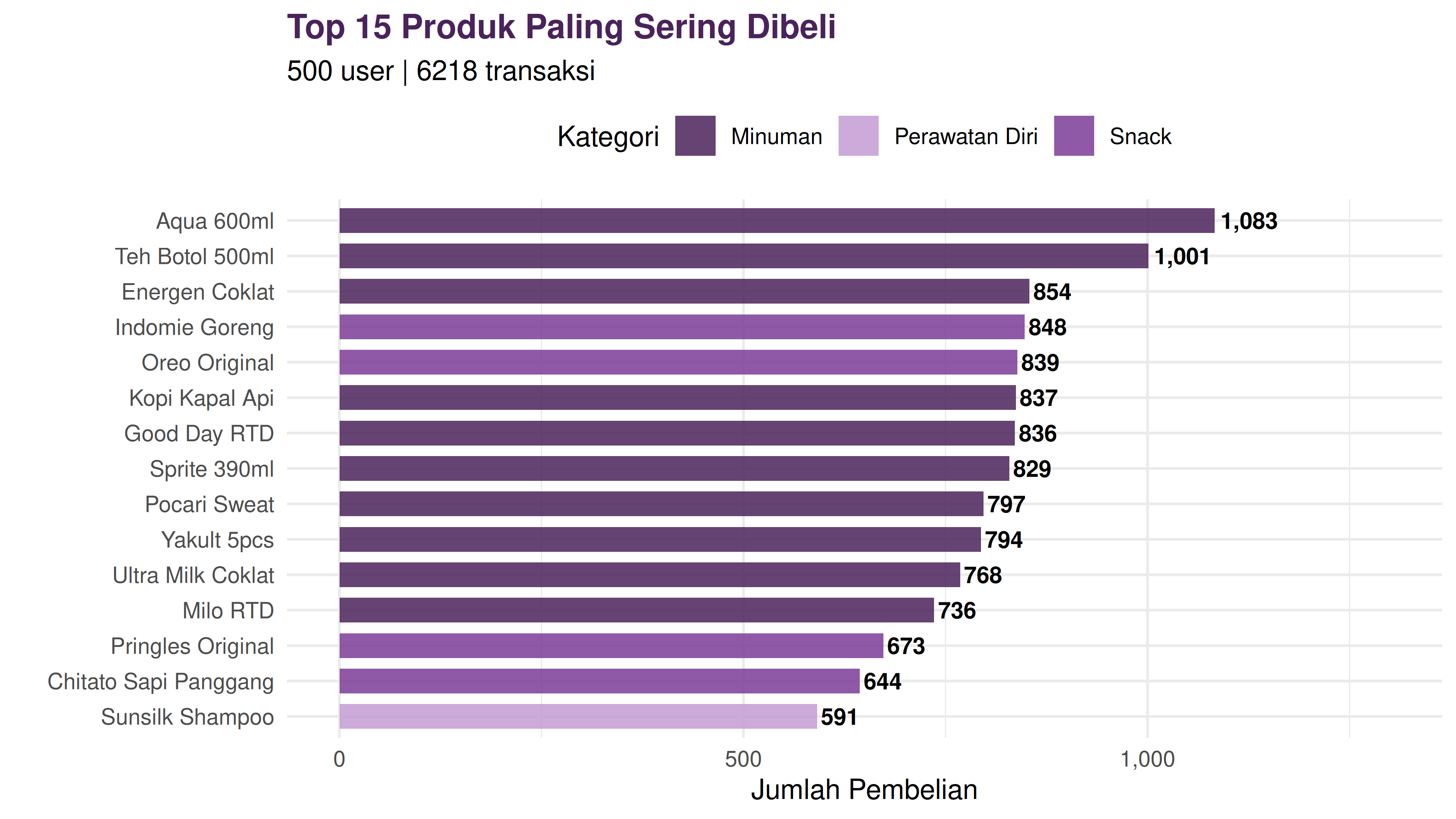
Berikut ini adalah visualisasi dari top 15 produk yang paling sering dibeli:
Membangun User-Item Matrix
Dimensi User-Item Matrix: 500 30
( 500 user x 30 item)
Sparsity matrix: 30.9 %
Ini adalah sampelnya:
# A tibble: 4 × 31
user_id `3` `4` `5` `7` `9` `10` `15` `21` `23` `24` `25`
<int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
1 9 2 2 0 2 2 1 0 1 0 0 3
2 14 0 1 2 1 1 0 1 0 1 0 3
3 23 2 2 3 5 0 2 0 2 2 0 0
4 25 1 3 3 2 0 1 1 3 1 0 1
# ℹ 19 more variables: `29` <int>, `1` <int>, `2` <int>, `6` <int>, `8` <int>,
# `11` <int>, `12` <int>, `13` <int>, `16` <int>, `17` <int>, `18` <int>,
# `20` <int>, `22` <int>, `26` <int>, `27` <int>, `28` <int>, `14` <int>,
# `30` <int>, `19` <int>
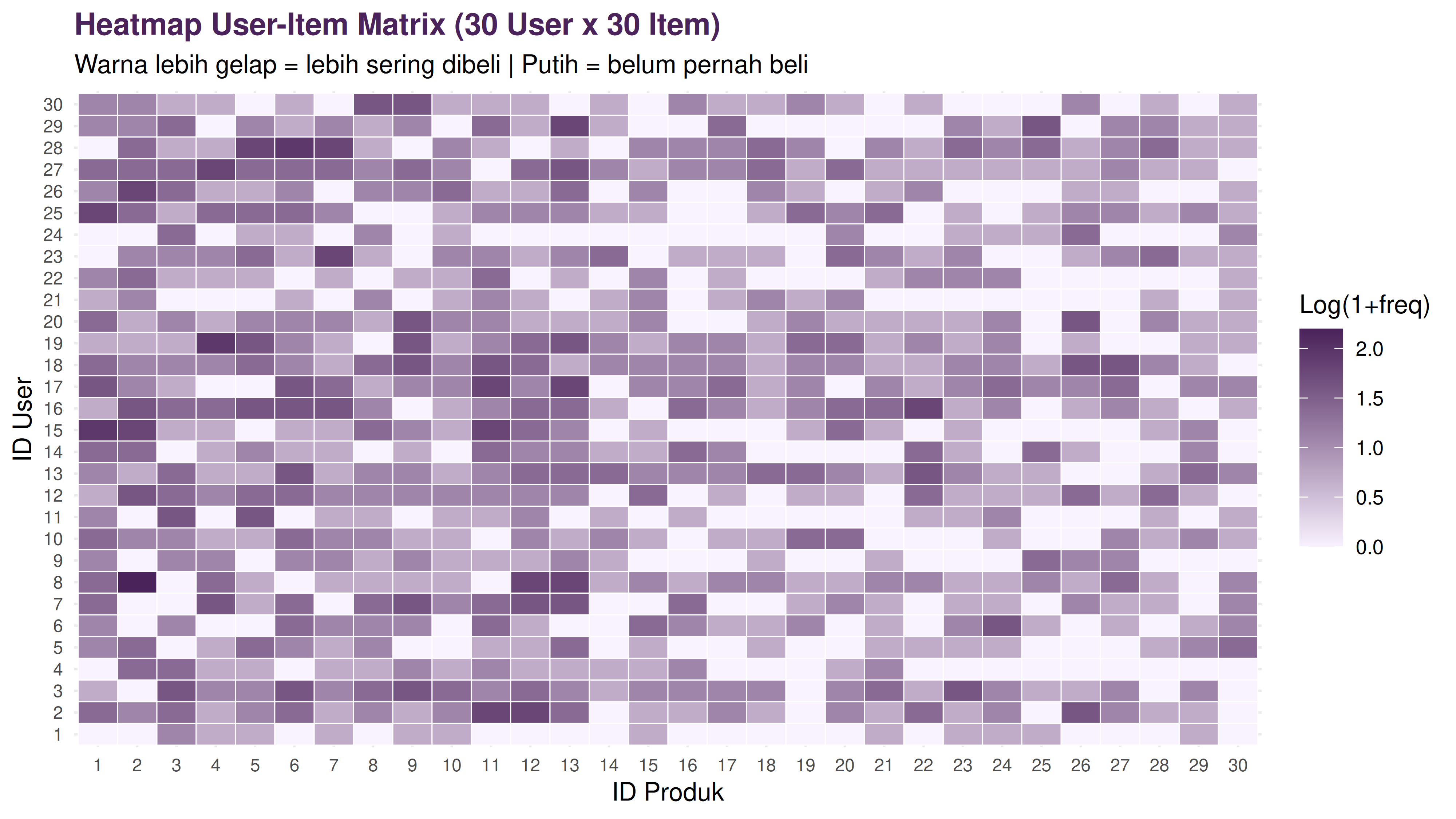
Jika saya buat heatmap dari matrix tersebut, begini bentuknya:
User-Based Collaborative Filtering
Hitung Cosine Similarity Antar User
Pertama-tama, saya akan menghitung kesamaan antar user dan membuat simmilarity matrix.
Dari matrix itu, saya bisa mengecek user mana yang paling mirip dengan user 1.
Menghitung user similarity matrix...
Dimensi user similarity matrix: 500 500
Top 5 user paling mirip dengan User 1:
290 3 203 248 44
0.7365895 0.7212280 0.7202966 0.7172191 0.7045639
Fungsi Rekomendasi User-Based
Dari data-data di atas, saya akan membuat function untuk memberikan rekomendasi produk apa saja yang bisa ditawarkan kepada user 1
# ── Fungsi rekomendasi User-Based CF ─────────────────────────────
rekomendasi_user_based <- function(target_user,
n_neighbor = 20,
n_rekomendasi = 5) {
# 1. Temukan N user paling mirip (neighbor)
sim_scores <- user_sim_matrix[as.character(target_user), ]
top_neighbor <- names(sort(sim_scores, decreasing = TRUE))[1:n_neighbor]
# 2. Item yang sudah dibeli target user
sudah_dibeli <- which(mat_ui[as.character(target_user), ] > 0)
# 3. Hitung skor rekomendasi: weighted sum of neighbor ratings
# Bobot = similarity score neighbor tersebut
skor_item <- rep(0, ncol(mat_ui))
names(skor_item) <- colnames(mat_ui)
for (neighbor in top_neighbor) {
sim_w <- sim_scores[neighbor]
# Tambahkan weighted rating dari neighbor
skor_item <- skor_item + sim_w * mat_ui[neighbor, ]
}
# 4. Nolkan item yang sudah pernah dibeli target user
skor_item[sudah_dibeli] <- 0
# 5. Ambil top N rekomendasi
top_items <- sort(skor_item, decreasing = TRUE)[1:n_rekomendasi]
data.frame(
item_id = as.integer(names(top_items)),
skor_ub = as.numeric(top_items)
) %>%
left_join(katalog, by = 'item_id') %>%
select(item_id, nama_item, kategori, harga, skor_ub)
}
Berikut adalah histori pembelian untuk user 1:
=== HISTORI PEMBELIAN USER 1 ===
nama_item kategori n
1 Pocari Sweat Minuman 2
2 Deterjen Attack Perawatan Diri 1
3 Good Day RTD Minuman 1
4 Kopi Kapal Api Minuman 1
5 Lifebuoy Sabun Perawatan Diri 1
6 Milo RTD Minuman 1
7 Rexona Deodorant Perawatan Diri 1
8 Roma Marie Snack 1
9 Sprite 390ml Minuman 1
10 Sunsilk Shampoo Perawatan Diri 1
11 Ultra Milk Coklat Minuman 1
12 Vaseline Lotion Perawatan Diri 1
Dan berikut ini adalah produk yang bisa direkomendasikan kepada user 1:
=== REKOMENDASI USER-BASED CF UNTUK USER 1 ===
item_id nama_item kategori harga skor_ub
1 12 Oreo Original Snack 8500 20.40432
2 8 Yakult 5pcs Minuman 12000 19.24507
3 14 Chitato Sapi Panggang Snack 15000 18.50356
4 6 Energen Coklat Minuman 6500 18.46504
5 2 Aqua 600ml Minuman 3000 17.62897
Item-Based Collaborative Filtering
Hitung Cosine Similarity Antar Item
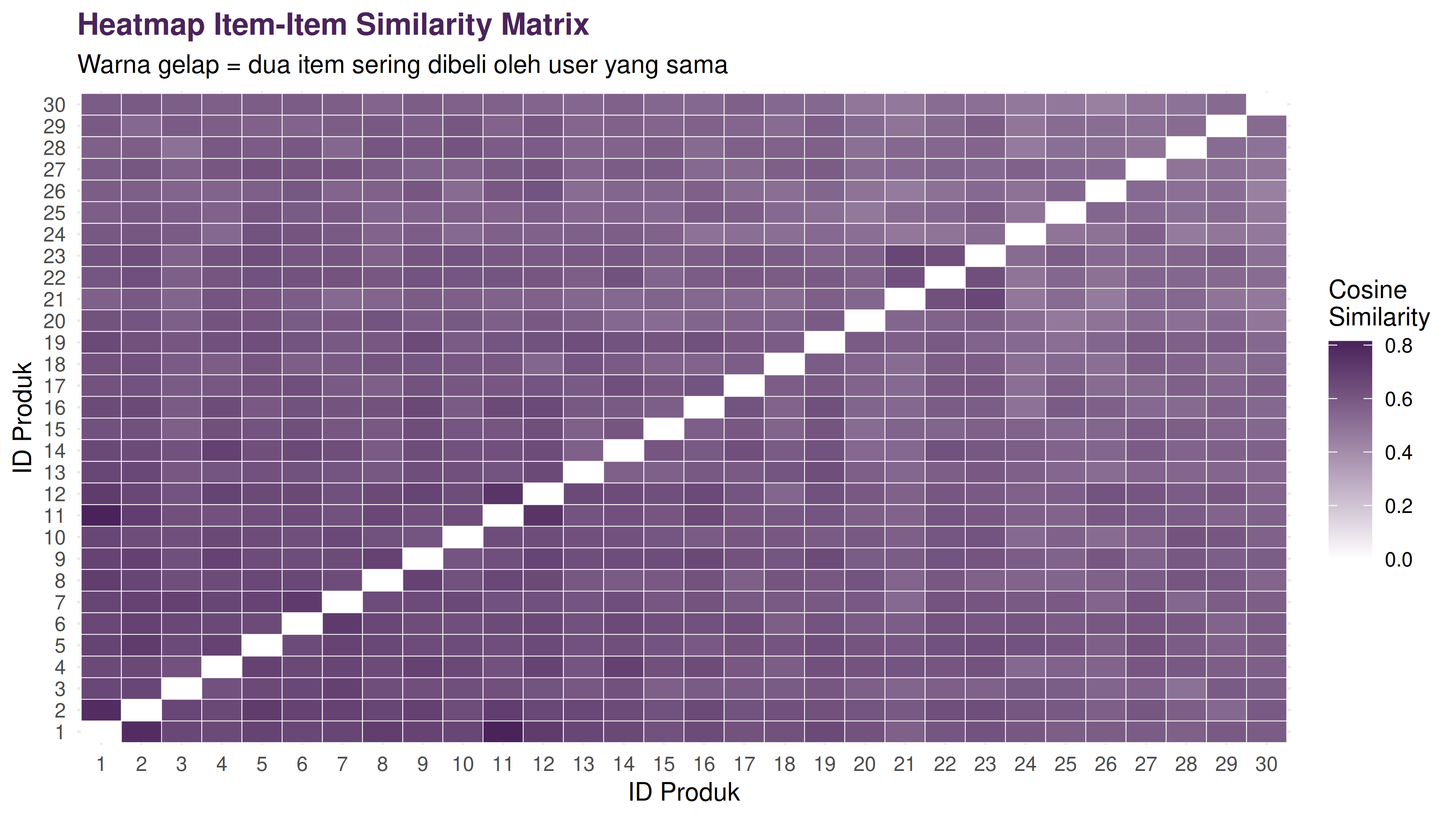
Berbeda dengan bagian sebelumnya, sekarang saya akan menghitung kebalikan POV. Yakni dengan menghitung antar item. Selanjutnya akan disimpan sebagai simmilarity matrix per item.
Dimensi item similarity matrix: 30 30
Fungsi Rekomendasi Item-Based
Berdasarkan matrix tersebut, saya bisa membuat function untuk mengeluarkan item rekomendasi dengan sudut pandang item-based.
# ── Fungsi rekomendasi Item-Based CF ─────────────────────────────
rekomendasi_item_based <- function(target_user,
n_rekomendasi = 5) {
# 1. Item yang sudah dibeli target user
profil_user <- mat_ui[as.character(target_user), ]
sudah_dibeli <- which(profil_user > 0)
belum_dibeli <- which(profil_user == 0)
if (length(sudah_dibeli) == 0) {
cat('User belum punya histori pembelian.\n')
return(NULL)
}
# 2. Untuk setiap item yang belum dibeli, hitung skor:
# skor(item_baru) = sum(sim(item_baru, item_lama) * frekuensi_beli)
skor_item <- sapply(belum_dibeli, function(target_item) {
sim_ke_sudah_dibeli <- item_sim_matrix[
as.character(target_item),
as.character(sudah_dibeli)
]
sum(sim_ke_sudah_dibeli * profil_user[sudah_dibeli])
})
names(skor_item) <- belum_dibeli
# 3. Ambil top N
top_items <- sort(skor_item, decreasing = TRUE)[1:n_rekomendasi]
data.frame(
item_id = as.integer(names(top_items)),
skor_ib = as.numeric(top_items)
) %>%
left_join(katalog, by = 'item_id') %>%
select(item_id, nama_item, kategori, harga, skor_ib)
}
Berikut adalah rekomendasi untuk user 1:
=== REKOMENDASI ITEM-BASED CF UNTUK USER 1 ===
item_id nama_item kategori harga skor_ib
1 14 Chitato Sapi Panggang Snack 15000 8.364571
2 13 Pringles Original Snack 25000 8.250580
3 16 Khong Guan Assorted Snack 35000 8.222321
4 19 Richoco Snack 2000 8.126354
5 15 Roma Marie Snack 8000 8.054033
Market Basket Analysis: “Juga Sering Dibeli Bersama”
Di luar Collaborative Filtering berbasis user, ada pendekatan lain yang sangat intuitif dan langsung actionable, yakni Market Basket Analysis. Saya pernah mengulas metode ini di blog saya yang lama. Ini yang menghasilkan fitur “Frequently Bought Together” di Amazon atau “Orang juga membeli” di beberapa e-commerce lokal.
Menghitung Support dan Lift
Metodenya adalah dengan menghitung nilai support dan lift.
Total transaksi unik: 6218
Menghitung support dan lift untuk semua pasangan item...
=== TOP 15 PASANGAN PRODUK DENGAN LIFT TERTINGGI ===
nama_A nama_B n_bersama support lift
1 Sunsilk Shampoo Lifebuoy Sabun 159 0.0256 3.879
2 Indomie Goreng Teh Botol 500ml 450 0.0724 3.358
3 Lifebuoy Sabun Pepsodent 190gr 124 0.0199 3.269
4 Indomie Goreng Oreo Original 266 0.0428 2.402
5 Teh Botol 500ml Aqua 600ml 334 0.0537 2.010
6 Sunsilk Shampoo Pepsodent 190gr 99 0.0159 1.911
7 Sprite 390ml Chitato Sapi Panggang 149 0.0240 1.784
8 Ultra Milk Coklat Energen Coklat 179 0.0288 1.720
9 Softex 10pcs Tisu Paseo 200lbr 53 0.0085 1.690
10 Good Day RTD Yakult 5pcs 167 0.0269 1.680
11 Oreo Original Pringles Original 139 0.0224 1.590
12 Ultra Milk Coklat Pocari Sweat 135 0.0217 1.420
13 Ultra Milk Coklat Sprite 390ml 137 0.0220 1.378
14 Choki-Choki Tisu Paseo 200lbr 57 0.0092 1.274
15 Teh Botol 500ml Oreo Original 163 0.0262 1.264
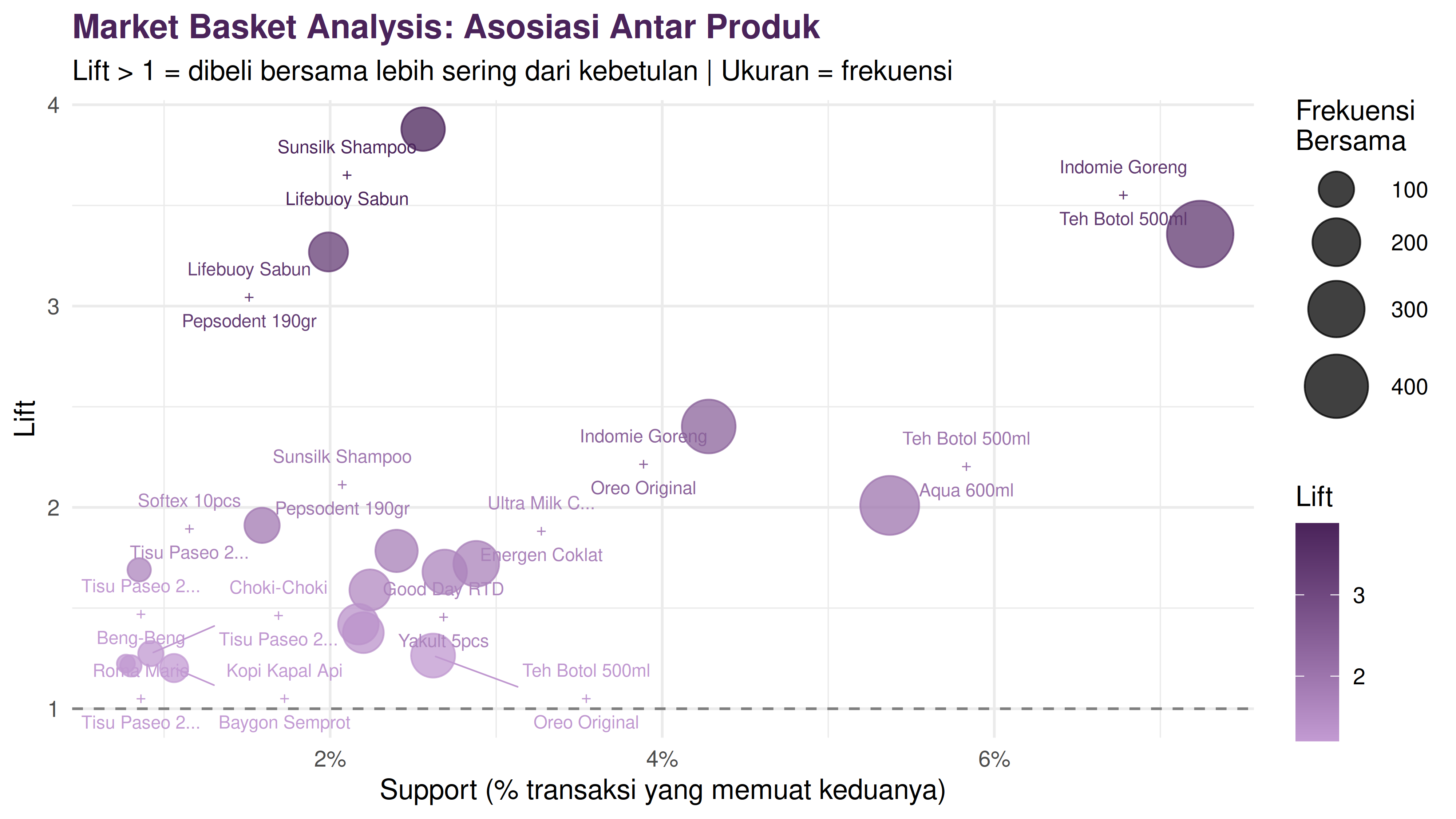
Berikut adalah visualisasi untuk pasangan produk yang memiliki nilai
lift > 1.
Rekomendasi “Juga Sering Dibeli Bersama” per Produk
Dari perhitungan lift tersebut, saya bisa membuat function rekomendasi produk apa yang bisa ditawarkan saat user membeli produk tertentu.
# ── Fungsi: rekomendasi 'frequently bought together' ─────────────
rekomendasi_fbt <- function(nama_produk, n_rek = 5, lift_min = 1.0) {
# Temukan item_id dari nama produk
id_target <- katalog %>%
filter(grepl(nama_produk, nama_item, ignore.case = TRUE)) %>%
pull(item_id)
if (length(id_target) == 0) {
cat('Produk tidak ditemukan.\n'); return(NULL)
}
# Cari semua pasangan yang melibatkan produk ini
df_rek <- df_asosiasi %>%
filter((item_A %in% id_target | item_B %in% id_target),
lift >= lift_min) %>%
mutate(
item_partner = ifelse(item_A %in% id_target, item_B, item_A),
nama_partner = ifelse(item_A %in% id_target, nama_B, nama_A)
) %>%
filter(!item_partner %in% id_target) %>%
arrange(desc(lift)) %>%
select(nama_partner, n_bersama, support, lift) %>%
head(n_rek)
cat('=== Sering Dibeli Bersama:', toupper(nama_produk), '===\n')
print(df_rek)
invisible(df_rek)
}
Berikut ini adalah contoh produk yang rekomendasikan jika user membeli produk:
rekomendasi_fbt('Indomie')
=== Sering Dibeli Bersama: INDOMIE ===
nama_partner n_bersama support lift
1 Teh Botol 500ml 450 0.0724 3.358
2 Oreo Original 266 0.0428 2.402
3 Aqua 600ml 161 0.0259 1.128
rekomendasi_fbt('Lifebuoy')
=== Sering Dibeli Bersama: LIFEBUOY ===
nama_partner n_bersama support lift
1 Sunsilk Shampoo 159 0.0256 3.879
2 Pepsodent 190gr 124 0.0199 3.269
3 Richoco 42 0.0068 1.134
rekomendasi_fbt('Teh Botol')
=== Sering Dibeli Bersama: TEH BOTOL ===
nama_partner n_bersama support lift
1 Indomie Goreng 450 0.0724 3.358
2 Aqua 600ml 334 0.0537 2.010
3 Oreo Original 163 0.0262 1.264
Evaluasi Model: Seberapa Bagus Rekomendasi Kita?
Business question yang kemudian muncul dan perlu dijawab adalah: “Seberapa bagus sistem rekomendasi yang kita buat?”
Sistem rekomendasi yang sudah jadi tetap perlu dievaluasi secara kuantitatif. Metode standar yang bisa digunakan adalah dengan membagi data menjadi train dan test, sembunyikan sebagian histori pembelian user di test set, lalu ukur apakah rekomendasi berhasil memprediksi item yang disembunyikan itu
Metrics yang bisa digunakan adalah precision@K dan recall@K.
Precision@K berarti: “Dari K item yang direkomendasikan, berapa banyak yang relevan?”
Contoh: Sistem merekomendasikan 10 film (K=10) kepada user:
- User sebenarnya menyukai 4 film dari 10 itu.
- Precision@10 = 4/10 = 0.4 (40%).
- 40% dari rekomendasi top-10 adalah relevan.
Recall@K. berarti: “Dari semua item yang relevan untuk user, berapa banyak yang muncul di K rekomendasi teratas?”
Contoh: User memiliki 20 film favorit di database:
- Sistem merekomendasikan 10 film (
K=10). - Sebanyak 4 Dari 10 film itu adalah film favorit user.
- Recall@10 = 4/20 = 0.2 (20%).
- Sistem berhasil menemukan 20% dari film favorit user dalam 10 rekomendasi teratas.
Precision@K adalah tentang membuat user happy dengan apa yang mereka lihat, Recall@K adalah tentang menemukan semua yang bisa membuat user happy.”
Saya akan hitung precision@5 dan recall@5 dari rekomendasi item-based CF.
Mengevaluasi model...
=== HASIL EVALUASI (Item-Based CF, K=5) ===
Precision@5: 0.3112
Recall@5 : 0.3565
Interpretasi Precision@5 = 0.XX:
Rata-rata ada X dari 5 rekomendasi yang benar-benar dibeli user
Artinya: Dari 5 rekomendasi teratas yang diberikan sistem:
- Hanya 1.56 item (rata-rata) yang relevan untuk user.
- 3.44 item lainnya tidak relevan.
Dalam bahasa sederhana: “Hanya 31% dari 5 rekomendasi utama yang benar-benar disukai user.”
- Recall@5 = 35.65%
Artinya: Dari semua item yang sebenarnya relevan untuk user:
- Sistem hanya berhasil menemukan 35.65% dalam 5 rekomendasi teratas.
- 64.35% item relevan lainnya terlewatkan.
Dalam bahasa sederhana: “Sistem hanya menemukan 36% dari semua item yang user sukai.”
Oke, jadi sekarang kita sudah memiliki metrics yang cukup untuk memutuskan apakah sistem rekomendasi yang kita buat sudah baik atau belum.
Membandingkan Rekomendasi User-Based vs Item-Based
Sekarang saya akan bandingkan hasil rekomendasi antara user-based dengan item-based:
Kita bandingkan hasil untuk user 1:
=======================================================
USER: 1
=======================================================
HISTORI PEMBELIAN:
nama_item n
1 Pocari Sweat 2
2 Deterjen Attack 1
3 Good Day RTD 1
4 Kopi Kapal Api 1
5 Lifebuoy Sabun 1
REKOMENDASI USER-BASED CF:
nama_item kategori skor_ub
1 Oreo Original Snack 20.40432
2 Yakult 5pcs Minuman 19.24507
3 Chitato Sapi Panggang Snack 18.50356
4 Energen Coklat Minuman 18.46504
5 Aqua 600ml Minuman 17.62897
REKOMENDASI ITEM-BASED CF:
nama_item kategori skor_ib
1 Chitato Sapi Panggang Snack 8.364571
2 Pringles Original Snack 8.250580
3 Khong Guan Assorted Snack 8.222321
4 Richoco Snack 8.126354
5 Roma Marie Snack 8.054033
Overlap (rekomendasi dari keduanya): 1 item
Chitato Sapi Panggang
Kita bandingkan hasil untuk user 42:
=======================================================
USER: 42
=======================================================
HISTORI PEMBELIAN:
nama_item n
1 Aqua 600ml 3
2 Lifebuoy Sabun 3
3 Energen Coklat 2
4 Good Day RTD 2
5 Oreo Original 2
REKOMENDASI USER-BASED CF:
nama_item kategori skor_ub
1 Teh Botol 500ml Minuman 23.87841
2 Pringles Original Snack 21.78656
3 Kopi Kapal Api Minuman 19.52340
4 Yakult 5pcs Minuman 17.98266
5 Indomie Goreng Snack 17.33572
REKOMENDASI ITEM-BASED CF:
nama_item kategori skor_ib
1 Oreo Original Snack 19.73584
2 Pocari Sweat Minuman 19.14616
3 Richoco Snack 18.71345
4 Pringles Original Snack 18.61522
5 Khong Guan Assorted Snack 18.52100
Overlap (rekomendasi dari keduanya): 1 item
Pringles Original
Kita bandingkan hasil untuk user 137:
=======================================================
USER: 137
=======================================================
HISTORI PEMBELIAN:
nama_item n
1 Oreo Original 5
2 Good Day RTD 4
3 Khong Guan Assorted 4
4 Sprite 390ml 4
5 Vaseline Lotion 4
REKOMENDASI USER-BASED CF:
nama_item kategori skor_ub
1 Teh Botol 500ml Minuman 24.95373
2 Pringles Original Snack 18.63394
3 Deterjen Attack Perawatan Diri 15.57189
4 Tisu Paseo 200lbr Perawatan Diri 14.12167
5 Rexona Deodorant Perawatan Diri 12.49974
REKOMENDASI ITEM-BASED CF:
nama_item kategori skor_ib
1 Oreo Original Snack 29.58868
2 Milo RTD Minuman 29.03123
3 Pringles Original Snack 28.29720
4 Richoco Snack 28.26768
5 Pepsodent 190gr Perawatan Diri 27.89602
Overlap (rekomendasi dari keduanya): 1 item
Pringles Original
Seberapa besar perbedaannya? Secara rata-rata:
=== RATA-RATA OVERLAP UB vs IB REKOMENDASI ===
Rata-rata: 26.3 %
(dari top-10 rekomendasi, rata-rata 2.6 item sama antara UB dan IB)
Bagaimana Jika Cold Start?
Salah satu kelemahan terbesar Collaborative Filtering adalah cold start problem: apa yang terjadi kalau user baru yang belum punya histori pembelian sama sekali datang? Atau produk baru yang belum pernah dibeli siapapun?
Beberapa alternatif strategi yang bisa langsung diimplementasikan:
- Strategi 1: popularitas global, kita rekomendasikan saja semua produk yang paling populer.
- Strategi 2: popularitas per segmen. Misalkan user baru dari Bekasi dan umur 25-35 maka rekomendasikan produk terpopuler di segmen itu. Artinya kita membutuhkan data demografis.
- Strategi 3: sabar menunggu hingga user baru membeli satu produk. Rekomendasi berbasis satu produk pertama yang dibeli kemudian bisa dilanjutkan menggunakan Market Basket Analysis.
Business Action dari Algoritma
Ada tiga cara mengimplementasikan algoritma sistem rekomendasi, yakni:
- Cross-selling di halaman produk. Pasang widget ‘Sering Dibeli Bersama’ di halaman detail produk. Gunakan hasil Market Basket Analysis (lift tertinggi) sebagai datanya. Ini bisa langsung diimplementasikan tanpa sistem real-time.
- Email/push notification personal. Setiap minggu, jalankan Item-Based CF untuk semua user aktif. Kirim notifikasi ‘Produk yang mungkin kamu suka’ berdasarkan histori pembelian mereka. Sederhana tapi efektif.
- Planogram dan bundling. Pasang produk dengan lift tinggi berdekatan di rak toko fisik atau halaman kategori. Buat bundle package dari pasangan dengan support dan lift tertinggi.
Keterbatasan yang Perlu Diperhatikan
- Scalability. Algoritma di atas menggunakan full matrix multiplication. Kondisi ini bagus untuk ratusan user dan puluhan item. Untuk jutaan user, dibutuhkan approximate nearest neighbor (ANN) atau matrix factorization (SVD, ALS) yang jauh lebih efisien secara komputasi.
- Popularity bias. Algoritma berbasis frekuensi cenderung merekomendasikan item populer terus-menerus. Produk niche yang sebenarnya sangat relevan untuk segmen tertentu bisa terus tersembunyi. Solusi: normalisasi skor atau tambahkan exploration factor.
- Data sparsity. Semakin jarang user berinteraksi dengan produk, semakin sulit menemukan user yang benar-benar ‘mirip’. Di tahap awal, Market Basket Analysis (tidak membutuhkan histori panjang) lebih robust.
- Temporal dynamics. Preferensi berubah seiring waktu. Pembelian 2 tahun lalu tidak selalu relevan hari ini. Solusi: beri bobot lebih tinggi ke transaksi yang lebih baru (time-decay weighting).
- Tidak menangkap konteks. Membeli minuman dingin di musim panas berbeda konteksnya dengan di musim hujan. Collaborative Filtering murni tidak menangkap konteks ini. Oleh karena itu, dibutuhkan Contextual Bandits atau session-based recommendation.
if you find this article helpful, support this blog by clicking the ads.